Spark最简安装
该环境适合于学习使用的快速Spark环境,采用Apache预编译好的包进行安装。而在实际开发中需要使用针对于个人Hadoop版本进行编译安装,这将在后面进行介绍。
Spark预编译安装包下载——Apache版
下载地址:http://spark.apache.org/downloads.html (本例使用的是Spark-2.2.0版本)
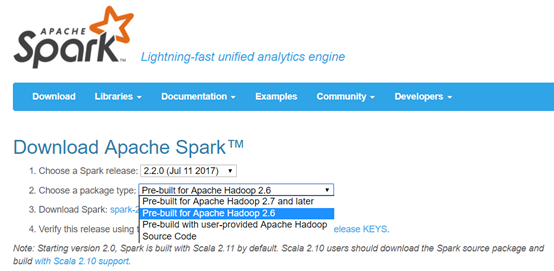
接下来依次执行下载,上传,然后解压缩操作。
[hadoop@masternode ~]$ cd /home/hadoop/app
[hadoop@masternode app]$ rz //上传
选中刚才下载好的Spark预编译好的包,点击上传。
[hadoop@masternode app]$ tar –zxvf spark-2.2.0-bin-hadoop2.6.tgz //解压
[hadoop@masternode app]$ rm spark-2.2.0-bin-hadoop2.6.tgz
[hadoop@masternode app]$ mv spark-2.2.0-bin-hadoop2.6/ spark-2.2.0 //重命名
[hadoop@masternode app]$ ll
total 24
drwxrwxr-x. 7 hadoop hadoop 4096 Aug 23 16:32 elasticsearch-2.4.0
drwxr-xr-x. 10 hadoop hadoop 4096 Apr 20 13:59 hadoop
drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60
drwxrwxr-x. 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64
drwxr-xr-x. 12 hadoop hadoop 4096 Jul 1 2017 spark-2.2.0
drwxr-xr-x. 14 hadoop hadoop 4096 Apr 19 10:00 zookeeper
[hadoop@masternode app]$ cd spark-2.2.0/
[hadoop@masternode spark-2.2.0]$ ll
total 104
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 bin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 conf
drwxr-xr-x. 5 hadoop hadoop 4096 Jul 1 2017 data
drwxr-xr-x. 4 hadoop hadoop 4096 Jul 1 2017 examples
drwxr-xr-x. 2 hadoop hadoop 12288 Jul 1 2017 jars
-rw-r--r--. 1 hadoop hadoop 17881 Jul 1 2017 LICENSE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 licenses
-rw-r--r--. 1 hadoop hadoop 24645 Jul 1 2017 NOTICE
drwxr-xr-x. 6 hadoop hadoop 4096 Jul 1 2017 python
drwxr-xr-x. 3 hadoop hadoop 4096 Jul 1 2017 R
-rw-r--r--. 1 hadoop hadoop 3809 Jul 1 2017 README.md
-rw-r--r--. 1 hadoop hadoop 128 Jul 1 2017 RELEASE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 sbin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 yarn
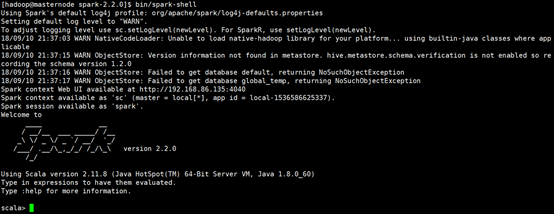
如图所示,可以进入Spark Shell模式,表示安装正常。
Spark目录介绍
1.bin 运行脚本目录
beeline
find-spark-home
load-spark-env.sh //加载spark-env.sh中的配置信息,确保仅会加载一次
pyspark //启动python spark shell,./bin/pyspark --master local[]
run-example //运行example
spark-class //内部最终变成用java运行java类
sparkR
spark-shell //启动scala spark shell,./bin/spark-shell --master local[]
spark-sql
spark-submit //提交作业到master
运行example
# For Scala and Java, use run-example:
./bin/run-example SparkPi
# For Python examples, use spark-submit directly:
./bin/spark-submit examples/src/main/python/pi.py
# For R examples, use spark-submit directly:
./bin/spark-submit examples/src/main/r/dataframe.R2.conf
docker.properties.template
fairscheduler.xml.template
log4j.properties.template //集群日志模版
metrics.properties.template
slaves.template //worker 节点配置模版
spark-defaults.conf.template //SparkConf默认配置模版
spark-env.sh.template //集群环境变量配置模版
3.data (例子里用到的一些数据)
graphx
mllib
streaming
4.examples 例子源码
jars
src
5.jars (spark依赖的jar包)
6.licenses (license协议声明文件)
7.python
8.R
9.sbin (集群启停脚本)
slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个shell命令
spark-config.sh //被其他所有的spark脚本所包含,里面有一些spark的目录结构信息
spark-daemon.sh //将一条spark命令变成一个守护进程
spark-daemons.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个spark命令
start-all.sh //启动master进程,以及所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-history-server.sh //启动历史记录进程
start-master.sh //启动spark master进程
start-mesos-dispatcher.sh
start-mesos-shuffle-service.sh
start-shuffle-service.sh
start-slave.sh //启动某机器上worker进程
start-slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-thriftserver.sh
stop-all.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上停止Worker进程
stop-history-server.sh //停止历史记录进程
stop-master.sh //停止spark master进程
stop-mesos-dispatcher.sh
stop-mesos-shuffle-service.sh
stop-shuffle-service.sh
stop-slave.sh //停止某机器上Worker进程
stop-slaves.sh //停止所有worker进程
stop-thriftserver.sh
10.yarn
spark-2.1.-yarn-shuffle.jar
Spark example
下面运行一个官网的小example。
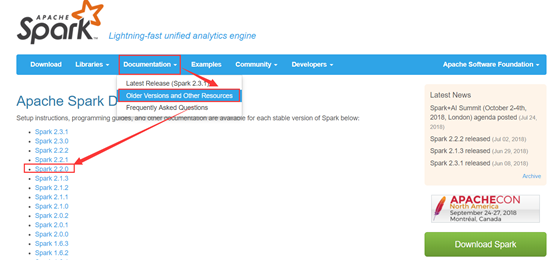
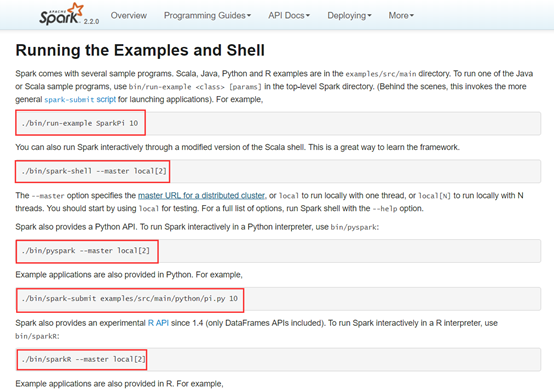
可以看到官网给出了详细的运行指令,我们运行第一个,算一下Pi的值。
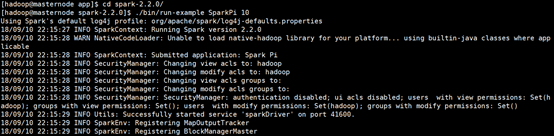
运算结果如下图所示:
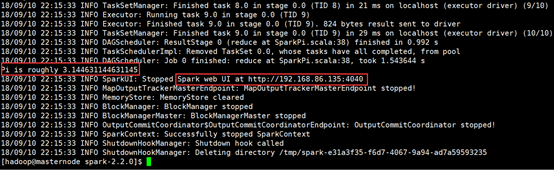
并且,如上图所示,我们可以根据图中URL地址查看web UI情况。

注意:此地址只能是在运行过程中才能查看的哦!
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Spark最简安装的更多相关文章
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- [软件开发技巧]·树莓派极简安装OpenCv
树莓派极简安装OpenCv 个人主页–> https://xiaosongshine.github.io/ 因为最近在开发使用树莓派+usb摄像头识别模块,打算用OpenCv,发现网上的树莓派O ...
- [深度学习工具]·极简安装Dlib人脸识别库
[深度学习工具]·极简安装Dlib人脸识别库 Dlib介绍 Dlib是一个现代化的C ++工具箱,其中包含用于在C ++中创建复杂软件以解决实际问题的机器学习算法和工具.它广泛应用于工业界和学术界,包 ...
- Spark学习笔记——安装和WordCount
1.去清华的镜像站点下载文件spark-2.1.0-bin-without-hadoop.tgz,不要下spark-2.1.0-bin-hadoop2.7.tgz 2.把文件解压到/usr/local ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- hadoop环境的安装 和 spark环境的安装
hadoop环境的安装1.前提:安装了java spark环境的安装1.前提:安装了java,python2.直接pip install pyspark就可以安装完成.(pip是python的软件安装 ...
随机推荐
- Poj 2853,2140 Sequence Sum Possibilities(因式分解)
一.Description Most positive integers may be written as a sum of a sequence of at least two consecuti ...
- POJ2449:K短路
Remmarguts' Date Time Limit: 4000MS Memory Limit: 65536K Total Submissions: 26355 Accepted: 7170 ...
- hdu 5600 N bulbs 想法+奇偶讨论
http://acm.hdu.edu.cn/showproblem.php?pid=5600 本文重在分析该题目的思路,代码极其短,但是想到这个题目的思路却是挺复杂的过程. 思路 自己拿到题目也想到了 ...
- 在Altium Designer 2009下如何添加Logo图
最近用Altium Designer 2013(14.2)绘制PCB,之后想在板子上放置一个LOGO图.要是用Altium Designer10以前的版本,过程也很简单,可在用Altium Desig ...
- 谷歌浏览器的input自动填充出现黄色背景解决方案(在已经输入内容之后)
当你之前提交过表单,再次获取input焦点时,会有一个记录之前填写过的文本的下拉列表式的自动填充效果且带有黄色背景, 这个填充功能本身是没什么问题的,但是谷歌浏览器给了个莫名其妙的黄色背景,用css样 ...
- 将List中部分字段转换为DataTable中
由于原来方法导出数据量比较大 的时候,出现卡顿现象:搜索简单改造:(下面方法借助NPIO) /// <summary> /// 将List中原文和译文转换为Datatable /// &l ...
- 【总结整理】JQuery基础学习---事件篇
jQuery鼠标事件之click与dbclick事件 用交互操作中,最简单直接的操作就是点击操作.jQuery提供了两个方法一个是click方法用于监听用户单击操作,另一个方法是dbclick方法用于 ...
- R中的统计模型
R中的统计模型 这一部分假定读者已经对统计方法,特别是回归分析和方差分析有一定的了解.后面我们还会假定读者对广义线性模型和非线性模型也有所了解.R已经很好地定义了统计模型拟合中的一些前提条件,因此我们 ...
- Java中的变量传递机制以及JS中的参数传递机制
JAVA: 传递基本类型是 就是基本的值传递 不会影响值本身. package com.wuqi.p1; public class ValuePassTest { public static void ...
- PAT1060【大模拟啊】
怎么麻烦怎么来了??? 提供几个案例: 5 0.00001 0.00001 0 0.0 0.0222 1 0.001 0.2000 2 005.06 0.230 1 00.020 0 贴份代码跑.. ...