对Hadoop分布式文件系统HDFS的操作实践
原文地址:https://dblab.xmu.edu.cn/blog/290-2/
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,如果已经安装了Hadoop,其中就已经包含了HDFS组件,不需要另外安装。
在学习HDFS编程实践前,执行如下命令,启动Hadoop。

一、利用Shell命令与HDFS进行交互
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
有三种shell命令方式。
1. hadoop fs 适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
2. hadoop dfs 只能适用于HDFS文件系统
3. hdfs dfs 只能适用于HDFS文件系统
我们可以在终端输入如下命令,查看fs总共支持了哪些命令

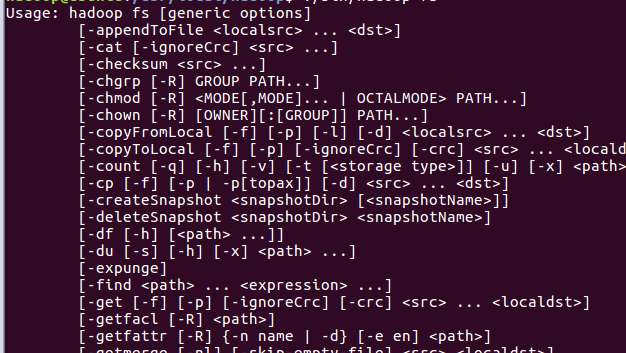
1.目录操作
需要注意的是,Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录。本教程全部采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,命令如下:

该命令中表示在HDFS中创建一个“/user/hadoop”目录,“–mkdir”是创建目录的操作,“-p”表示如果是多级目录,则父目录和子目录一起创建,这里“/user/hadoop”就是一个多级目录,因此必须使用参数“-p”,否则会出错。
“/user/hadoop”目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:


该命令中,“-ls”表示列出HDFS某个目录下的所有内容,“.”表示HDFS中的当前用户目录,也就是“/user/hadoop”目录,因此,上面的命令和下面的命令是等价的:

如果要列出HDFS上的所有目录,可以使用如下命令:

下面,可以使用如下命令创建一个input目录:


在创建input目录时,采用了相对路径形式,实际上,这个input目录创建成功以后,它在HDFS中的完整路径是“/user/hadoop/input”。
如果要在HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:

可以使用rm命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的“/input”目录(不是“/user/hadoop/input”目录):

上面命令中,“-r”参数表示如果删除“/input”目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用“-r”参数,否则会执行失败。
2.文件操作
在实际应用中,经常需要从本地文件系统向HDFS中上传文件,或者把HDFS中的文件下载到本地文件系统中。
首先,使用vim编辑器,在本地Linux文件系统的“~/hadoop/”目录下创建一个文件myLocalFile.txt,里面可以随意输入一些单词,比如,输入如下三行:

然后,可以使用如下命令把本地文件系统的“~/hadoop/myLocalFile.txt”上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的“/user/hadoop/input/”目录下:


可以使用ls命令查看一下文件是否成功上传到HDFS中,具体如下:

下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:

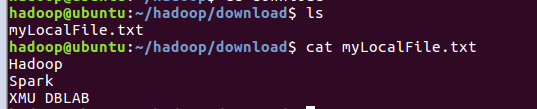
下面把HDFS中的myLocalFile.txt文件下载到本地文件系统中的“~/hadoop/download/”这个目录下,命令如下:


可以使用如下命令,到本地文件系统查看下载下来的文件myLocalFile.txt:
最后,了解一下如何把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录。比如,如果要把HDFS的“/user/hadoop/input/myLocalFile.txt”文件,拷贝到HDFS的另外一个目录“/input”中(注意,这个input目录位于HDFS根目录下),可以使用如下命令:


二、利用Web界面管理HDFS
打开Linux自带的Firefox浏览器,点击此链接 http://localhost:50070 ,即可看到HDFS的web管理界面。

三、利用Java API与HDFS进行交互
Hadoop不同的文件系统之间通过调用Java API进行交互,上面介绍的Shell命令,本质上就是Java API的应用。下面提供了Hadoop官方的Hadoop API文档,想要深入学习Hadoop,可以访问如下网站,查看各个API的功能。
http://hadoop.apache.org/docs/stable/api/
(一) 在Ubuntu中安装Eclipse
选择“File->New->Java Project”菜单,开始创建一个Java工程,
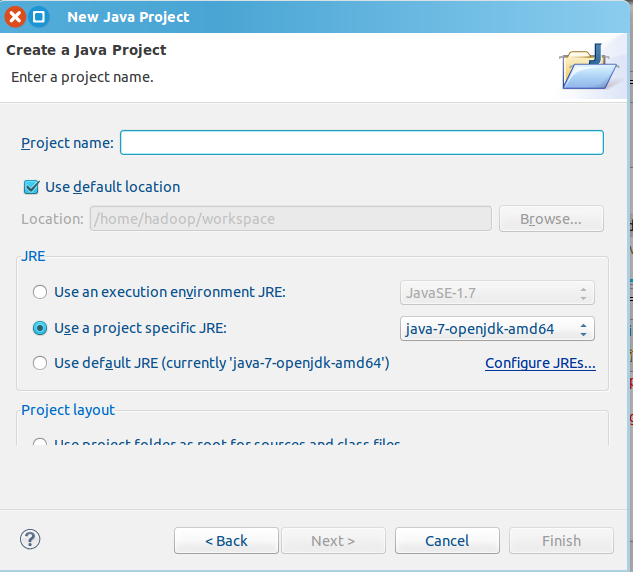
在“Project name”后面输入工程名称“HDFSExample”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/HDFSExample”目录下。
在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如java-7-openjdk-amd64。然后,点击界面底部的“Next>”按钮,进入下一步的设置。(二)为项目添加需要用到的JAR包

需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,
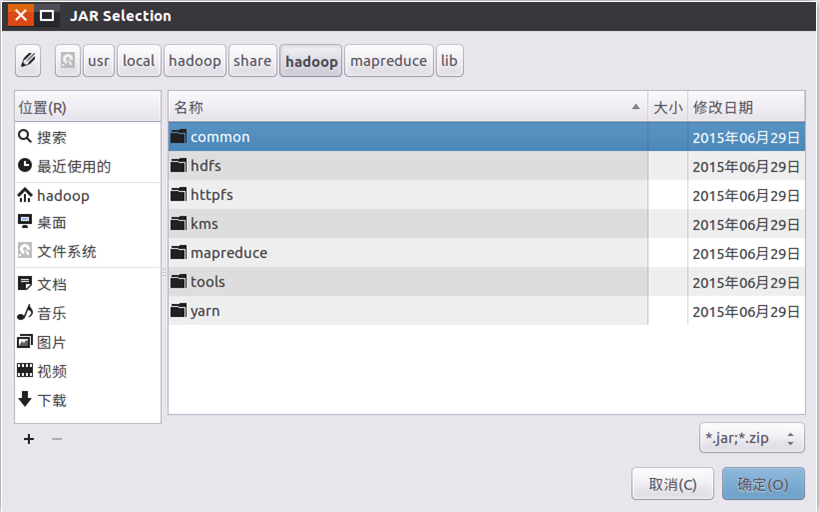
在该界面中,上面的一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce”和“lib”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程HDFSExample的创建。
对Hadoop分布式文件系统HDFS的操作实践的更多相关文章
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- Hadoop分布式文件系统--HDFS结构分析
转自:http://blog.csdn.net/androidlushangderen/article/details/47377543 HDFS系列:http://blog.csdn.net/And ...
- Hadoop 分布式文件系统 - HDFS
当数据集超过一个单独的物理计算机的存储能力时,便有必要将它分不到多个独立的计算机上.管理着跨计算机网络存储的文件系统称为分布式文件系统.Hadoop 的分布式文件系统称为 HDFS,它 是为 以流式数 ...
- Hadoop分布式文件系统HDFS
HDFS的探究: HDFS HDFS是 Hadoop Distribute File System的缩写,是谷歌GFS分布式文件系统的开源实现,Apache Hadoop的一个子项目,HDFS基于流数 ...
- CM记录-Hadoop 分布式文件系统HDFS(登录、配置、监控)
1.登录(浏览器输入ip地址:7180,登录用户名和登录密码即可) 2.CM主界面(各个组件,监控图表,绿色代表运行正常.黄色代表运行不良,需要关注根据实际情况调整,红色代表故障,需要排查问题) 3. ...
- Hadoop 分布式文件系统:架构和设计
引言 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时,它和其他的分布式文件系统 ...
- 【官方文档】Hadoop分布式文件系统:架构和设计
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html 引言 前提和设计目标 硬件错误 流式数据访问 大规模数据集 简单的一致性模型 “移动计 ...
随机推荐
- jquery自己写的幻灯片插件,好用不解释
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Python的优缺点、以及解释器种类
优点 Python起始定位“优雅”.“明确”.“简洁”,工具型语言,上手快,实用性强. 开发效率高,支持库强大,很多功能都有与之对应的最优模块支持. 高级语言,编程时无需考虑内存等底层具体实现. 可移 ...
- SPOJ - REPEATS Repeats (后缀数组)
A string s is called an (k,l)-repeat if s is obtained by concatenating k>=1 times some seed strin ...
- CentOS 7 修改root密码
1.开机,在启动菜单上选择CentOS Linux (3.10**.**.x86**) 7 (Core) 按下e,进入编辑模式2.将光标一直移动到 LANG=en_US.UTF-8 后面(如果找不到, ...
- buerdepepeqi 的模版
buerdepepeqi的模板 头文件 #include <set> #include <map> #include <deque> #include <qu ...
- 【Git】git-filter-branch - Rewrite branches
1.命令使用场景 ①Removing sensitive data from a repository(https://help.github.com/en/github/authenticating ...
- 错误 1 未能找到类型或命名空间名称“”, 引入DLL文件出现提示文件不存在问题
在所有引入都正确的情况下,查看项目目标框架是否正确
- vagrant在windows下的安装和配置(二)
在(一)中安装和配置好后 框框中的信息是登录vagrant up后的系统用的 我这里登录用的是xshell-----下载一个xshell然后安装 打开xshell 按确定之后生成一个新的会话,然后登录 ...
- VUE事件修饰符.passive、.capture、.once实现原理——重新认识addEventListener方法
https://www.jianshu.com/p/b12d0d3ad4c1 .passive的作用与使用场景 https://juejin.im/post/5ad804c1f265da504547f ...
- ELK学习实验013:ELK的一个完整的配置操作
前面做了关于ELK组件的各个实验,但是并没有真正的把各个组件结合起来做一个实验,现在使用一个脚本简单的生成日志,模拟生产不断产生日志的效果 一 流程说明 使用脚本产生日志,模拟用户的操作 日志的格式 ...