hadoop机架感知
背景
分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群。机架内的机器之间的网络速度通常都会高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。
具体到Hadoop集群,由于hadoop的HDFS对数据文件的分布式存放是按照分块block存储,每个block会有多个副本(默认为3),并且为了数据的安全和高效,所以hadoop默认对3个副本的存放策略为:
第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本似乎放置在与第一个副本所在节点同一机架的另一个节点上
如果还有更多的副本就随机放在集群的node里。
这样的策略可以保证对该block所属文件的访问能够优先在本rack下找到,如果整个rack发生了异常,也可以在另外的rack上找到该block的副本。这样足够的高效,并且同时做到了数据的容错。
但是,hadoop对机架的感知并非是自适应的,亦即,hadoop集群分辨某台slave机器是属于哪个rack并非是只能的感知的,而是需要hadoop的管理者人为的告知hadoop哪台机器属于哪个rack,这样在hadoop的namenode启动初始化时,会将这些机器与rack的对应信息保存在内存中,用来作为对接下来所有的HDFS的写块操作分配datanode列表时(比如3个block对应三台datanode)的选择datanode策略,做到hadoop allocate block的策略:尽量将三个副本分布到不同的rack。
接下来的问题就是:通过什么方式能够告知hadoop namenode哪些slaves机器属于哪个rack?以下是配置步骤。
配置
默认情况下,hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务。
要将hadoop机架感知的功能启用,配置非常简单,在namenode所在机器的hadoop-site.xml配置文件中配置一个选项:
<property>
<name>topology.script.file.name</name>
<value>/path/to/RackAware.py</value>
</property
这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架,保存到内存的一个map中。
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址正确的映射到相应的机架上去。一个简单的实现如下:

#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys rack = {"hadoopnode-176.tj":"rack1",
"hadoopnode-178.tj":"rack1",
"hadoopnode-179.tj":"rack1",
"hadoopnode-180.tj":"rack1",
"hadoopnode-186.tj":"rack2",
"hadoopnode-187.tj":"rack2",
"hadoopnode-188.tj":"rack2",
"hadoopnode-190.tj":"rack2",
"192.168.1.15":"rack1",
"192.168.1.17":"rack1",
"192.168.1.18":"rack1",
"192.168.1.19":"rack1",
"192.168.1.25":"rack2",
"192.168.1.26":"rack2",
"192.168.1.27":"rack2",
"192.168.1.29":"rack2",
} if __name__=="__main__":
print "/" + rack.get(sys.argv[1],"rack0")
由于没有找到确切的文档说明 到底是主机名还是ip地址会被传入到脚本,所以在脚本中最好兼容主机名和ip地址,如果机房架构比较复杂的话,脚本可以返回如:/dc1/rack1 类似的字符串。
执行命令:chmod +x RackAware.py
重启namenode,如果配置成功,namenode启动日志中会输出:
2011-12-21 14:28:44,495 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/192.168.1.15:50010
网络拓扑机器之间的距离
这里基于一个网络拓扑案例,介绍在复杂的网络拓扑中hadoop集群每台机器之间的距离
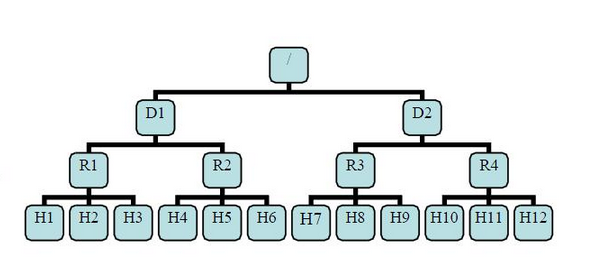
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
参考 https://issues.apache.org/jira/secure/attachment/12345251/Rack_aware_HDFS_proposal.pdf
http://blog.csdn.net/hjwang1/article/details/6592714
http://blog.csdn.net/azhao_dn/article/details/7091258
http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html
hadoop机架感知的更多相关文章
- 【转载】Hadoop机架感知
转载自http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机 ...
- hadoop之 hadoop 机架感知
1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份.这样如果本地数据损坏,节点可以从同一机 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- 【Hadoop】Hadoop 机架感知配置、原理
Hadoop机架感知 1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份, 同机架内其它某一节点上一份,不同机架的某一节点上一份. 这样如果本地 ...
- 【原创】Hadoop机架感知对性能调优的理解
Hadoop作为大数据处理的典型平台,在海量数据处理过程中,其主要限制因素是节点之间的数据传输速率.因为集群的带宽有限,而有限的带宽资源却承担着大量的刚性带宽需求,例如Shuffle阶段的数据传输不可 ...
- Hadoop hadoop 机架感知配置
机架感知脚本 使用python3编写机架感知脚本,报存到topology.py,给予执行权限 import sys import os DEFAULT_RACK="/default-rack ...
- hadoop机架感知与网络拓扑分析:NetworkTopology和DNSToSwitchMapping
hadoop网络拓扑结构在整个系统中具有很重要的作用,它会影响DataNode的启动(注册).MapTask的分配等等.了解网络拓扑对了解整个hadoop的运行会有很大帮助. 首先通过下面两个图来了解 ...
- hadoop(三):hdfs 机架感知
client 向 Active NN 发送写请求时,NN为这些数据分配DN地址,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影响.一个简单但非优化的副本放置策略是,把副本分别放在不同机架 ...
- 实现hadoop中的机架感知
hadoop中声明是有机架感知的功能,能够提高hadoop的性能.平时我们使用的hadoop集群,实际上是从来没有使用上这个功能的. hadoop中所说的 机架感知的实现实际上这样的: hadoop启 ...
随机推荐
- Redis操作+python
自动化接口测试中需要向redis中插入测试数据: 1. 连接redis: import redisself.r = redis.StrictRedis(host=env.REDIS_HOST, por ...
- pthread_create线程创建的过程剖析
http://blog.csdn.net/wangyin159/article/details/47082125 在Linux环境下,pthread库提供的pthread_create()API函数, ...
- Ten Tips for Writing CS Papers, Part 2
Ten Tips for Writing CS Papers, Part 2 This continues the first part on tips to write computer scien ...
- Tomcat的目录结构及用途
目录结构及用途 目录 用途 bin 包含启动/关闭脚本 conf 包含不同的配置文件,包括 server.xml(Tomcat的主要配置文件)和为不同的Tomcat配置的web应用设置缺省值的文件we ...
- Android Studio-设置switch/case代码块自动补齐
相信很多和我一样的小伙伴刚从Eclipse转到Android Studio的时候,一定被快捷键给搞得头晕了,像Eclipse中代码补齐的快捷键是Alt+/ ,但是在AS中却要自己设置,这还不是问题的关 ...
- [实战]MVC5+EF6+MySql企业网盘实战(27)——应用列表
写在前面 本篇文章将实现应用列表,同样和其他列表的不同之处,在于查询条件的不同. 系列文章 [EF]vs15+ef6+mysql code first方式 [实战]MVC5+EF6+MySql企业网盘 ...
- 修改linux文件权限命令:chmod
Linux系统中的每个文件和目录都有访问许可权限,用它来确定谁可以通过何种方式对文件和目录进行访问和操作. 文件或目录的访问权限分为只读,只写和可执行三种.以文件为例,只读权限表示只允许读其内容, ...
- 遇到个小问题,Java泛型真的是鸡肋吗?
今天遇到一个小问题,让我感觉Java的泛型(因为背负了历史的包袱导致的)有点鸡肋啊. 我们经常会遇到要一些自定义的key-value字符串,比如: "key1:1k;key2:2;key3: ...
- 是智能手机推动windows xp系统停止服务吗
昨天是windows xp系统停止服务的大限,各大媒体争相报道,漫天铺地的xp消息充斥网络,xp这个词的百度指数这段时间从4月1日的8411也开始猛涨,特别是这两天4月7日的36470飙升到4月8日的 ...
- 使用多种方式实现遍历HashMap
今天讲解的主要是使用多种方式来实现遍历HashMap取出Key和value,首先在java中如果想让一个集合能够用for增强来实现迭代,那么此接口或类必须实现Iterable接口,那么Iterable ...