Spark最简安装
该环境适合于学习使用的快速Spark环境,采用Apache预编译好的包进行安装。而在实际开发中需要使用针对于个人Hadoop版本进行编译安装,这将在后面进行介绍。
Spark预编译安装包下载——Apache版
下载地址:http://spark.apache.org/downloads.html (本例使用的是Spark-2.2.0版本)
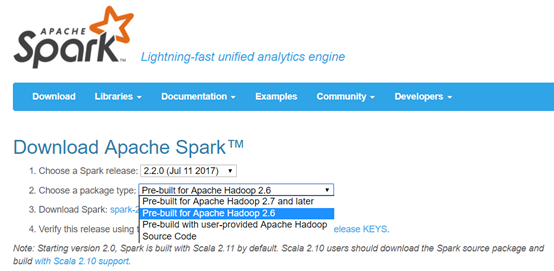
接下来依次执行下载,上传,然后解压缩操作。
[hadoop@masternode ~]$ cd /home/hadoop/app
[hadoop@masternode app]$ rz //上传
选中刚才下载好的Spark预编译好的包,点击上传。
[hadoop@masternode app]$ tar –zxvf spark-2.2.0-bin-hadoop2.6.tgz //解压
[hadoop@masternode app]$ rm spark-2.2.0-bin-hadoop2.6.tgz
[hadoop@masternode app]$ mv spark-2.2.0-bin-hadoop2.6/ spark-2.2.0 //重命名
[hadoop@masternode app]$ ll
total 24
drwxrwxr-x. 7 hadoop hadoop 4096 Aug 23 16:32 elasticsearch-2.4.0
drwxr-xr-x. 10 hadoop hadoop 4096 Apr 20 13:59 hadoop
drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60
drwxrwxr-x. 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64
drwxr-xr-x. 12 hadoop hadoop 4096 Jul 1 2017 spark-2.2.0
drwxr-xr-x. 14 hadoop hadoop 4096 Apr 19 10:00 zookeeper
[hadoop@masternode app]$ cd spark-2.2.0/
[hadoop@masternode spark-2.2.0]$ ll
total 104
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 bin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 conf
drwxr-xr-x. 5 hadoop hadoop 4096 Jul 1 2017 data
drwxr-xr-x. 4 hadoop hadoop 4096 Jul 1 2017 examples
drwxr-xr-x. 2 hadoop hadoop 12288 Jul 1 2017 jars
-rw-r--r--. 1 hadoop hadoop 17881 Jul 1 2017 LICENSE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 licenses
-rw-r--r--. 1 hadoop hadoop 24645 Jul 1 2017 NOTICE
drwxr-xr-x. 6 hadoop hadoop 4096 Jul 1 2017 python
drwxr-xr-x. 3 hadoop hadoop 4096 Jul 1 2017 R
-rw-r--r--. 1 hadoop hadoop 3809 Jul 1 2017 README.md
-rw-r--r--. 1 hadoop hadoop 128 Jul 1 2017 RELEASE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 sbin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 yarn
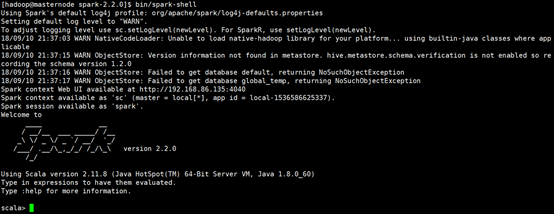
如图所示,可以进入Spark Shell模式,表示安装正常。
Spark目录介绍
1.bin 运行脚本目录
beeline
find-spark-home
load-spark-env.sh //加载spark-env.sh中的配置信息,确保仅会加载一次
pyspark //启动python spark shell,./bin/pyspark --master local[]
run-example //运行example
spark-class //内部最终变成用java运行java类
sparkR
spark-shell //启动scala spark shell,./bin/spark-shell --master local[]
spark-sql
spark-submit //提交作业到master
运行example
# For Scala and Java, use run-example:
./bin/run-example SparkPi
# For Python examples, use spark-submit directly:
./bin/spark-submit examples/src/main/python/pi.py
# For R examples, use spark-submit directly:
./bin/spark-submit examples/src/main/r/dataframe.R2.conf
docker.properties.template
fairscheduler.xml.template
log4j.properties.template //集群日志模版
metrics.properties.template
slaves.template //worker 节点配置模版
spark-defaults.conf.template //SparkConf默认配置模版
spark-env.sh.template //集群环境变量配置模版
3.data (例子里用到的一些数据)
graphx
mllib
streaming
4.examples 例子源码
jars
src
5.jars (spark依赖的jar包)
6.licenses (license协议声明文件)
7.python
8.R
9.sbin (集群启停脚本)
slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个shell命令
spark-config.sh //被其他所有的spark脚本所包含,里面有一些spark的目录结构信息
spark-daemon.sh //将一条spark命令变成一个守护进程
spark-daemons.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个spark命令
start-all.sh //启动master进程,以及所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-history-server.sh //启动历史记录进程
start-master.sh //启动spark master进程
start-mesos-dispatcher.sh
start-mesos-shuffle-service.sh
start-shuffle-service.sh
start-slave.sh //启动某机器上worker进程
start-slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-thriftserver.sh
stop-all.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上停止Worker进程
stop-history-server.sh //停止历史记录进程
stop-master.sh //停止spark master进程
stop-mesos-dispatcher.sh
stop-mesos-shuffle-service.sh
stop-shuffle-service.sh
stop-slave.sh //停止某机器上Worker进程
stop-slaves.sh //停止所有worker进程
stop-thriftserver.sh
10.yarn
spark-2.1.-yarn-shuffle.jar
Spark example
下面运行一个官网的小example。
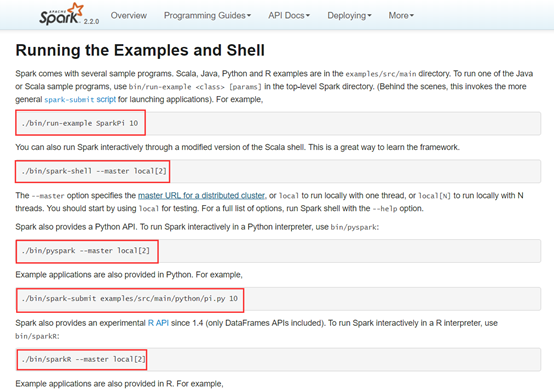
可以看到官网给出了详细的运行指令,我们运行第一个,算一下Pi的值。
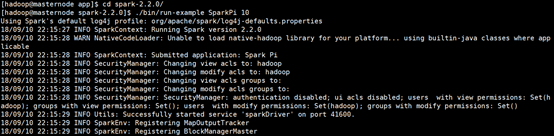
运算结果如下图所示:
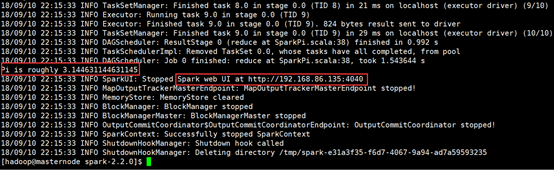
并且,如上图所示,我们可以根据图中URL地址查看web UI情况。

注意:此地址只能是在运行过程中才能查看的哦!
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Spark最简安装的更多相关文章
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- [软件开发技巧]·树莓派极简安装OpenCv
树莓派极简安装OpenCv 个人主页–> https://xiaosongshine.github.io/ 因为最近在开发使用树莓派+usb摄像头识别模块,打算用OpenCv,发现网上的树莓派O ...
- [深度学习工具]·极简安装Dlib人脸识别库
[深度学习工具]·极简安装Dlib人脸识别库 Dlib介绍 Dlib是一个现代化的C ++工具箱,其中包含用于在C ++中创建复杂软件以解决实际问题的机器学习算法和工具.它广泛应用于工业界和学术界,包 ...
- Spark学习笔记——安装和WordCount
1.去清华的镜像站点下载文件spark-2.1.0-bin-without-hadoop.tgz,不要下spark-2.1.0-bin-hadoop2.7.tgz 2.把文件解压到/usr/local ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- hadoop环境的安装 和 spark环境的安装
hadoop环境的安装1.前提:安装了java spark环境的安装1.前提:安装了java,python2.直接pip install pyspark就可以安装完成.(pip是python的软件安装 ...
随机推荐
- Select\Poll\Epoll异步IO与事件驱动
事件驱动与异步IO 事件驱动编程是一种编程规范,这里程序的执行流由外部事件来规定.它的特点是包含一个事件循环,但外部事件发生时使用回调机制来触发响应的处理.另外两种常见的编程规范是(单线程)同步以及多 ...
- web攻击之九:其它
四.身份认证和会话 [攻击] 黑客在浏览器中停用JS,防止客户端校验,从而进行某些操作. [防御] 1.隐藏敏感信息. 2.对敏感信息进行加密. 3.session 定期失效 五.权限与访问控制 [攻 ...
- get and set
(function () { function Student(name, age, gender) { this._name = name; this._age = age; this._gende ...
- Angular09 数据绑定、响应式编程、管道
1 数据绑定的分类 1.1 单向数据绑定 1.1.1 属性绑定 -> 数据从组件控制类到组件模板 DOM属性绑定 HTML属性绑定 1.1.2 事件绑定 -> 数据从组件模板到组件控制类 ...
- Flask08 包含(include)、继承(extends)、宏???、模板中变量的来源、利用bootstrap构建自己的网页结构
1 包含 直接把另一个文件的内容,复制粘贴过来 {% include "模板路径" %} 注意:模板都是放在 templates 这个文件夹下面的,可以在里面新建文件夹来进行分离: ...
- 项目一:第三天 收派标准添加 收派标准分页查询(基于datagrid实现) 收派标准修改快递员添加 快递员列表查询
1.收派标准添加 n jQuery easyUI window使用 n jQuery easyUI form表单校验 n 收派标准添加页面调整—url params n 服务端实现—三层 2.jQue ...
- Ubuntu使用crontab 使用举例
除了这些固定值外,还可以配合星号(*),逗号(,),和斜线(/)来表示一些其他的含义: 星号 表示任意值,比如在小时部分填写 * 代表任意小时(每小时) 逗号 ...
- Code Page Identifiers - Copy from Microsoft
Code Page Identifiers 78 out of 94 rated this helpful - Rate this topic The following table define ...
- Java对象在内存中的状态
可达的/可触及的 Java对象呗创建后,如果被一个或者多个变量引用,那就是可达的,即从根节点可以触及到这个对象. 其实就是从根节点扫描,只要这个对象在引用链中,那就是可触及的. 可恢复的 Java对象 ...
- 21. CTF综合靶机渗透(十四)
靶机说明: I created this machine to help others learn some basic CTF hacking strategies and some tools. ...