Linux内存管理 —— 内核态和用户态的内存分配方式
1. 使用buddy系统管理ZONE
我的这两篇文章buddy系统和slab分配器已经分析过buddy和slab的原理和源码,因此一些细节不再赘述。
所有zone都是通过buddy系统管理的,buddy system由Harry Markowitz在1963年提出。buddy的工作方式我就不说了,简单来说buddy就是用来管理内存的使用情况:一个页被申请了,别人就不能申请了。通过/proc/buddyinfo可以查看buddy的内存余量。
由于buddy是zone里面的一个成员,所以每个zone都有自己的buddy系统来管理自己的内存(因此,buddy管理的也是物理内存哦)。
➜ vdbench cat /proc/buddyinfo
Node , zone DMA
Node , zone DMA32
Node , zone Normal
buddy的问题就是容易碎掉,即没有大块连续内存。对应用程序和内核非线性映射没有影响,因为有MMU和页表,但DMA不行,DMA engine里面没有MMU,一致性映射后必须是连续内存。
可以通过alloc_pages(gfp_mask, order)从buddy里面申请内存,申请内存大小都是2^order个页的大小,这样显然是不满足实际需求的。因此,基于buddy,slab(或slub/slob)对内存进行了二次管理,使系统可以申请小块内存。
Slab先从buddy拿到数个页的内存,然后切成固定的小块(称为object),再分配出去。从/proc/slabinfo中可以看到系统内有很多slab,每个slab管理着数个页的内存,它们可分为两种:一个是各模块专用的,一种是通用的。
在内核中常用的kmalloc就是通过slab拿的内存,它向通用的slab里申请内存。我们也就知道,kmalloc只能分配一个对象的大小,比如你想分配40B,实际上是分配了64B。在include/linux/kmalloc_sizes.h可以看到通用cache的大小都有哪些:
#if (PAGE_SIZE == 4096)
CACHE()
#endif
CACHE()
#if L1_CACHE_BYTES < 64
CACHE()
#endif
CACHE()
#if L1_CACHE_BYTES < 128
CACHE()
#endif
CACHE()
CACHE()
CACHE()
CACHE()
CACHE()
CACHE()
CACHE()
CACHE()
CACHE()
CACHE()
#if KMALLOC_MAX_SIZE >= 262144
CACHE()
#endif
#if KMALLOC_MAX_SIZE >= 524288
CACHE()
#endif
#if KMALLOC_MAX_SIZE >= 1048576
CACHE()
#endif
#if KMALLOC_MAX_SIZE >= 2097152
CACHE()
#endif
#if KMALLOC_MAX_SIZE >= 4194304
CACHE()
#endif
#if KMALLOC_MAX_SIZE >= 8388608
CACHE()
#endif
#if KMALLOC_MAX_SIZE >= 16777216
CACHE()
#endif
#if KMALLOC_MAX_SIZE >= 33554432
CACHE()
#endif
上述两种slab缓存,专用slab主要用于内核各模块的一些数据结构,这些内存是模块启动时就通过kmem_cache_alloc分配好占为己有,一些模块自己单独申请一块kmem_cache可以确保有可用内存。而各阶的通用slab则用于给内核中的kmalloc等函数分配内存。
要注意在slab分配器里面的“cache”特指struct kmem_cache结构的实例,与CPU的cache无关。在/proc/slabinfo中可以查看当前系统中已经存在的“cache”列表。
通过slabtop命令可以查看当前系统中slab内存的消耗情况,和top命令类似,是按照已分配出去的内存多少的顺序打印的:
➜ vdbench sudo slabtop --once
Active / Total Objects (% used) : / (94.7%)
Active / Total Slabs (% used) : / (100.0%)
Active / Total Caches (% used) : / (71.5%)
Active / Total Size (% used) : .18K / .58K (95.7%)
Minimum / Average / Maximum Object : .01K / .29K / .88K OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
% .10K 48716K buffer_head
% .19K 44176K dentry
% .06K 180064K ext4_inode_cache
% .20K 12476K vm_area_struct
% .04K 2248K ext4_extent_status
% .57K 26928K radix_tree_node
% .13K 5732K kernfs_node_cache
% .06K 2316K pid
% .06K 2312K kmalloc-
% .69K 20544K squashfs_inode_cache
% .09K 1804K anon_vma
% .02K 464K lsm_file_cache
% .25K 4788K filp
% .59K 10768K inode_cache
% .05K 736K ftrace_event_field
% .03K 464K kmalloc-
% .02K 228K kmalloc-
% .07K 708K Acpi-Operand
% .01K 72K kmalloc-
% .09K 820K kmalloc-
% .14K 1196K ext4_groupinfo_4k
% .04K 236K Acpi-Namespace
% .19K 1124K kmalloc-
% .70K 2736K shmem_inode_cache
% .00K 3680K kmalloc-
% .66K 1920K proc_inode_cache
% .12K 344K kmalloc-
% .05K 136K mbcache
% .50K 1192K kmalloc-
% .19K 428K cred_jar
% .12K 280K eventpoll_epi
% .00K 4032K kmalloc-
% .69K 1392K sock_inode_cache
% .25K 500K kmalloc-
% .09K 172K trace_event_file
% .69K 1344K i915_vma
% .00K 7648K kmalloc-
因此,slab和buddy是上下级的调用关系,slab的内存来自buddy;它们都是内存分配器,只是buddy管理的是各ZONE映射区,slab管理的是buddy的各阶。
注意,vmalloc是直接向buddy要内存的,不经过slab,因此vmalloc申请内存的最小单位是一页。slab只从lowmem申请内存,因此拿到的内存在物理上是连续的,vmalloc可以从高端和低端拿内存。而用户态的malloc是通过brk/mmap系统调用每次向内核申请一页,然后在标准库里再做进一步管理供用户程序使用。 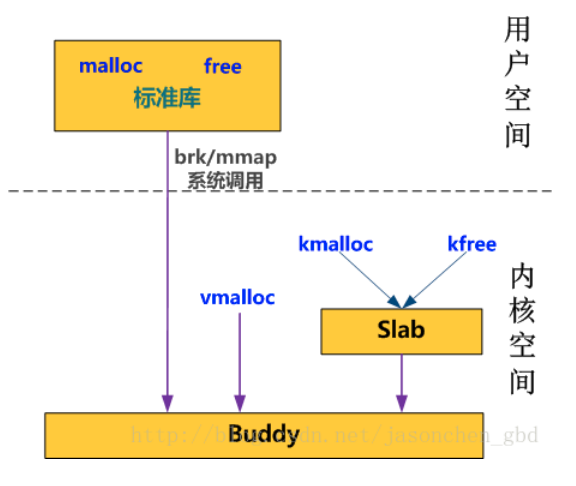
2. 用户态申请内存时的”lazy allocation”
用户态申请内存时,库函数并不会立即从内核里去拿,而是COW(copy on write)的,要不然用户态细细碎碎的申请释放都要跟内核打交道,那频繁系统调用的代价太大,并且内核每次都是一页一页的分配给用户态,小内存让内核很头疼的。
但是库函数会欺骗用户程序,你申请10MB,就让你以为已经拥有了10MB内存,但是只有你真的要用的时候,C库才会一点一点的从内核申请,直到10MB都拿到,这就是用户态申请内存的lazy模式。有时用户程序为了立即拿到这10MB内存,在申请完之后,会立即把内存写一遍(例如memset为0),让C库将内存都真正申请到。Linux会欺骗用户程序,但不欺骗内核,内核中的kmalloc/vmalloc就真的是要一个字节内存就没了一个字节。
因此malloc在刚申请(brk或mmap)的时候,10MB所有页面在页表中全都映射到同一个零化页面(ZERO_PAGE,全局共享的页,页的内容总是0,用于zero-mapped memory areas等用途),内容全是0,且页表上标记这10MB是只读的,在写的时候发生page fault,才去一页一页的分配内存和修改页表。所以brk和mmap只是扩展了你的虚拟地址空间,而不是去拿内存。在你实际去写内存的时候,内核会先把这个只读0页面拷贝到给你新分配的页面,然后执行你的写操作。
由于上面的COW,用户申请了10MB,系统不会立即给你,但告诉你申请成功了。Linux内核的lazy模式可以减少不必要的内存浪费,因为用户态程序的行为不可控制,如果有一个程序申请100M内存又不用,就浪费了。如果一段时间后,系统内存被其他地方消耗,已经不足以给你10MB了,你这时慢慢通过COW使用内存的时候,C库就拿不到内存了。就会出现OOM。
补充一点,由于用户进程申请内存是zero页面拷贝的,因此用户态向kernel新申请的页面都是清0的,这样可以防止用户态窃取内核态的数据。但是如果用户程序用完释放了,但还没还给内核,这时相同的进程又申请到了这段内存,那内存里就是原来的数据,不清0的。而内核的kmalloc/vmalloc就没这个动作了,想要清0页面可以用kzalloc/vzalloc。
进程栈的内存分配也是lazy的,因为进程栈对应的VMA的vma->vm_flags带有VM_GROWSDOWN标记,这样,在page fault处理的时候kernel就知道落在了stack区域,就会通过expand_stack(vma, address)将栈扩展(vma区域的vm_start降低),这时如果扩展超过RLIMIT_STACK或RLIMIT_AS的限制,就会返回-ENOMEM。因此,对于进程栈,用户态不用做申请内存的动作,只需将sp下移即可,这是每个函数都要做的事情。
3. OOM(Out Of Memory)
OOM即是内存不够用了,在内核中会选择杀掉某个进程来释放内存,内核会给所有进程打分,分最高的则被杀掉,打分的依据主要是看谁占的内存多(当然是杀掉占内存的多的进程才能释放更多内存)。每个进程的/proc/pid/oom_score就是当前得分,OOM的时候就会选择分数最高的那个杀掉。被干掉之后,OOM的打印中也会打印出这个进程的score。
评分标准(mm/oom_kill.c中的badness()给每个进程一个oom score)有:
根据resident内存、page table和swap的使用情况,采用百分比乘以10,因此最高1000分,最低0分。
root用户进程减30分。
oom_score_adj: oom_score会加上这个值。可以在/proc/pid/oom_score_adj中修改(可以是负数),这样来人为地调整score结果。
oom_adj: -16~15的系数调整。修改/proc/pid/oom_adj里面的值,是一个系数,因此会在原score上乘上系数。数值越大,score结果就会变得越大,数值为负数时,score就会变得比原值小。
修改了3、4之后,/proc/pid/oom_score中的值就会随之改变。这样的话,就可以人为地干预OOM杀掉的进程。
注意,任何一个zone内存不足,都会触发OOM。
Android就利用了修改评分标准的特点,对于转向后台的进程打分提高,对前台进程的打分降低一点,尽可能防止前台进程退出。而进程进入后台时,Android并不杀死它,而是让他活着,如果这时系统内存足够,那么后台进程就一直活着,下次再调出这个进程时就很快。而如果某时刻内存不够了,那个OOM就会根据评分优先杀掉后台进程,让前台进程活着,而后台进程的重启只是稍微影响用户体验而已。
补充:如何满足DMA的连续内存需求
我们说buddy容易碎,但DMA通常只能操作一段物理上连续的内存,因此我们应该保证系统有足量的连续内存以使DMA正常工作。
1. 预分配一块内存
可以在系统启动时就预留出部分内存给DMA专用,这通常要在bootmem的阶段做,使这部分内存和buddy系统分离。并且需要提供申请释放内存的API给每个有需求的device。可以借用bigphysarea来完成。这种做法的缺点是这块连续内存永远不能给其他地方用(即使有没有被使用),可能被浪费,并且需要额外的物理内存管理。但这种预分配的思想在很多场合是最省力也很常用的。
2. IOMMU
如果device的DMA支持IOMMU(MMU for I/O),也就是DMA内部有自己的MMU,就相当于MMU之于CPU(将virtual address映射到physical address),IOMMU可以将device address映射到physical address。这样就不再需要物理地址连续了。IOMMU相比普通DMA访存要耗时且耗电,不太常见。
3. CMA
处理DMA中的碎片有一个利器,CMA(连续内存分配器,在kernel v3.5-rc1正式被引入)。和磁盘碎片整理类似,这个技术也是将内存碎片整理,整合成连续的内存。因为对一个虚拟地址,它可以在不同时间映射到不同的物理地址,只要内容不变就行,对程序员是透明的。
上面讲了,物理地址映射关系对于CPU来讲是透明的,因此可以说虚拟内存是可移动(movable)的,但内核的内存一般不移动,应用程序一般就可以。应用程序在申请内存的时候可以标记我的这块内存是__GFP_MOVABLE的,让CMA认为可搬移。
CMA的原理就是标记一段连续内存,这段内存平时可以作为movable的页面使用。那么应用程序在申请内存时如果打上movable的标记,就可以从这段连续内存里申请。当然,这段内存慢慢就碎了。当一个设备的DMA需要连续内存的时候,CMA就可以发挥作用了:比如设备想申请16MB连续内存,CMA就会从其他内存区域申请16MB,这16MB可能是碎的,然后将自己区域中已经被分出去的16MB的页面一一搬移到新申请的16MB页面中,这时CMA原来标记的内存就空出来了。CMA还要做一件事情,就是去修改被搬离的页所属的哪些进程的页表,这样才能让用户程序在毫无知觉的情况下继续正常运行。
注意,CMA的API是封装到DMA里面,所以你不能直接调用CMA接口,DMA的底层才用CMA(当然DMA也可以不用CMA机制,如果你的CPU不带CMA就更不用说了)。如果你的系统支持CMA,dma_alloc_coherence()内部就可能用CMA实现。
dts里面可指定哪部分内存是可CMA的。可以是全局的CMA pool,也可以为某个特定设备指定CMA pool。具体填法见内核源码中的 Documentation\devicetree\bindings\reserved-memory\reserved-memory.txt。
https://blog.csdn.net/jasonchen_gbd/article/details/79461385
Linux内存管理 —— 内核态和用户态的内存分配方式的更多相关文章
- linux内核态和用户态的信号量
在Linux的内核态和用户态都有信号量,使用也不同,简单记录一下. 1> 内核信号量,由内核控制路径使用.内核信号量是struct semaphore类型的对象,它在中定义struct sema ...
- 在linux系统中实现各项监控的关键技术(2)--内核态与用户态进程之间的通信netlink
Netlink 是一种在内核与用户应用间进行双向数据传输的非常好的方式,用户态应用使用标准的 socket API 就可以使用 netlink 提供的强大功能,内核态需要使用专门的内核 API 来使用 ...
- Linux 内核态与用户态通信 netlink
参考资料: https://blog.csdn.net/zqixiao_09/article/details/77131283 https://www.cnblogs.com/lopnor/p/615 ...
- Linux内核态和用户态
两张图说明Linux内核态和用户态之间的关系
- Linux内核态、用户态简介与IntelCPU特权级别--Ring0-3
一.现代操作系统的权限分离: 现代操作系统一般都至少分为内核态和用户态.一般应用程序通常运行于用户态,而当应用程序调用系统调用时候会执行内核代码,此时会处于内核态.一般的,应用程序是不能随便进入内核态 ...
- 【转】linux内核态和用户态的区别
原文网址:http://www.mike.org.cn/articles/linux-kernel-mode-and-user-mode-distinction/ 内核态与用户态是操作系统的两种运行级 ...
- linux内核态和用户态小结
一 内核态和用户态的区别 当进程执行系统调用而陷入内核代码中执行时,我们就称进程处于内核状态.此时处理器处于特权级最高的(0级)内核代码.当进程处于内核态时,执行的内核代码会使用当前的内核栈.每个进程 ...
- go语言学习--内核态和用户态(协程)
go中的一个特点就是引入了相比于线程更加轻量级的协程(用户态的线程),那么什么是用户态和内核态呢? 一.什么是用户态和内核态 当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核 ...
- [OS] 内核态和用户态的区别
http://blog.csdn.net/fatsandwich/article/details/2131707# http://jakielong.iteye.com/blog/771663 当一个 ...
随机推荐
- sklearn——回归评估指标
sklearn中文文档:http://sklearn.apachecn.org/#/ https://www.cnblogs.com/nolonely/p/7009001.html https://w ...
- java——平衡二叉树 AVLTree、AVLMap、AVLSet
平衡二叉树:对于任意一个节点,左子树和右子树的高度差不能超过1 package Date_pacage; import java.util.ArrayList; public class AVLTre ...
- robotFramework接口测试GET和POST请求
安装: 接口测试需要安装Request和RequestLibrary 包 使用cmd命令安装:pip install requests 使用cmd命令安装:pip install -U robotfr ...
- maya2012安装失败如何卸载重装
AUTODESK系列软件着实令人头疼,安装失败之后不能完全卸载!!!(比如maya,cad,3dsmax等).有时手动删除注册表重装之后还是会出现各种问题,每个版本的C++Runtime和.NET f ...
- ubuntu mongodb报错:mongo - couldn't connect to server 127.0.0.1:27017
在进入mongo的时候,出现在下面错误信息.那如何解决呢? 标记一下,以便下次理碰的到时候,有个参考. warning: Failed to connect to 127.0.0.1:27017, r ...
- (转)shell解析命令行的过程以及eval命令
shell解析命令行的过程以及eval命令 本文说明的是一条linux命令在执行时大致要经过哪些过程?以及这些过程的大致顺序. 1.1 shell解析命令行 shell读取和执行命令时的大致操作过 ...
- (转)stty 命令说明及使用讲解
stty 命令说明及使用讲解 UNIX系统的命令很多,但是巧妙使用命令的方法更多.随着经验的积累和观察学习其他用户的实践,我们也可学会解决特殊问题的方法.这里谈谈自己使用UNIX系统中stty ...
- [API]API运用实例
首先,在百度API:http://apistore.baidu.com/查找自己想用的api接口,例如:翻译: 利用postman工具进行测试: 返回结果为JSON字符串: { "errNu ...
- C/C++中 static 的作用
在C中,有三个作用: 1.修饰全局变量: 作用是隐藏,也就是这个全局变量仅在本文件中可见. 2.修饰局部变量: 作用是扩展变量的生存期,令这个局部变量成为静态的. 3.修饰函数: 作用是隐藏,将此函数 ...
- 当post 的字段很多,post的字段并不完全修改(有的值是前端input的值,有的任保留原来原来数据库的值),
有一种解决方法(ps:from ljq): 把数据库的值先全部遍历出来,然后再对遍历出来值的$key进行一个判断, example: foreach ($results[0] as $key =&g ...