Pandas数据结构(一)——Pandas Series
Pandas 是 Python 中基于Numpy构建的数据操纵和分析软件包,包含使数据分析工作变得快速简洁的高级数据结构和操作工具。通过Pandas Series 和 Pandas DataFrame这两个数据结构,我们可以轻松直观地处理带标签数据和关系数据。本节主要介绍Pandas Series的基本使用。
Pandas Series
Pandas Series是一种类似于数组的一维对象,可以存储不同类型的数据。其中,Series对象的数据存在一组与之关联的数据标签(索引),通过Series的values和index能够获取其数组表示形式和索引对象。你可以为Pandas Series 中的每个元素指定索引,并通过索引选取Series中的单个或一组值。
首先,在 Python 中导入 Pandas,通常使用pd导入 Pandas。
import pandas as pd
使用 pd.Series(data, index) 命令创建 Pandas Series, index 是一个索引标签列表。
我们创建 一个Pandas Series 对象来存储商品信息,其中单价为数据,商品名为索引标签。
import pandas as pd
goods = pd.Series(data = [39,8,15], index = ['pen', 'ice cream', 'notebook'])
goods
运行结果:

如果不指定索引标签,则默认索引从0开始。
import pandas as pd
words = pd.Series(data = ['a','b','c','d'])
words

我们还可以单独输出 Pandas Series 的索引标签和数据来查看详细内容。
print('商品单价:', goods.values)
print('商品名:', goods.index)
运行结果:
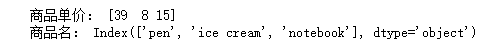
如果你不清楚是否存在某个索引标签,可以使用 in命令来判断该标签是否存在:
aa = 'notebook' in goods
bb = 'milk' in goods
cc = 'pen' in goods
print(aa,bb,cc)
运行结果:
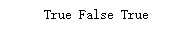
Pandas Series 的算术运算
还是使用上面存储商品信息的实例,我们来对其进行元素级算术运算。
print(goods + 1)
print()
print(goods - 2)
print()
print(goods * 3)
print()
print(goods / 4)
运行结果:

除此之外, 我们也可以对Series对象的部分条目应用算术运算。如下所示:
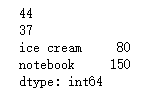
print(goods['pen'] + 5)
print(goods.iloc[0] - 2)
print(goods[['ice cream', 'notebook']] * 10)
运行结果:
Pandas数据结构(一)——Pandas Series的更多相关文章
- pandas小记:pandas高级功能
http://blog.csdn.net/pipisorry/article/details/53486777 pandas高级功能:面板数据.字符串方法.分类.可视化. 面板数据 {pandas数据 ...
- pandas 学习(1): pandas 数据结构之Series
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- pandas数据结构:Series/DataFrame;python函数:range/arange
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- pandas教程1:pandas数据结构入门
pandas是一个用于进行python科学计算的常用库,包含高级的数据结构和精巧的工具,使得在Python中处理数据非常快速和简单.pandas建造在NumPy之上,它使得以NumPy为中心的应用很容 ...
- pandas数据结构练习题(部分)
更多函数查阅http://pandas.pydata.org/pandas-docs/stable/10min.htmlimport pandas as pd#两种数据结构from pandas im ...
- Pandas数据结构
Pandas处理以下三个数据结构 - 系列(Series) 数据帧(DataFrame) 面板(Panel) 这些数据结构构建在Numpy数组之上,这意味着它们很快. 维数和描述 考虑这些数据结构的最 ...
- 数据分析——Pandas的用法(Series,DataFrame)
我们先要了解,pandas是基于Numpy构建的,pandas中很多的用法和numpy一致.pandas中又有series和DataFrame,Series是DataFrame的基础. pandas的 ...
- python之pandas学习笔记-pandas数据结构
pandas数据结构 pandas处理3种数据结构,它们建立在numpy数组之上,所以运行速度很快: 1.系列(Series) 2.数据帧(DataFrame) 3.面板(Panel) 关系: 数据结 ...
- python数据结构:pandas(2)数据操作
一.Pandas的数据操作 0.DataFrame的数据结构 1.Series索引操作 (0)Series class Series(base.IndexOpsMixin, generic.NDFra ...
随机推荐
- RocketMQ的生产者和消费者
生产者: /** * 生产者 */ public class Provider { public static void main(String[] args) throws MQClientExce ...
- Oracle 12c 如何在 PDB 中添加 SCOTT 模式(数据泵方式)
Oracle 12c 建库后,没有 scott 模式,本篇使用数据泵方式,在12c版本之前数据库中 expdp 导出 scott 模式,并连接 12c 的 pdb 进行 impdp 导入. 目录 1. ...
- CSS 美化网页元素
一.为什么使用CSS 1.有效的传递页面信息 2.使用CSS美化过的页面文本,使页面漂亮.美观,吸引用户 3.可以很好的突出页面的主题内容,使用户第一眼可以看到页面主要内容 4.具有良好的用户体验 二 ...
- vue自学入门-4(vue slot)
vue自学入门-1(Windows下搭建vue环境) vue自学入门-2(vue创建项目) vue自学入门-3(vue第一个例子) vue自学入门-4(vue slot) vue自学入门-5(vuex ...
- sift代码实现详解
1.创建高斯金字塔第-1组 1.1.将源图片转成灰度图 void ConvertToGray(const Mat& src, Mat& dst) { cv::Size size = s ...
- Mysql-从库只读设置
主从设置中,如果从库在my.cnf中使用init_connect来限制只读权限的话,从库使用非超级用户(super权限)登陆数据时,无法进行任何操作,仅可维持主从复制. init_connect='S ...
- 【python&pycharm的安装使用】
一.Python3.7安装 1. 运行python3.7.exe 2. 检查是否安装成功:命令窗口输入python -V 二.Pycharm安装 1. 运行pycharm.exe(社区版) 2. 配置 ...
- [TJOI2007] 路标设置 - 二分答案,贪心
考虑到答案满足可二分性,段内可以贪心,所以暴力二分即可 注意-1 详见代码(我这题都能写WA) #include <bits/stdc++.h> using namespace std; ...
- [ZJOI2007] 仓库建设 - 斜率优化dp
大脑真是个很优秀的器官,做事情之前总会想着这太难,真的逼着自己做下去,回头看看,其实也不过如此 很朴素的斜率优化dp了 首先要读懂题目(我的理解能力好BUG啊) 然后设\(dp[i]\)表示处理完前\ ...
- Python-selenium,使用SenKey模块时所碰到的坑
一.SenKey模块(模拟鼠标键盘操作) :python3中没有该模块,使用PyUserInput模块代替 二.PyUserInput模块安装前需要安装:pywin32和pyHook模块,pywin3 ...