[Erlang 0107] Erlang实现文本截断
> string:substr("abcd我们就是喜欢Erlang,就是喜欢OTP",,).
[,,]
> io:format("~ts",[v()]).
d我们ok
Eshell V5.10.2 (abort with ^G)
> u:sub().
[,,]
> io:format("~ts",[v()]).
dæok
> q().
ok
>
%% coding: utf-
Eshell V5.10.2 (abort with ^G)
> u:sub().
[,,]
> io:format("~ts",[v()]).
d我们ok
-define(DEFAULT_ENCODING, latin1). -spec default_encoding() -> source_encoding(). default_encoding() ->
?DEFAULT_ENCODING. -spec encoding_to_string(Encoding) -> string() when
Encoding :: source_encoding(). encoding_to_string(latin1) -> "coding: latin-1";
encoding_to_string(utf8) -> "coding: utf-8".
The Erlang source file encoding is selected by a comment in one of the first two lines of the source file. The first string that matches the regular expression coding\s*[:=]\s*([-a-zA-Z0-9])+ selects the encoding. If the matching string is not a valid encoding it is ignored. The valid encodings are Latin-1 and UTF-8 where the case of the characters can be chosen freely.
As of Erlang/OTP R16 Erlang source files can be written in either UTF-8 or bytewise encoding (a.k.a. latin1 encoding). The details on how to state the encoding of an Erlang source file can be found in epp(3). Strings and comments can be written using Unicode, but functions still have to be named using characters from the ISO-latin-1 character set and atoms are restricted to the same ISO-latin-1 range. These restrictions in the language are of course independent of the encoding of the source file. Erlang/OTP R18 is expected to handle functions named in Unicode as well as Unicode atoms. http://www.erlang.org/doc/apps/stdlib/unicode_usage.html
R16B之前版本
-module(u).
-compile(export_all).
test() ->
t("abcd我们就是喜欢Erlang,就是喜欢OTP",). test2() ->
tw("Youth is not a time of life; it is a state of mind; it is not a matter of
rosy cheeks, red lips and supple knees; it is a matter of the will, a
quality of the imagination, a vigor of the emotions; it is the freshness of
the deep springs of life.",10). dump(FileName,Data)->
file:write_file(FileName, io_lib:fwrite("~s.\n", [Data])). sub()->
string:substr("abcd我们就是喜欢Erlang,就是喜欢OTP",,). t(Input,Max) ->
truncatechars(Input,Max). tw(Input,Max) ->
truncatewords(Input,Max). %% @doc Truncates a string after a certain number of characters.
truncatechars(_Input, Max) when Max =< ->
"";
truncatechars(Input, Max) when is_binary(Input) ->
list_to_binary(truncatechars(binary_to_list(Input), Max));
truncatechars(Input, Max) ->
truncatechars(Input, Max, []). %% @doc Truncates a string after a certain number of words.
truncatewords(_Input, Max) when Max =< ->
"";
truncatewords(Input, Max) when is_binary(Input) ->
list_to_binary(truncatewords(binary_to_list(Input), Max));
truncatewords(Input, Max) ->
truncatewords(Input, Max, []). truncatechars([], _CharsLeft, Acc) ->
lists:reverse(Acc);
truncatechars(_Input, , Acc) ->
lists:reverse("..." ++ Acc);
truncatechars([C|Rest], CharsLeft, Acc) when C >= # ->
truncatechars(Rest, CharsLeft + , [C|Acc]);
truncatechars([C|Rest], CharsLeft, Acc) when C >= # ->
truncatechars(Rest, CharsLeft + , [C|Acc]);
truncatechars([C|Rest], CharsLeft, Acc) when C >= # ->
truncatechars(Rest, CharsLeft + , [C|Acc]);
truncatechars([C|Rest], CharsLeft, Acc) when C >= # ->
truncatechars(Rest, CharsLeft + , [C|Acc]);
truncatechars([C|Rest], CharsLeft, Acc) when C >= # ->
truncatechars(Rest, CharsLeft, [C|Acc]);
truncatechars([C|Rest], CharsLeft, Acc) ->
truncatechars(Rest, CharsLeft - , [C|Acc]). truncatewords(Value, _WordsLeft, _Acc) when is_atom(Value) ->
Value;
truncatewords([], _WordsLeft, Acc) ->
lists:reverse(Acc);
truncatewords(_Input, , Acc) ->
lists:reverse("..." ++ Acc);
truncatewords([C1, C2|Rest], WordsLeft, Acc) when C1 =/= $\ andalso C2 =:= $\ ->
truncatewords([C2|Rest], WordsLeft - , [C1|Acc]);
truncatewords([C1|Rest], WordsLeft, Acc) ->
truncatewords(Rest, WordsLeft, [C1|Acc]).
test() ->
t("abcd我们就是喜欢Erlang,就是喜欢OTP",). dump(FileName,Data)->
file:write_file(FileName, io_lib:fwrite("~s.\n", [Data])). Eshell V5.10.2 (abort with ^G)
> u:test().
[,,,,,,,,,,,,,,,
,,,,,,,,,]
>
> u:dump("u_result",v()).
ok
>
[root@nimbus demo]# cat u_result
abcd我们就是喜欢....
|
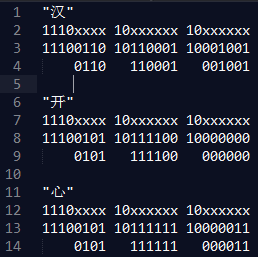
Unicode编码(16进制)
|
UTF-8 字节流模板
|
|
000000 - 00007F
|
0xxxxxxx
|
|
000080 - 0007FF
|
110xxxxx 10xxxxxx
|
|
000800 - 00FFFF
|
1110xxxx 10xxxxxx 10xxxxxx
|
|
010000 - 10FFFF
|
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
|
Eshell V5.10.2 (abort with ^G)
> unicode:characters_to_binary("开心").
<<,,,,,>>
> unicode:characters_to_list("开心").
[,]
> integer_to_list(,).
""
> integer_to_list(,).
""
> integer_to_list(,).
""
[Erlang 0107] Erlang实现文本截断的更多相关文章
- [Erlang 0124] Erlang Unicode 两三事 - 补遗
最近看了Erlang User Conference 2013上patrik分享的BRING UNICODE TO ERLANG!视频,这个分享很好的梳理了Erlang Unicode相关的问题,基本 ...
- [Erlang 0129] Erlang 杂记 VI
把之前阅读资料的时候记下的东西,整理了一下. Adding special-purpose processor support to the Erlang VM P23 简单介绍了Erlang C ...
- [Erlang 0122] Erlang Resources 2014年1月~6月资讯合集
虽然忙,有些事还是要抽时间做; Erlang Resources 小站 2014年1月~6月资讯合集,方便检索. 小站地址: http://site.douban.com/204209/ ...
- [Erlang 0105] Erlang Resources 小站 2013年1月~6月资讯合集
很多事情要做,一件一件来; Erlang Resources 小站 2013年1月~6月资讯合集,方便检索. 小站地址: http://site.douban.com/204209/ ...
- Erlang 103 Erlang分布式编程
Outline 笔记系列 Erlang环境和顺序编程Erlang并发编程Erlang分布式编程YawsErlang/OTP 日期 变更说明 2014-11-23 A Outl ...
- 解决NSTextContainer分页时文本截断问题
解决NSTextContainer分页时文本截断问题 NSTextContainer与NSLayoutManager配合使用可以将大文本文件分页,但是,分页过程中会遇到问题,显示字符被截断的问题:) ...
- [Erlang 0057] Erlang 排错利器: Erlang Crash Dump Viewer
http://www.cnblogs.com/me-sa/archive/2012/04/28/2475556.html Erlang Crash Dump Viewer真的是排错的天兵神器,还记得我 ...
- [Erlang 0119] Erlang OTP 源码阅读指引
上周Erlang讨论群里面提到lists的++实现,争论大多基于猜测,其实打开代码看一下就都明了.贴出代码截图后有同学问这代码是哪里找的? "代码去哪里找?",关于Erla ...
- [Erlang 0123] Erlang EPMD
epmd进程和Erlang节点进程如影随形,在Rabbitmq集群,Ejabberd集群,Couchbase集群产品文档中都会有相当多的内容讲epmd,epmd是什么呢? epmd 是Erlan ...
随机推荐
- MySQL分区表的管理~2
一.维护分区 对于表的维护,我们一般有如下几种方式: CHECK TABLE, OPTIMIZE TABLE, ANALYZE TABLE和REPAIR TABLE. 而这几种方式,对于分区同样适用. ...
- 基于Metronic的Bootstrap开发框架经验总结(5)--Bootstrap文件上传插件File Input的使用
Bootstrap文件上传插件File Input是一个不错的文件上传控件,但是搜索使用到的案例不多,使用的时候,也是一步一个脚印一样摸着石头过河,这个控件在界面呈现上,叫我之前使用过的Uploadi ...
- iOS chart 图表完美解决方案 基于swift
如果打算在app中使用图标功能,这个框架基本能够满足90%的需求 下边是作者的框架的下载地址 ,基于swift2.0 https://github.com/danielgindi/ios-charts ...
- IE滤镜及其使用技巧
Gradient Filter和AlphaImageLoader Filter 这两个属性是legend IE(IE6,7,8)中的渐变滤镜和透明滤镜,我们先详细介绍下这两个属性的用法,详情 可查看M ...
- WebService入门案例
关于WebService的作用和好处,大家应该都了解.但如何在Asp.Net中添加Web Service等问题一直是新手朋友的一大难题.鉴于网上没有一个像样的实际案例,特将课程设计中运用到的WebSe ...
- 在Mac上使用Visual Studio Code开发/调试.NET Core代码
.Net Core 1.0终于发布了,Core的一大卖点就是跨平台.这个跨平台不只是跨平台运行,而且可以跨平台开发.今天抽空研究了下在Mac下如何使用VS Code来开发.NET Core程序,并且调 ...
- 基于STM32Cube的DAC数模转化
1. STM32Cube配置 1.1 DAC配置 1.2 TIM6 配置 1.3 利用Cube产生工程程序,MDK打开软件 在主循环上添加语句: HAL_TIM_Base_S ...
- 好的Ui界面地址
http://121.40.148.178:8080/http://www.uimaker.com/http://www.uimaker.com/uimakerhtml/bshtml/124261.h ...
- C#~异步编程再续~await与async引起的w3wp.exe崩溃
返回目录 最近怪事又开始发生了,IIS的应用程序池无做挂掉,都指向同一个矛头,async,threadPool,Task,还有一个System.NullReferenceException,所以这些都 ...
- 背水一战 Windows 10 (37) - 控件(弹出类): MessageDialog, ContentDialog
[源码下载] 背水一战 Windows 10 (37) - 控件(弹出类): MessageDialog, ContentDialog 作者:webabcd 介绍背水一战 Windows 10 之 控 ...