机器学习:集成学习(集成学习思想、scikit-learn 中的集成分类器)
一、集成学习的思想
- 集成学习的思路:一个问题(如分类问题),让多种算法参与预测(如下图中的算法都可以解决分类问题),在多个预测结果中,选择出现最多的预测类别做为该样本的最终预测类别;
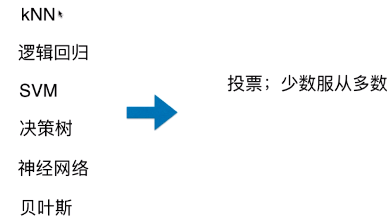
- 生活中的集成思维:
- 选择电影:10 个人中,如果有8个人觉得这个电影值得看,那么很多人就会跟进这个现象选择看这部电影;
二、scikit-learn 中的集成分类器
- scikit-learn 中封装的集成分类器:VotingClassifier
1)模拟集成学习操作
模拟数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets # n_samples=500:表示生成 500 个样本;默认自动生成 100 个样本;
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42) from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
- datasets.make_moons(n_samples=500):表示生成 500 个样本;默认自动生成 100 个样本;
使用逻辑回归算法分类器
from sklearn.linear_model import LogisticRegression log_clf = LogisticRegression()
log_clf.fit(X_train, y_train)
log_clf.score(X_test, y_test)
# 准确率:0.864使用 SVM 算法分类器
from sklearn.svm import SVC svm_clf = SVC()
svm_clf.fit(X_train, y_train)
svm_clf.score(X_test, y_test)
# 准确率:0.888使用决策树算法分类器
from sklearn.tree import DecisionTreeClassifier dt_clf = DecisionTreeClassifier()
dt_clf.fit(X_train, y_train)
dt_clf.score(X_test, y_test)
# 准确率:0.84- 对各个算法预测结果投票
y_predict1 = log_clf.predict(X_test)
y_predict2 = svm_clf.predict(X_test)
y_predict3 = dt_clf.predict(X_test) y_predict = np.array((y_predict1 + y_predict2 + y_predict3) >= 2, dtype='int')
- 投票方式:
- (y_predict1 + y_predict2 + y_predict3) >= 2
- 三种算法的预测结果中,只有当 2 个或 3 个的预测结果为 1 时,最终的预测结果才为 1;
- 查看投票结果的准确率
from sklearn.metrics import accuracy_score accuracy_score(y_test, y_predict)
# 准确率:0.896 - 采用集成学习思路得到的准确率比其它 3 中算法得到的准确率高;
二、scikit-learn 中的集成分类器
1)代码
from sklearn.ensemble import VotingClassifier
# 集成分类器 VotingClassifier 的参数:
# 1)estimators=[]:传入需要使用的算法,放在列表中,使用方式类似管道 Pipeline;
# 2)voting='hard':表示选择最终预测结果的方式,以出现最多的分类结果作为最终的预测结果;
# 正常情况下,需要对所选择的算法进行调参;
voting_clf = VotingClassifier(estimators=[
('log_clf', LogisticRegression()),
('svm_clf', SVC()),
('dt_clf', DecisionTreeClassifier())
], voting='hard')
voting_clf.fit(X_train, y_train)
voting_clf.score(X_test, y_test)
# 准确率:0.896- 注意
- 使用方式如以上红色代码;
- 参数 estimators=[ ]:传入需要使用的算法,放在列表中,使用方式类似管道 Pipeline;
- 参数 voting='hard':表示选择最终预测结果的方式,以出现最多的分类结果作为最终的预测结果;
- 正常情况下,需要对所选择的算法进行调参;
机器学习:集成学习(集成学习思想、scikit-learn 中的集成分类器)的更多相关文章
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- sklearn中调用集成学习算法
1.集成学习是指对于同一个基础数据集使用不同的机器学习算法进行训练,最后结合不同的算法给出的意见进行决策,这个方法兼顾了许多算法的"意见",比较全面,因此在机器学习领域也使用地非常 ...
- webService学习之路(三):springMVC集成CXF后调用已知的wsdl接口
webService学习之路一:讲解了通过传统方式怎么发布及调用webservice webService学习之路二:讲解了SpringMVC和CXF的集成及快速发布webservice 本篇文章将讲 ...
- Quartz学习——SSMM(Spring+SpringMVC+Mybatis+Mysql)和Quartz集成详解(转)
通过前面的学习,你可能大致了解了Quartz,本篇博文为你打开学习SSMM+Quartz的旅程!欢迎上车,开始美好的旅程! 本篇是在SSM框架基础上进行的. 参考文章: 1.Quartz学习——Qua ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- 视觉机器学习读书笔记--------BP学习
反向传播算法(Back-Propagtion Algorithm)即BP学习属于监督式学习算法,是非常重要的一种人工神经网络学习方法,常被用来训练前馈型多层感知器神经网络. 一.BP学习原理 1.前馈 ...
随机推荐
- JavaWeb 文件上传下载
1. 文件上传下载概述 1.1. 什么是文件上传下载 所谓文件上传下载就是将本地文件上传到服务器端,从服务器端下载文件到本地的过程.例如目前网站需要上传头像.上传下载图片或网盘等功能都是利用文件上传下 ...
- 1.linux源码安装nginx
从官网下载nginx.tar.gz源码包 拷贝至Linux系统下进行解压 tar -zxvf nginx.tar.gz 进入解压后的目录,需要./configure,此步骤会报多个错,比如没有安装gc ...
- 未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0” 提供程序
我在Web App程序里面用“Microsoft.Jet.OLEDB.4.0”来连接Excel文件,导入到数据库,在Windows 2003+ Office 2007 的环境下正常,但是在Window ...
- How to use Jenkins
一.关键点 1.how to start the build server? do i need to start some app to do this? I don't believe so... ...
- ML 逻辑回归 Logistic Regression
逻辑回归 Logistic Regression 1 分类 Classification 首先我们来看看使用线性回归来解决分类会出现的问题.下图中,我们加入了一个训练集,产生的新的假设函数使得我们进行 ...
- 对象存储API
使用对象存储API步骤: 1.购买腾讯云对象存储(COS)服务 2.在腾讯云 对象存储控制台 里创建一个Bucket 3.在控制器 个人API密钥 页里获取APPID,SecretID,SecretK ...
- python 矩阵分成上三角下三角和对角三个矩阵
diagonal Return specified diagonals. diagflat Create a 2-D array with the flattened input as a diago ...
- C++(十三)— map的排序
在c++中有两个关联容器,第一种是map,内部是按照key排序的,第二种是unordered_map,容器内部是无序的,使用hash组织内容的. 1.对有序map中的key排序 如果在有序的map中, ...
- Codeforces Round #437 (Div. 2, based on MemSQL Start[c]UP 3.0 - Round 2) E
题意:减前面的数,加后面的数,保证最后不剩下数,加减次数要相同: 题解:emmmmm,看出是个贪心,先对价值排序,相同就对下标排序,规律是每次找第一个,然后从后往前找没有使用过的下表比他大的第一个,相 ...
- Ubuntu下常用的快捷键
熟练地快捷键操作可以大大的节省我们的时间,下面贴上一些快捷键的操作: 桌面常用快捷键 Alt + F1:聚焦到桌面左侧任务导航栏,可按上下键进行导航 Alt + F2:运行命令 Alt + F4:关闭 ...