spark实验(四)--RDD编程(1)
一、实验目的
(1)熟悉 Spark 的 RDD 基本操作及键值对操作;
(2)熟悉使用 RDD 编程解决实际具体问题的方法。
二、实验平台
操作系统:centos6.4
Spark 版本:1.5.0
三、实验内容
实验一:
1.spark-shell 交互式编程
请到本教程官网的“下载专区”的“数据集”中下载 chapter5-data1.txt,该数据集包含 了某大学计算机系的成绩,数据格式如下所示:

首先开始我们的第一步,打开linux系统中的终端。
请根据给定的实验数据,在 spark-shell 中通过编程来计算以下内容:
将Data01.txt文件放置在usr/local/sparkdata/中
新建/usr/local/sparkdata文件夹
mkdir /usr/local/sparkdata
将Data01.txt文件放置在sparkdata中
发现权限不够,给/usr/local/sparkdata赋予操作权限
chmod 777 /usr/local/spakrdata
之后将Data01.txt文件移动到sparkdata中
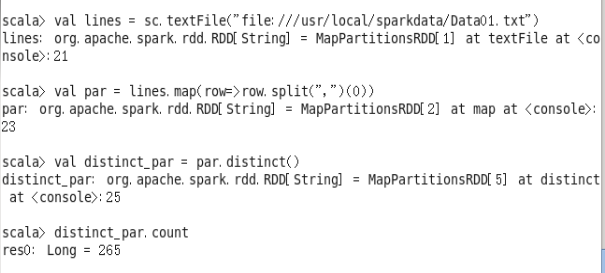
(1)该系总共有多少学生;
val lines = sc.textFile("file:///usr/local/sparkdata/Data01.txt")
val par = lines.map(row=>row.split(",")(0))
val distinct_par = par.distinct()
distinct_par.count
(2)该系共开设来多少门课程;
val lines = sc.textFile("file:///usr/local/sparkdata/Data01.txt")
val par = lines.map(row=>row.split(",")(1))
val distinct_par = par.distinct()
distinct_par.count

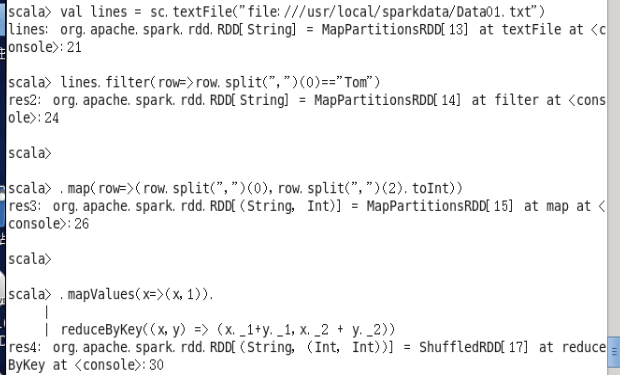
(3)Tom 同学的总成绩平均分是多少;
val lines = sc.textFile("file:///usr/local/sparkdata/Data01.txt")
lines.filter(row=>row.split(",")(0)=="Tom")
.map(row=>(row.split(",")(0),row.split(",")(2).toInt))
.mapValues(x=>(x,1)).
reduceByKey((x,y) => (x._1+y._1,x._2 + y._2))
.mapValues(x => (x._1 / x._2))
.collect()

(4)求每名同学的选修的课程门数;
val line=sc.textFile("file:///usr/local/sparkdata/Data01.txt")
line.map(row=>(row.split(",")(0),row.split(",")(1))).
mapValues(x=>(1)).
reduceByKey((x,y)=>(x+y)).
collect()

(5)该系 DataBase 课程共有多少人选修;
val line=sc.textFile("file:///usr/local/sparkdata/Data01.txt")
line.filter(row=>row.split(",")(1)=="DataBase").
count()

(6)各门课程的平均分是多少;
val line=sc.textFile("file:///usr/local/sparkdata/Data01.txt")
line.map(row=>(row.split(",")(1),row.split(",")(2).toInt)).
mapValues(x=>(x,1)).
reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).
mapValues(x=>(x._1/x._2)).
collect()

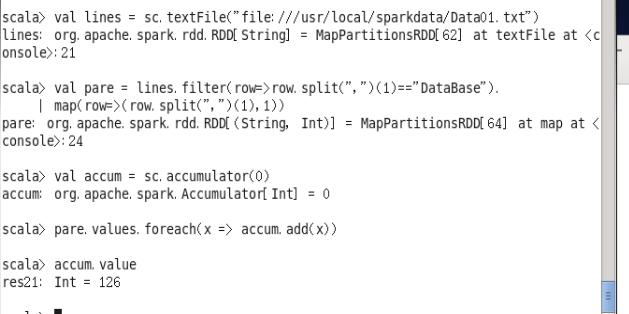
(7)使用累加器计算共有多少人选了 DataBase 这门课。
val lines = sc.textFile("file:///usr/local/sparkdata/Data01.txt")
val pare = lines.filter(row=>row.split(",")(1)=="DataBase").
map(row=>(row.split(",")(1),1))
val accum =sc.accumulator(0)
pare.values.foreach(x => accum.add(x))
accum.value
实验二
2.编写独立应用程序实现数据去重
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的一个样例,供参考。 输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
package sn
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner object RemDup
{
def main(args:Array[String])
{
val conf = new SparkConf().setAppName("RemDup")
val sc = new SparkContext(conf)
val dataFile = "file:///usr/local/sparkdata/data42"
val data = sc.textFile(dataFile,)
val res = data.filter(_.trim().length>).map(line=>(line.trim,"")).partitionBy(new HashPartitioner()).groupByKey().sortByKey().keys
res.saveAsTextFile("result")
}
}
实验三
3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生 名字,第二个是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到 一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm 成绩:
小明 92
小红 87
小新 82
小丽 90
Database 成绩:
小明 95
小红 81
小新 89
小丽 85
Python 成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner object AvgScore
{
def main(args:Array[String])
{
val conf = new SparkConf().setAppName("AvgScore")
val sc = new SparkContext(conf)
val dataFile = "file:///usr/local/spark/mycode/avgscore/data"
val data = sc.textFile(dataFile,3)
val res=data.filter(_.trim().length>0).map(line=>(line.split(" ")(0).trim(),line.split(" ")(1).trim().toInt)).partitionBy(new HashPartitioner(1)).groupByKey().map(x=>{
var n=0
var sum=0.0
for(i<-x._2){
sum=sum+i
n=n+1
}
val avg=sum/n
val format=f"$avg%1.2f".toDouble
(x._1,format)
})
res.saveAsTextFile("result2")
}
}
spark实验(四)--RDD编程(1)的更多相关文章
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Spark学习笔记——RDD编程
1.RDD——弹性分布式数据集(Resilient Distributed Dataset) RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD.转换已有的RDD和调用RDD操作 ...
- 实验4 RDD编程初级实践
1.spark-shell交互式编程 (1) 该系总共有多少学生 scala> val lines = sc.textFile("file:///usr/local/spark/spa ...
- Spark学习(2) RDD编程
什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.弹性.里面的元素可并行计算的集合 RDD允 ...
- 假期学习【四】RDD编程实验一
1.今天把Spark编程第三个实验的Scala独立程序编程写完了.使用 sbt 打包 Scala 程序,然后提交到Spark运行. 2.完成了实验四的第一项 (1)该系总共有多少学生: map(t ...
- 假期学习【五】RDD编程实验四
今天完成了实验四的第二问和第三问 第二题 对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C.下面是输入文件和输出文件的一个样 ...
随机推荐
- Web API入参,响应规范
入参绑定 入参应该定义成实体,而不是多个参数,方便扩展.[FromBody]和[FromUrl]特性也最好加上. public ActionResult<Pet> Create([From ...
- 题解【洛谷P1315】[NOIP2011]观光公交
题目描述 风景迷人的小城 Y 市,拥有 \(n\) 个美丽的景点.由于慕名而来的游客越来越多,Y 市特意安排了一辆观光公交车,为游客提供更便捷的交通服务. 观光公交车在第 \(0\) 分钟出现在 \( ...
- 题解【CJOJ1236】【复赛】指数序列求和
P1236 - [复赛]指数序列求和 Description 求1^b+2^b+…+a^b的和除以10000的余数. Input 第一行包含一个正整数N,表示有N组测试数据接下来N行每行包含两个正整数 ...
- Shell脚本命令汇总中
一.换行 echo -e 可以通过\n编译换行 echo -n不换行,如果加入了\n,则会打出“\n”字符 #!/bin/bash echo -e "O\nK\n!" echo & ...
- git上传时出现ERROR: Repository not found.的解决办法
今天在上传时出现错误,原因是之前更改了gitee上的个人空间地址,导致找不到.需要重新配置 https://gitee.com/help/articles/4114#article-header0
- drf大总结
接口 """ 1.什么是接口:url+请求参数+响应数据 | 接口文档 2.接口规范: url:https,api,资源(名词复数),v1,get|post表示操作资源的 ...
- 教你如何用python和pygame制作一个简单的贪食蛇游戏,可自定义
1.效果图 2.完整的代码 #第1步:导出模块 import pygame, sys, random from pygame.locals import * # 第2步:定义颜色变量,在pygame中 ...
- VIM - 问题: 简单变换
1. 概述 学习 Java 反射的时候, 碰到的简单问题 手动可以处理, 但是真的很浪费时间 想熟悉一下工具的使用 2. 题目 源 Modifier.isAbstract(int modifiers) ...
- Git - 后续
1. 概述 现在讲了这些, 也就能应付一下日常的单机操作 后续大概会讲这些内容 分之间的 merge 本地仓库与远程仓库的互动
- Linux源码编译安装nginx
ps:一切从简 一.安装所需环境: yum -y install gcc gcc-c++ automake pcre pcre-devel zlip zlib-devel openssl openss ...