hadoop_学习_02_Hadoop环境搭建(单机)
一、环境准备
1.说明
hadoop的下载来源有:
官方版本:http://archive.apache.org/dist/hadoop/
CDH版本:http://archive.cloudera.com/cdh5
企业应用一般选择CDH版本,因为比较稳定。
若决定使用CDH版本,则要保证相关软件的CDH版本相同,如 选择 hadoop-2.6.0-cdh5.9.3 与 hbase-1.2.0-cdh5.9.3
2.环境准备
操作系统 : linux CentOS 6.8
jdk:1.7
cdh版本为: 5.9.3
hadoop-2.6.0-cdh5.9.3
二、服务器基本配置
1.配置主机名
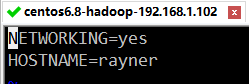
(1)修改 hostname
sudo vim /etc/sysconfig/network
将HOSTNAME修改为 rayner (改成你自己的,所有的地方一致即可)
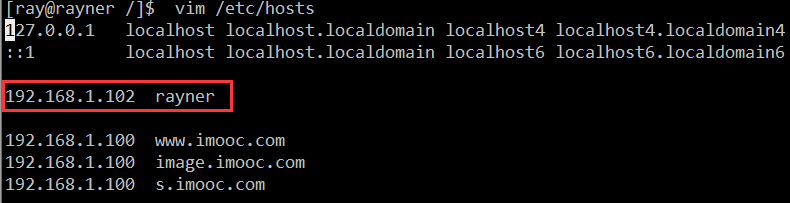
(2)映射主机 ip 与主机名
sudo vim /etc/hosts
加入以下配置:
192.168.1.102 rayner
2.关闭防火墙
关闭防火墙,这样就可以在本机 window 中访问虚拟机的所有端口了
CentOS 7版本以下输入:
service iptables stop
CentOS 7 以上的版本输入:
systemctl stop firewalld.service
3.时间设置
输入:
date
查看服务器时间是否一致,若不一致则更改
更改时间命令
date -s ‘MMDDhhmmYYYY.ss’
三、Hadoop下载
1.hadoop下载地址
http://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
2.下载hadoop
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
3.解压hadoop
tar -zxvf hadoop-2.6.0.tar.gz
4.创建文件夹
sudo mkdir /ray/hadoop
sudo mkdir /ray/hadoop/tmp
sudo mkdir /ray/hadoop/var
sudo mkdir /ray/hadoop/dfs
sudo mkdir /ray/hadoop/dfs/name
sudo mkdir /ray/hadoop/dfs/data
四、Hadoop环境配置
1.配置profile文件-环境变量
(1)编辑 profile 文件
sudo vim /etc/profile
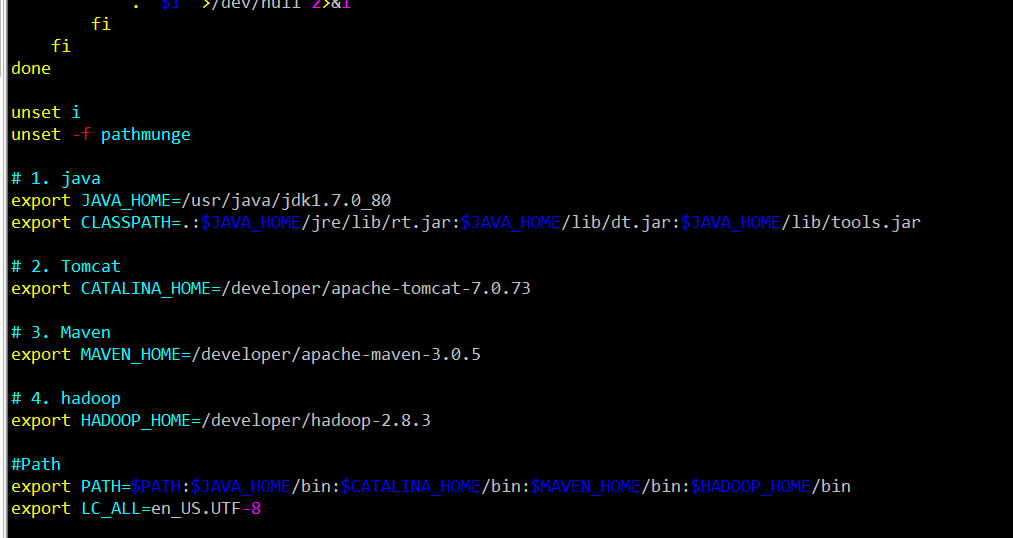
(2)设置 HADOOP_HOME ,并将其添加到path中
# 1. java
export JAVA_HOME=/usr/java/jdk1.7.0_80
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # 2. Tomcat
export CATALINA_HOME=/developer/apache-tomcat-7.0.73 # 3. Maven
export MAVEN_HOME=/developer/apache-maven-3.0.5 # 4. hadoop
export HADOOP_HOME=/developer/hadoop-2.6.0 #Path
export PATH=$HADOOP_HOME/bin:$MAVEN_HOME/bin:$CATALINA_HOME/bin:$JAVA_HOME/bin:$PATH
export LC_ALL=en_US.UTF-8
(3)使配置生效
source /etc/profile
2.配置 hadoop-env.sh
(1) 进入路径:
cd /developer/hadoop-2.6.0/etc/hadoop

(2) 编辑 hadoop-env.sh
sudo vim hadoop-env.sh
(3) 配置JAVA_HOME
将${JAVA_HOME} 修改为自己的JDK路径 ,即
将
export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/usr/java/jdk1.7.0_80
3.配置 core-site.xml
(1)编辑 core-site.xml
sudo vim core-site.xml
(2)在 configuration 节点中 加入以下配置
注意要将value替换成自己的
<!--1. tmp -->
<property>
<name>hadoop.tmp.dir</name>
<value>/ray/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property> <!--2. default.name -->
<property>
<name>fs.default.name</name>
<value>hdfs://rayner:9000</value>
</property>
4.配置 hdfs-site.xml
(1)编辑 hdfs-site.xml
sudo vim hdfs-site.xml
(2)在 configuration 节点中 加入以下配置
<!--1. name -->
<property>
<name>dfs.name.dir</name>
<value>/ray/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property> <!--2. data -->
<property>
<name>dfs.data.dir</name>
<value>/ray/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property> <!--3. replication -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property> <!--4. permissions -->
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
说明:dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,
方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
5.配置 mapred-site.xml
如果没有 mapred-site.xml 该文件,就复制mapred-site.xml.template文件并重命名为 mapred-site.xml。
(1) 编辑 mapred-site.xml
sudo vim mapred-site.xml
(2) 在 configuration 节点中 加入以下配置
<!--1. job -->
<property>
<name>mapred.job.tracker</name>
<value>rayner:9001</value>
</property> <!--2. local -->
<property>
<name>mapred.local.dir</name>
<value>/ray/hadoop/var</value>
</property> <!--3. framework -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
五、hadoop 常用命令
1.格式化namenode
第一次启动Hadoop需要初始化
切换到 /home/hadoop/hadoop2.8/bin目录下输入
hadoop namenode -format
这一步可能会出现异常:
Unable to determine local hostname -falling back to "localhost"
java.net.UnknownHostException: rayner: rayner
2、启动hadoop
启 /developer/hadoop-2.6.0/sbin/start-all.sh
停 /developer/hadoop-2.6.0/sbin/stop-all.sh
(1)进入sbin目录,执行以下命令
/developer/hadoop-2.6.0/sbin/start-all.sh
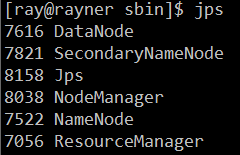
(2)使用jps命令查看启动成功效果
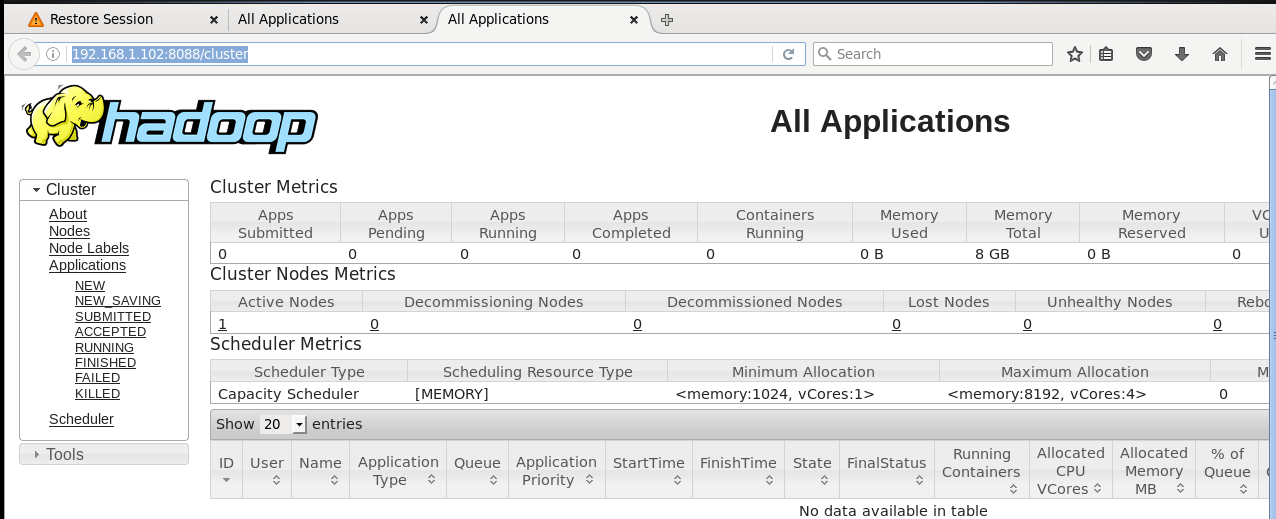
(2)浏览器输入: 127.0.0.1:8088/cluster 或者 192.168.1.102:8088/cluster ,会出现下图
(3)浏览器输入:127.0.0.1:50070 或者 192.168.1.102:50070

2.查看hadoop下有哪些文件
hadoop fs -ls /
六、参考资料
1.大数据学习系列之一 ----- Hadoop环境搭建(单机)
hadoop_学习_02_Hadoop环境搭建(单机)的更多相关文章
- hive_学习_01_hive环境搭建(单机)
一.前言 本文承接上一篇:hbase_学习_01_HBase环境搭建(单机),主要是搭建 hive 的单机环境 二.环境准备 1.说明 hive 的下载来源有: 官方版本:http://archive ...
- hbase_学习_01_HBase环境搭建(单机)
一.前言 本文承接上一篇:hadoop_学习_02_Hadoop环境搭建(单机) ,主要是搭建HBase的单机环境 二.环境准备 1.说明 hbase 的下载来源有: 官方版本:http://arc ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- Ubuntu16.04深度学习基本环境搭建,tensorflow , keras , pytorch , cuda
Ubuntu16.04深度学习基本环境搭建,tensorflow , keras , pytorch , cuda Ubuntu16.04安装 参考https://blog.csdn.net/flyy ...
- ubuntu 深度学习cuda环境搭建,docker-nvidia 2019-02
ubuntu 深度学习cuda环境搭建 ubuntu系统版本 18.04 查看GPU型号(NVS 315 性能很差,比没有强) 首先最好有ssh服务,以下操作都是远程ssh执行 lspci | gre ...
- Python基础学习之环境搭建
Python如今成为零基础编程爱好者的首选学习语言,这和Python语言自身的强大功能和简单易学是分不开的.今天我们将带领Python零基础的初学者完成入门的第一步——环境搭建.本文会先来区分几个在P ...
- 001-深度学习Pytorch环境搭建(Anaconda , PyCharm导入)
001-深度学习Pytorch环境搭建(Anaconda , PyCharm导入) 在开始搭建之前我们先说一下本次主要安装的东西有哪些. anaconda 3:第三方包管理软件. 这个玩意可以看作是一 ...
- 人工智能之深度学习-初始环境搭建(安装Anaconda3和TensorFlow2步骤详解)
前言: 本篇文章主要讲解的是在学习人工智能之深度学习时所学到的知识和需要的环境配置(安装Anaconda3和TensorFlow2步骤详解),以及个人的心得体会,汇集成本篇文章,作为自己深度学习的总结 ...
- 深度学习开发环境搭建教程(Mac篇)
本文将指导你如何在自己的Mac上部署Theano + Keras的深度学习开发环境. 如果你的Mac不自带NVIDIA的独立显卡(例如15寸以下或者17年新款的Macbook.具体可以在"关 ...
随机推荐
- 使用strace,lstrace,truss来跟踪程序的运行过程
使用truss.strace或ltrace诊断软件问题 2008-07-05 16:25 使用truss.strace或ltrace诊断软件问题 进程无法启动,软件运行速度突然变慢, ...
- JSP隐式对象是JSP容器为每个页面提供的Java对象
JSP 隐式对象 JSP隐式对象是JSP容器为每个页面提供的Java对象,开发者可以直接使用它们而不用显式声明.JSP隐式对象也被称为预定义变量. JSP所支持的九大隐式对象: 对象 描述 reque ...
- vue实践---vue结合 promise 封装原生ajax
有时候不想使用axios这样的外部依赖,想自己封装ajax,这里有两种方法 方法一,在单个页面内使用 封装的代码如下: beforeCreate () { this.$http = (() => ...
- vue实践---vue配合express实现请求数据mock
mock数据是前端比较常见的技术,这里介绍下vue配合express 实现请求数据mock. 第一步: 安装 express : npm install express -D 第二步: 简历需要mo ...
- 关于html的小bug
废话不说 看代码 因为最近比较忙 所以不闲聊了啊 <!DOCTYPE html> <html lang="en"> <head> <me ...
- 2016 acm香港网络赛 A题. A+B Problem (FFT)
原题地址:https://open.kattis.com/problems/aplusb FFT代码参考kuangbin的博客:http://www.cnblogs.com/kuangbin/arch ...
- 在mac上独立安装PHP环境
1.http://dditblog.com/blog_418.html 2.http://www.jianshu.com/p/0456dd3cc78b
- python的学习研究
2017年5月8日-----开始学习python 为什么学习python? 感觉做爬虫很酷,我又不喜欢Java,所以就学python 提升自己,入行PHP到这个月底半年,想更多的扩展自己,让自己增值 ...
- 通讯录链表实现之C++
前言 在mooc上学习了链表中的顺序表和单链表,并使用单链表数据结构跟着老师完成通讯录创建.通过这次链表练习使用,做一些总结. 自顶向下设计探索. 功能需求 在功能实现上,通讯录主要包括,创建联系人, ...
- 【BZOJ1444】[Jsoi2009]有趣的游戏 AC自动机+概率DP+矩阵乘法
[BZOJ1444][Jsoi2009]有趣的游戏 Description Input 注意 是0<=P Output Sample Input Sample Output HINT 30%的 ...