Lucene使用IKAnalyzer分词
1.分析器 所有分析器最终继承的类都是Analyzer
1.1 默认标准分析器:StandardAnalyzer
在我们创建索引的时候,我们使用到了IndexWriterConfig对象,在我们创建索引的过程当中,会经历分析文档的步骤,就是分词的步骤,默认采用的标准分析器自动分词
1.1.1 查看分析器的分析效果
public static void main(String[] args) throws IOException {
//1.创建一个Analyzer对象
StandardAnalyzer analyzer = new StandardAnalyzer();
//2.调用Analyzer对象的tokenStream方法获取TokenStream对象,此对象包含了所有的分词结果
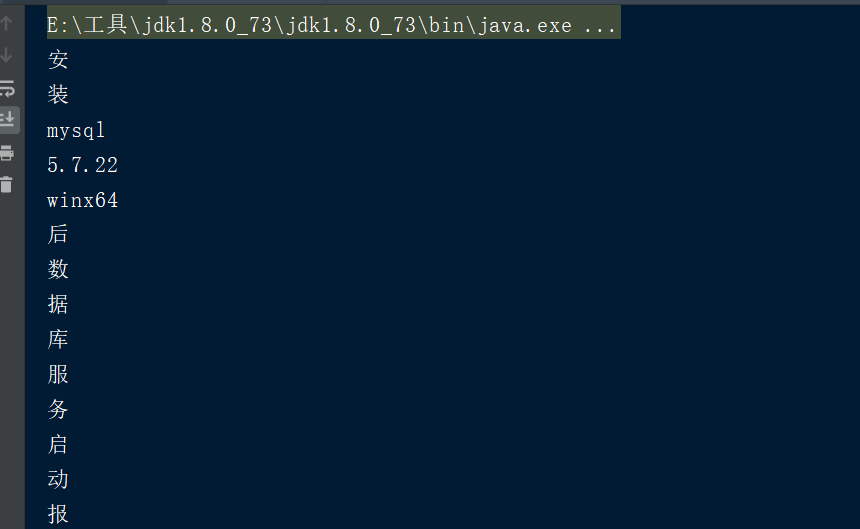
TokenStream tokenStream = analyzer.tokenStream("", "安装mysql-5.7.22-winx64后数据库服务启动报错:本地计算机上的mysql服务启动停止后,某些服务未由其他服务或程序使用时将自动停止而且mysql官网下载的压缩包解压出来没有网线上安装教... 博文 来自: 测试菜鸟在路上,呵呵");
//3.给tokenStream对象设置一个指针,指针在哪当前就在哪一个分词上
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//4.调用tokenStream对象的reset方法,重置指针,不调用会报错
tokenStream.reset();
//5.利用while循环,拿到分词列表的结果 incrementToken方法返回值如果为false代表读取完毕 true代表没有读取完毕
while (tokenStream.incrementToken()){
System.out.println(charTermAttribute.toString());
}
//6.关闭
tokenStream.close();
}
分析会去掉停用词,忽略大小写,祛除标点
默认标准分析器分析英文没有问题,但是他分析中文时会拆分成单个汉字,这显然不符合实际需求
1.2 中文分析器
第三方中文分析器:IKAnalyzer
IKAnalyzer的使用步骤:
1.导入依赖
<!-- https://mvnrepository.com/artifact/com.jianggujin/IKAnalyzer-lucene -->
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
2.配置IKAnalyzer,导入配置文件
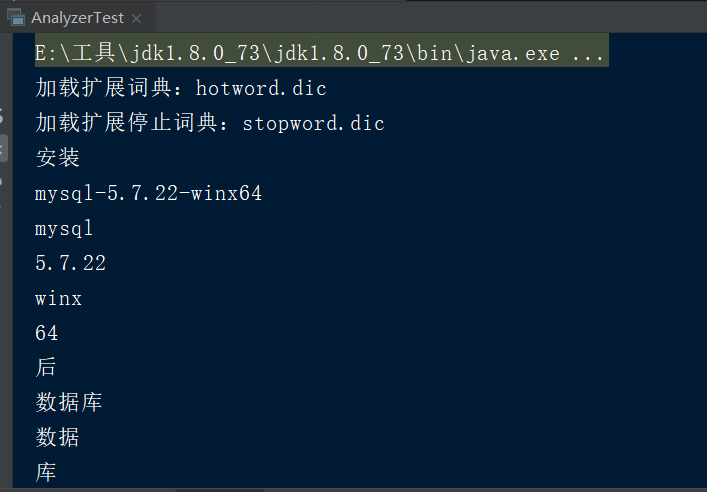
hotword.dic 扩展词典,可以将时尚的网络名词放入到该词典当中,这样就能根据扩展词典进行分词
stopword.dic 停用词词典,可以将无意义的词和敏感词汇放入到该词典当中,这样在分析的时候就会忽略这些内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">hotword.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典 词典可以有多个,每一个用;分割-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
在自定义扩展词典和停用词词典的过程当中,千万不要使用windows记事本编辑,因为windows记事本是UTF-8+BOM编码
3.使用IKAnalyzer进行分词
public static void main(String[] args) throws IOException {
//1.创建一个Analyzer对象
Analyzer analyzer=new IKAnalyzer();
//2.调用Analyzer对象的tokenStream方法获取TokenStream对象,此对象包含了所有的分词结果
TokenStream tokenStream = analyzer.tokenStream("", "安装mysql-5.7.22-winx64后数据库服务启动报错:本地计算机上的mysql服务启动停止后,某些服务未由其他服务或程序使用时将自动停止而且mysql官网下载的压缩包解压出来没有网线上安装教... 博文 来自: 测试菜鸟在路上,呵呵");
//3.给tokenStream对象设置一个指针,指针在哪当前就在哪一个分词上
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//4.调用tokenStream对象的reset方法,重置指针,不调用会报错
tokenStream.reset();
//5.利用while循环,拿到分词列表的结果 incrementToken方法返回值如果为false代表读取完毕 true代表没有读取完毕
while (tokenStream.incrementToken()){
System.out.println(charTermAttribute.toString());
}
//6.关闭
tokenStream.close();
}
得到的就是常用的单词了
4.程序当中使用IKAnalyzer
IndexWriter indexWriter=new IndexWriter(directory,new IndexWriterConfig(new IKAnalyzer()));
Lucene使用IKAnalyzer分词的更多相关文章
- Lucene使用IKAnalyzer分词实例 及 IKAnalyzer扩展词库
文章转载自:http://www.cnblogs.com/dennisit/archive/2013/04/07/3005847.html 方案一: 基于配置的词典扩充 项目结构图如下: IK分词器还 ...
- Lucene的中文分词器IKAnalyzer
分词器对英文的支持是非常好的. 一般分词经过的流程: 1)切分关键词 2)去除停用词 3)把英文单词转为小写 但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好. 国人林良益写的IK Ana ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
- Lucene学习——IKAnalyzer中文分词
一.环境 1.平台:MyEclipse8.5/JDK1.5 2.开源框架:Lucene3.6.1/IKAnalyzer2012 3.目的:测试IKAnalyzer的分词效果 二.开发调试 1.下载框架 ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- IKAnalyzer 分词
IK Analyzer 3.0特性 采用了特有的"正向迭代最细粒度切分算法",具有80万字/秒的高速处理能力 采用了多子处理器分析模式,支持:英文字母(IP地址.Email.URL ...
- solr、Lucene、IKAnalyzer这三者关系是怎样的?
lucene 是开源搜索引擎 solr 是基于 lucene开发的搜索引擎 IK 是中文分词. lucene 不是一个搜索引擎,只是一个基础的文件索引工具包,或者叫“搜索引擎开发包”.不能单独作为程序 ...
- Solr配置Ikanalyzer分词器
上一篇文章讲解在win系统中如何安装solr并创建一个名为test_core的Core,接下为text_core配置Ikanalyzer 分词器 1.打开text_core的instanceDir目录 ...
- 【盘古分词】Lucene.Net 盘古分词 实现公众号智能自动回复
盘古分词是一个基于 .net framework 的中英文分词组件.主要功能 中文未登录词识别 盘古分词可以对一些不在字典中的未登录词自动识别 词频优先 盘古分词可以根据词频来解决分词的歧义问题 多元 ...
随机推荐
- 编译出适合自己的nginx
上面是解压后的nginx源码 auto目录 上面的cc目录用于编译,lib库 os目录对系统进行判断,其他所有文件都是辅助conf脚本执行 判定nginx支持哪些模块,当前操作系统有哪些特性. CHA ...
- python学习记录(四)
0828--https://www.cnblogs.com/fnng/archive/2013/04/18/3029807.html 0828--https://www.cnblogs.com/fnn ...
- 你都这么拼了,面试官TM怎么还是无动于衷
面试,对于每个人而然并不陌生,可以说是必须经历的一个过程了,小到一场考试,大到企业面试,甚至大型选秀...... 有时自己明明很努力了,但偏偏会在面试环节出了插曲,比如,紧张就是最容易出现的了. 我相 ...
- [scrapy]安装报错: Twisted安装错误
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载whl文件 然后 pip install <whl文件名> 安装 Scrapy s ...
- CCF_201503-2_数字排序
自己写个排序的cmp. #include<iostream> #include<cstdio> #include<algorithm> using namespac ...
- HDU_4734_数位dp
http://acm.hdu.edu.cn/showproblem.php?pid=4734 模版题. #include<iostream> #include<cstdio> ...
- (二)Mybatis动态sql
首先动态sql简单来讲就是可以根据传入参数的不同来动态的生成sql语句,拼接where语句,这样你就不用写很多个sql语句了,并且它里面有一些特性也可以帮助你避免sql语句的拼接错误,主要分为4个: ...
- sublime 快捷键 【转】
Sublime Text 3 快捷键精华版 备用,方便查询 Ctrl+Shift+P:打开命令面板Ctrl+P:搜索项目中的文件Ctrl+G:跳转到第几行Ctrl+W:关闭当前打开文件Ctrl+S ...
- Unity酱~ 卡通渲染技术分析(二)
前面的话 上一篇Unity酱~ 卡通渲染技术分析(一) 写了CharaMain.cginc,服装的渲染是怎么实现的.这篇来分析一下头发跟皮肤的实现 头发 本来以为unitychan的头发会有各向异性的 ...
- JS代码格式化时间戳
一.[24小时制]yyyy-MM-dd HH:mm:ss new Date().toJSON() // 2019-12-13T13:12:32.265Z 通过上面的方法,基本就可以将日期格式化,然后稍 ...