python调用scikit-learn机器学习
不支持深度学习和强化学习
numpy介绍:
np.eye(n)生成一个n维单元数组
数据预处理:
iris数据加载
|
from sklearn import datasets |
数据展示
显示iris的信息
| print(iris.data) |
[[5.1 3.5 1.4 0.2] |
每列数据表示不同样本同一属性下对用的数值
| print(iris.feature_names) |
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] |
输出目标结果
| print(iris.target) |
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 |
结果的含义
| print(iris.target_names) |
['setosa' 'versicolor' 'virginica'] |
确认数据类型
|
print(type(iris.data)) |
<class 'numpy.ndarray'> |
确认维度
|
print(iris.data.shape) print(iris.target.shape) |
(150, 4) (150,) |
X输入数据赋值,y输出数据赋值
|
X = iris.data |
模型训练:
分类:根据数据集目标的特征或属性,划分到已有的类别中
常用分类算法:KNN(K近邻)、逻辑回归、决策树、朴素贝叶斯
KNN(最简单的机器学习算法之一):
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的l个实例,这k个实例多数是什么类型就将该输入实例分类到这个类中
模型调用
| from sklearn.neighbors import KNeighborsClassifier |
创建实例
| knn=KNeighborsClassifier(n_neighbors=5) |
模型训练
模型训练与预测
|
y_pred=knn.fit(X,y) |
准确率
|
from sklearn.metrics import accuracy_score |
数据分离
|
from sklearn.model_selection import train_test_split #训练输入数据,预测的输入数据,训练结果,预测结果 |
分离后数据集的训练与评估
|
knn_5_s = KNeighborsClassifier(n_neighbors=5) |
确定k值
|
k_range=list(range(1,26)) score_train=[] |
图形展示
| import matplotlib.pyplot as plt %matplotlib inline #展示k值与训练数据集预测准确率之间的关系 plt.plot(k_range,score_test) plt.xlabel('K(KNN model)') plt.ylabel('Training Accuracy') |
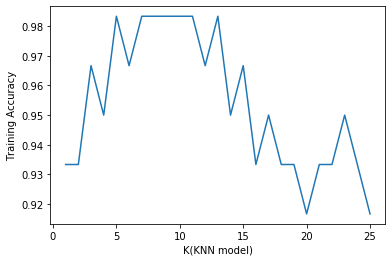
- 训练数据集准确率 随着模型复杂而提高
- 测试数据集准确率 在模型过于简单或复杂而准确率更低
- KNN模型中,模型复杂度由K决定,(k越小,复杂度越高)
对新数据进行预测
|
knn_11=KNeighborsClassifier(n_neighbors=11) |
逻辑回归模型:
用于解决分类问题的一种模型。根据数据特征或属性,计算其归属于每一类别的概率P(x),根据概率数值判断其所属类别。主要应用场景:二分类问题。
P(x)=1/(1+e-(ax+b)) y={1, P(x)≥0.5 0,P(x)<0.5
其中y为类别结果,P为概率,x为特征值,a、b为常量
(皮马印第安人糖尿病数据集)
输入变量:独立变量包括患者的怀孕次数,葡萄糖量,血压,皮褶厚度,体重指数,胰岛素水平,糖尿病谱系功能,年龄
输出结果:是否含义糖尿病
数据来源:Pima Indians Dianbetes dataset
预测准确率的局限性:
无法真实反映模型针对各个分类的预测准确度
准确率可以方便的用于衡量模型的整体预测效果,但无法反应细节信息,具体表现:
- 没有体现数据的实际分布情况
- 没有体现模型错误预测的类型
空准确率:当模型总是预测比例较高的类别,其预测准确率的数值
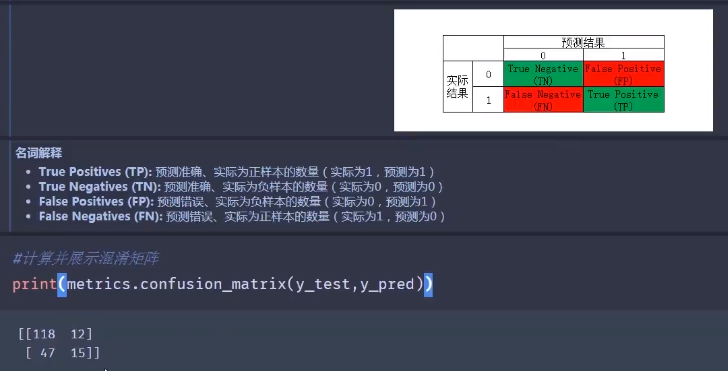
混淆矩阵(误差矩阵):
用于衡量分类算法的准确程度
- True Positives(TP):预测准确、实际为正样本的数量(实际为1,预测为1)
- True Negatives(TN):预测准确、实际为负样本的数量(实际为0,预测为0)
- False Positives(FP):预测错误、实际为负样本的数量(实际为0,预测为1)
- False Negatives(FN):预测错误、实际为正样本的数量(实际为1,预测为0)
| 公式 | 定义 | |
|
准确率 (Accuracy) |
|
整体样本中,预测正确的比例 |
|
错误率 (Misclassification Rate) |
|
整体样本中,预测错误的比例 |
|
召回率 (Recall) |
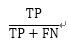 |
正样本中,预测正确的比例 |
|
特异度 (Specificity) |
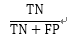 |
负样本中,预测正确的比例 |
|
精确率 (Precision) |
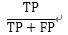 |
预测结果为正样本中,预测正确的比例 |
|
F1分数 (F1 Score) |
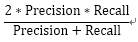 |
综合Precision和Recall的判断指标 |
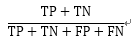
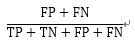
混淆矩阵指标特点:
- 分类任务中,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信息
- 通过混淆矩阵,我们可以计算出多样性的模型表现衡量指标,从而更好地选择模型
哪个衡量指标更关键?
- 衡量指标的选择取决于应用场景
- 垃圾邮件检测(正样本判断为“垃圾邮件”):希望普通邮件(负样本)不要被判断为垃圾邮件(正样本),需要关注精确率和召回率
- 异常交易检测(正样本为“异常交易”):希望所有的异常交易都被检测到,需要关注特异度
|
#数据预处理 import pandas as pd path='csv文件路径/xxx.csv' pima=pd.read_csv(path) #X,y赋值 feature_names=['pregnant','insulin','bmi','age'] X=pima[feature_names] y=pima.label #维度确认 print(X.shape,y.shape) #数据分离 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0) #模型训练 from sklearn.linear_model import LogisticRegression logreg=LogisticRegression() logreg.fit(X_train,y_train) #测试数据集结果预测 y_pred=logreg.predict(X_test) #使用准确率进行评估 from sklearn import metrics print(metrics.accuracy_score(y_test,y_pred)) #确认正负样本数据量 y_test.value_counts() #1的比例 y_test.mean() #0的比例 1-y_test.mean() #空准确率 max(y_test.mean(),1-y_test.mean()) |
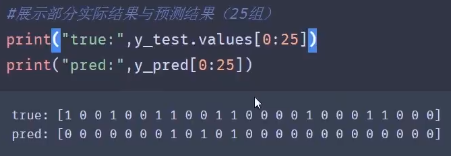
|
#四个因子赋值 cofusion=metrics.confusion_matrix(y_test,y_pred) TN=confusion[0,0] FP=confusion[0,1] FN=confusion[1,0] TP=confusion[1,1] print(TN,FP,FN,TP) /*指标计算参见上面的公式*/ |
python调用scikit-learn机器学习的更多相关文章
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码) Python 被称为是最接近 AI 的语言.最近一位名叫Anna-Lena Popkes的小姐姐在GitHub上分享了自己如何使用P ...
- Python大数据与机器学习之NumPy初体验
本文是Python大数据与机器学习系列文章中的第6篇,将介绍学习Python大数据与机器学习所必须的NumPy库. 通过本文系列文章您将能够学到的知识如下: 应用Python进行大数据与机器学习 应用 ...
- 蓝奏云数值验证码识别,python调用虹鱼图灵识别插件,超高正确率
识别验证码一直是本人想要做的事情,一直在接触按键精灵,了解到有一个虹鱼图灵识别插件专门做验证码和图像识别,原理就是图片处理和制作字库识别,制作字库我一直觉得很麻烦,工程量太大.不管怎样,它能用能达到我 ...
- 【初学python】使用python调用monkey测试
目前公司主要开发安卓平台的APP,平时测试经常需要使用monkey测试,所以尝试了下用python调用monkey,代码如下: import os apk = {'j': 'com.***.test1 ...
- python调用py中rar的路径问题。
1.python调用py,在py中的os.getcwd()获取的不是py的路径,可以通过os.path.split(os.path.realpath(__file__))[0]来获取py的路径. 2. ...
随机推荐
- leetcode-第11场双周赛-5089-安排会议日程
题目描述: 自己的提交: class Solution: def minAvailableDuration(self, slots1: List[List[int]], slots2: List[Li ...
- 线程池 一 ThreadPoolExecutor
java.util.concurrent public class ThreadPoolExecutor extends AbstractExecutorService ThreadPoolExecu ...
- Ruby 中文编码
Ruby 中文编码 前面章节中我们已经学会了如何用 Ruby 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会 ...
- NX二次开发-NXOPEN自动切换到工程图模块
UFUN的API里是没有切换到工程图的函数的,NXOPEN里是有方法可以用的.不过应该是不支持NX9以下的版本. NX9的不能录制出来,在UI类里有方法 NX9+VS2012 #include < ...
- 标准H.460公私网穿越视频解决方案
一.概述 H.460协议是一种网络通信协议,主要用于音视频的网络穿越,可以解决客户私网到公网,以及公网到私网的互相通信. 大连羽化集团是中国较大的零售业集团之一.目前羽化集团百货店已达20多家,营业面 ...
- (转)JAVA国际化
转:http://www.cnblogs.com/jjtech/archive/2011/02/14/1954291.html 国际化英文单词为:Internationalization,又称I18N ...
- python 使用abc实现接口类/虚类(2.2)
python 使用abc实现接口类/虚类 具体类 class BaseA: def run(self): print('base A running') class ChildA(BaseA): de ...
- CSS3:CSS3 渐变(Gradients)
ylbtech-CSS3:CSS3 渐变(Gradients) 1.返回顶部 1. CSS3 渐变(Gradients) CSS3 渐变(gradients)可以让你在两个或多个指定的颜色之间显示平稳 ...
- jdk linux配置
用文本编辑器打开/etc/profile 在profile文件末尾加入: export JAVA_HOME=/usr/share/jdk1.6.0_14 export PATH=$JAVA_HOME/ ...
- webstorm快捷键、支持vue文件等部分使用技巧
转载:https://www.cnblogs.com/seven077/p/9771474.html 1.常用快捷键 shift+↑ 向上选取代码块shift+↓ 向下选取代码块ctrl+/ 注释/取 ...