深入理解图优化与g2o:图优化篇
前言
本节我们将深入介绍视觉slam中的主流优化方法——图优化(graph-based optimization)。下一节中,介绍一下非常流行的图优化库:g2o。
关于g2o,我13年写过一个文档,然而随着自己理解的加深,越发感觉不满意。本着对读者更负责任的精神,本文给大家重新讲一遍图优化和g2o。除了这篇文档,读者还可以找到一篇关于图优化的博客: http://blog.csdn.net/heyijia0327 那篇文章有作者介绍的一个简单案例,而本文则更注重对图优化和g2o的理解与评注。
本节主要介绍图优化的数学理论,下节再讲g2o的组成方式及使用方法。
预备知识:优化
图优化本质上是一个优化问题,所以我们先来看优化问题是什么。
优化问题有三个最重要的因素:目标函数、优化变量、优化约束。一个简单的优化问题可以描述如下:\[ \begin{equation} \min\limits_{x} F(x) \end{equation}\] 其中$x$为优化变量,而$F(x)$为优化函数。此问题称为无约束优化问题,因为我们没有给出任何约束形式。由于slam中优化问题多为无约束优化,所以我们着重介绍无约束的形式。
当$F(x)$有一些特殊性质时,对应的优化问题也可以用一些特殊的解法。例如,$F(x)$为一个线性函数时,则为线性优化问题(不过线性优化问题通常在有约束情形下讨论)。反之则为非线性优化。对于无约束的非线性优化,如果我们知道它梯度的解析形式,就能直接求那些梯度为零的点,来解决这个优化:
\[\begin{equation} \frac{{dF}}{{dx}} = 0 \end{equation}\]
梯度为零的地方可能是函数的极大值、极小值或者鞍点。由于现在$F(x)$的形式不确定,我们只好遍历所有的极值点,找到最小的作为最优解。
但是我们为什么不这样用呢?因为很多时候$F(x)$的形式太复杂,导致我们没法写出导数的解析形式,或者难以求解导数为零的方程。因此,多数时候我们使用迭代方式求解。从一个初值$x_0$出发,不断地导致当前值附近的,能使目标函数下降的方式(反向梯度),然后沿着梯度方向走出一步,从而使得函数值下降一点。这样反复迭代,理论上对于任何函数,都能找到一个极小值点。
迭代的策略主要体现在如何选择下降方向,以及如何选择步长两个方面。主要有 Gauss-Newton (GN)法和 Levenberg-Marquardt (LM)法两种,它们的细节可以在维基上找到,我们不细说。请理解它们主要在迭代策略上有所不同,但是寻找梯度并迭代则是一样的。
图优化
所谓的图优化,就是把一个常规的优化问题,以图(Graph)的形式来表述。
图是什么呢?
图是由顶点(Vertex)和边(Edge)组成的结构,而图论则是研究图的理论。我们记一个图为$G=\{ V, E \}$,其中$V$为顶点集,$E$为边集。
顶点没什么可说的,想象成普通的点即可。
边是什么呢?一条边连接着若干个顶点,表示顶点之间的一种关系。边可以是有向的或是无向的,对应的图称为有向图或无向图。边也可以连接一个顶点(Unary Edge,一元边)、两个顶点(Binary Edge,二元边)或多个顶点(Hyper Edge,多元边)。最常见的边连接两个顶点。当一个图中存在连接两个以上顶点的边时,称这个图为超图(Hyper Graph)。而SLAM问题就可以表示成一个超图(在不引起歧义的情况下,后文直接以图指代超图)。
怎么把SLAM问题表示成图呢?
SLAM的核心是根据已有的观测数据,计算机器人的运动轨迹和地图。假设在时刻$k$,机器人在位置$x_k$处,用传感器进行了一次观测,得到了数据$z_k$。传感器的观测方程为:
\[ \begin{equation}{z_k} = h\left( {{x_k}} \right) \end{equation} \]
由于误差的存在,$z_k$不可能精确地等于$h(x_k)$,于是就有了误差:
\[ \begin{equation} {e_k} = {z_k} - h\left( {{x_k}} \right) \end{equation} \]
那么,如果我们以$x_k$为优化变量,以$ \min\limits_x F_k (x_k) = \| e_k \| $为目标函数,就可以求得$x_k$的估计值,进而得到我们想要的东西了。这实际上就是用优化来求解SLAM的思路。
你说的优化变量$x_k$,观测方程$z_k = h (x_k)$等等,它们具体是什么东西呢?
这个取决于我们的参数化(parameterazation)。$x$可以是一个机器人的Pose(6自由度下为 $4\times 4$的变换矩阵$\mathbf{T}$ 或者 3自由度下的位置与转角$[x,y,\theta]$,也可以是一个空间点(三维空间的$[x,y,z]$或二维空间的$[x,y]$)。相应的,观测方程也有很多形式,如:
- 机器人两个Pose之间的变换;
- 机器人在某个Pose处用激光测量到了某个空间点,得到了它离自己的距离与角度;
- 机器人在某个Pose处用相机观测到了某个空间点,得到了它的像素坐标;
同样,它们的具体形式很多样化,这允许我们在讨论slam问题时,不局限于某种特定的传感器或姿态表达方式。
我明白优化是什么意思了,但是它们怎么表达成图呢?
在图中,以顶点表示优化变量,以边表示观测方程。由于边可以连接一个或多个顶点,所以我们把它的形式写成更广义的 $z_k = h(x_{k1}, x_{k2}, \ldots )$,以表示不限制顶点数量的意思。对于刚才提到的三种观测方程,顶点和边是什么形式呢?
- 机器人两个Pose之间的变换;——一条Binary Edge(二元边),顶点为两个pose,边的方程为${T_1} = \Delta T \cdot {T_2}$。
- 机器人在某个Pose处用激光测量到了某个空间点,得到了它离自己的距离与角度;——Binary Edge,顶点为一个2D Pose:$[x,y,\theta]^T$和一个Point:$[\lambda_x, \lambda_y]^T$,观测数据是距离$r$和角度$b$,那么观测方程为:
\[ \begin{equation}
\left[
{\begin{array}{*{20}{c}}
{r}\\
{b}
\end{array}}
\right] = \left[ {
\begin{array}{*{20}{c}}
{\sqrt {{{({\lambda _x} - x)}^2} + {{({\lambda _y} - y)}^2}}}\\
{{{\tan }^{ - 1}}\left( {\frac{{{\lambda _y} - y}}{{{\lambda _x} - x}}} \right) - \theta }
\end{array}}
\right]
\end{equation}\] - 机器人在某个Pose处用相机观测到了某个空间点,得到了它的像素坐标;——Binary Edge,顶点为一个3D Pose:$T$和一个空间点$\mathbf{x} = [x,y,z]^T$,观测数据为像素坐标$z=[u,v]^T$。那么观测方程为:\[ \begin{equation} z = C ( R \mathbf{x} + t ) \end{equation} \]
$C$为相机内参,$R,t$为旋转和平移。
举这些例子,是为了让读者更好地理解顶点和边是什么东西。由于机器人可能使用各种传感器,故我们不限制顶点和边的参数化之后的样子。比如我(丧心病狂地在小萝卜身上)既加了激光,也用相机,还用了IMU,轮式编码器,超声波等各种传感器来做slam。为了求解整个问题,我的图中就会有各种各样的顶点和边。但是不管如何,都是可以用图来优化的。

(暗黑小萝卜 小眼神degined by Orchid Zhang)以后找不到工作我就去当插画算了……
图优化怎么做
现在让我们来仔细看一看图优化是怎么做的。假设一个带有$n$条边的图,其目标函数可以写成:
\[ \begin{equation} \min\limits_{x} \sum\limits_{k = 1}^n {{e_k}{{\left( {{x_k},{z_k}} \right)}^T}{\Omega _k}{e_k}\left( {{x_k},{z_k}} \right)} \end{equation}\]
关于这个目标函数,我们有几句话要讲。这些话都是很重要的,请读者仔细去理解。
- $e$ 函数在原理上表示一个误差,是一个矢量,作为优化变量$x_k$和$z_k$符合程度的一个度量。它越大表示$x_k$越不符合$z_k$。但是,由于目标函数必须是标量,所以必须用它的平方形式来表达目标函数。最简单的形式是直接做成平方:$e(x,z)^T e(x,z)$。进一步,为了表示我们对误差各分量重视程度的不一样,还使用一个信息矩阵 $\Omega$ 来表示各分量的不一致性。
- 信息矩阵 $\Omega$ 是协方差矩阵的逆,是一个对称矩阵。它的每个元素$ \Omega_{i,j}$作为$e_i e_j$的系数,可以看成我们对$e_i, e_j$这个误差项相关性的一个预计。最简单的是把$\Omega$设成对角矩阵,对角阵元素的大小表明我们对此项误差的重视程度。
- 这里的$x_k$可以指一个顶点、两个顶点或多个顶点,取决于边的实际类型。所以,更严谨的方式是把它写成$e_k ( z_k, x_{k1}, x_{k2}, \ldots )$,但是那样写法实在是太繁琐,我们就简单地写成现在的样子。由于$z_k$是已知的,为了数学上的简洁,我们再把它写成$e_k(x_k)$的形式。
于是总体优化问题变为$n$条边加和的形式:
\[ \begin{equation} \min F(x) = \sum\limits_{k = 1}^n {{e_k}{{\left( {{x_k}} \right)}^T}{\Omega _k}{e_k}\left( {{x_k}} \right)} \end{equation}\]
重复一遍,边的具体形式有很多种,可以是一元边、二元边或多元边,它们的数学表达形式取决于传感器或你想要描述的东西。例如视觉SLAM中,在一个相机Pose $T_k$ 处对空间点$\mathbf{x}_k$进行了一次观测,得到$z_k$,那么这条二元边的数学形式即为$${e_k}\left( {{x_k},{T_k},{z_k}} \right) = {\left( {{z_k} - C\left( {R{x_k} + t} \right)} \right)^T}{\Omega _k}\left( {{z_k} - C\left( {R{x_k} - t} \right)} \right)$$ 单个边其实并不复杂。
现在,我们有了一个很多个节点和边的图,构成了一个庞大的优化问题。我们并不想展开它的数学形式,只关心它的优化解。那么,为了求解优化,需要知道两样东西:一个初始点和一个迭代方向。为了数学上的方便,先考虑第$k$条边$e_k(x_k)$吧。
我们假设它的初始点为${{\widetilde x}_k}$,并且给它一个$\Delta x$的增量,那么边的估计值就变为$F_k ( {\widetilde x}_k + \Delta x )$,而误差值则从 $e_k(\widetilde x)$ 变为 $e_k({\widetilde x}_k + \Delta x )$。首先对误差项进行一阶展开:
\[ \begin{equation} {e_k}\left( {{{\widetilde x}_k} + \Delta x} \right) \approx {e_k}\left( {{{\widetilde x}_k}} \right) + \frac{{d{e_k}}}{{d{x_k}}}\Delta x = {e_k} + {J_k}\Delta x\end{equation} \]
这是的$J_k$是$e_k$关于$x_k$的导数,矩阵形式下为雅可比阵。我们在估计点附近作了一次线性假设,认为函数值是能够用一阶导数来逼近的,当然这在$\Delta x$很大时候就不成立了。
于是,对于第$k$条边的目标函数项,有:
进一步展开:
$$\begin{array}{lll}{F_k}\left( {{{\widetilde x}_k} + \Delta x} \right) &=& {e_k}{\left( {{{\widetilde x}_k} + \Delta x} \right)^T}{\Omega _k}{e_k}\left( {{{\widetilde x}_k} + \Delta x} \right)\\
& \approx & {\left( {{e_k} + {J_k}\Delta x} \right)^T}{\Omega _k}\left( {{e_k} + J\Delta x} \right)\\
&=& e_k^T{\Omega _k}{e_k} + 2e_k^T{\Omega _k}{J_k}\Delta x + \Delta {x^T}J_k^T{\Omega _k}{J_k}\Delta x\\ &=& {C_k} + 2{b_k}\Delta x + \Delta {x^T}{H_k}\Delta x
\end{array}$$
在熟练的同学看来,这个推导就像$(a+b)^2=a^2+2ab+b^2$一样简单(事实上就是好吧)。最后一个式子是个定义整理式,我们把和$\Delta x$无关的整理成常数项 $C_k$ ,把一次项系数写成 $2b_k$ ,二次项则为 $H_k$(注意到二次项系数其实是Hessian矩阵)。
请注意 $C_k$ 实际就是该边变化前的取值。所以在$x_k$发生增量后,目标函数$F_k$项改变的值即为$$\Delta F_k = 2b_k \Delta x + \Delta x^T H_k \Delta x. $$
我们的目标是找到$\Delta x$,使得这个增量变为极小值。所以直接令它对于$\Delta x$的导数为零,有:
\[ \begin{equation} \frac{{d{F_k}}}{{d\Delta x}} = 2b + 2{H_k}\Delta x = 0 \Rightarrow {H_k}\Delta x = - b_k \end{equation} \]
所以归根结底,我们求解一个线性方程组:\[ \begin{equation} H_k \Delta x = -b_k \end{equation} \]
如果把所有边放到一起考虑进去,那就可以去掉下标,直接说我们要求解$$ H \Delta x = -b. $$
原来算了半天它只是个线性的!线性的谁不会解啊!
读者当然会有这种感觉,因为线性规划是规划中最为简单的,连小学生都会解这么简单的问题,为何21世纪前SLAM不这样做呢?——这是因为在每一步迭代中,我们都要求解一个雅可比和一个海塞。而一个图中经常有成千上万条边,几十万个待估计参数,这在以前被认为是无法实时求解的。
那为何后来又可以实时求解了呢?
SLAM研究者逐渐认识到,SLAM构建的图,并非是全连通图,它往往是很稀疏的。例如一个地图里大部分路标点,只会在很少的时刻被机器人看见,从而建立起一些边。大多数时候它们是看不见的(就像后宫怨女一样)。体现在数学公式中,虽然总体目标函数$F(x)$有很多项,但某个顶点$x_k$就只会出现在和它有关的边里面!
这会导致什么?这导致许多和$x_k$无关的边,比如说$e_j$,对应的雅可比$J_j$就直接是个零矩阵!而总体的雅可比$J$中,和$x_k$有关的那一列大部分为零,只有少数的地方,也就是和$x_k$顶点相连的边,出现了非零值。
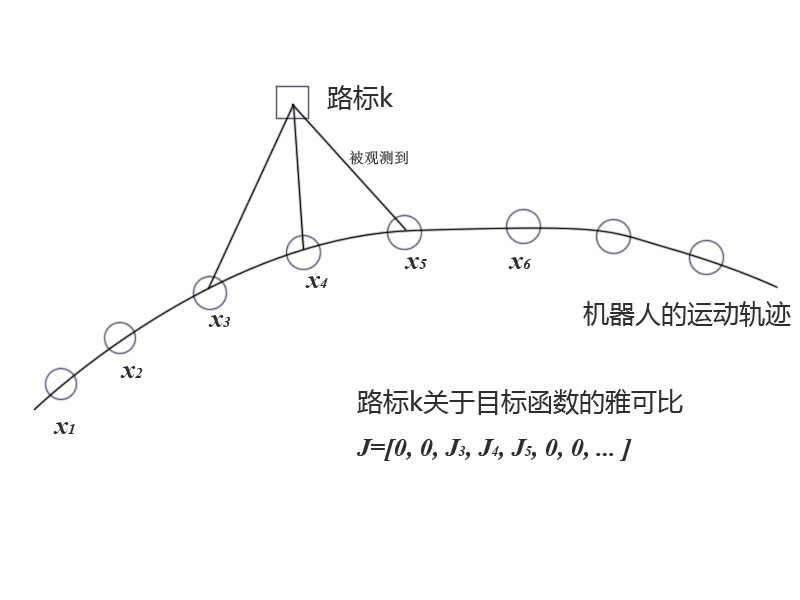
相应的二阶导矩阵$H$中,大部分也是零元素。这种稀疏性能很好地帮助我们快速求解上面的线性方程。出于篇幅我们先不细说这是如何做到的了。稀疏代数库包括SBA、PCG、CSparse、Cholmod等等。g2o正是使用它们来求解图优化问题的。
要补充一点的是,在数值计算中,我们可以给出雅可比和海塞的解析形式进行计算,也可以让计算机去数值计算这两个阵,而我们只需要给出误差的定义方式即可。
流形
等一下老师!上面推导还有一个问题!
很好,小萝卜同学,请说说是什么问题。
我们在讨论给目标函数$F(x)$一个增量$\Delta x$时,直接就写成了$F(x+\Delta x)$。但是老师,这个加法可能没有定义!
小萝卜同学看到了一个严重的问题,这确实是在先前的讨论中忽略掉了。由于我们不限制顶点的类型,$x$在参数化之后,很可能是没有加法定义的。
最简单的就是常见的四维变换矩阵$T$或者三维旋转矩阵$R$。它们对加法并不封闭,因为两个变换阵之和并不是变换阵,两个正交阵之和也不是正交阵。它们乘法的性质非常好,但是确实没有加法,所以也不能像上面讨论的那样去求导。
但是,如果图优化不能处理$SE(3)$或$SO(3)$中的元素,那将是十分令人沮丧的,因为SLAM要估计的机器人轨迹必须用它们来描述啊。
回想我们先前讲过的李代数知识。虽然李群 $SE(3)$ 和 $SO(3)$ 是没有加法的,但是它们对应的李代数 $\mathfrak{se}(3), \mathfrak{so}(3)$ 有啊! 数学一点地说,我们可以求它们在正切空间里的流形上的梯度!如果读者觉得理解困难,我们就说,通过指数变换和对数变换,先把变换矩阵和旋转矩阵转换成李代数,在李代数上进行加法,然后再转换到原本的李群中。这样我们就完成了求导。
这样的好处是我们完全不用重新推导公式。这件事比我们想的更加简单。在程序里,我们只需重新定义一个优化变量$x$的增量加法即可。如果$x$是一个$SE(3)$里的变换矩阵,我们就遵守刚才讲的李代数转换方式。当然,如果$x$是其他什么奇怪的东东,只要定义了它的加法,程序就会自动去计算如何求它的雅可比。
核函数
又是核函数!——学过机器学习课程的同学肯定要这样讲。
但是很遗憾,图优化中也有一种核函数。 引入核函数的原因,是因为SLAM中可能给出错误的边。SLAM中的数据关联让科学家头疼了很长时间。出于变化、噪声等原因,机器人并不能确定它看到的某个路标,就一定是数据库中的某个路标。万一认错了呢?我把一条原本不应该加到图中的边给加进去了,会怎么样?
嗯,那优化算法可就慒逼了……它会看到一条误差很大的边,然后试图调整这条边所连接的节点的估计值,使它们顺应这条边的无理要求。由于这个边的误差真的很大,往往会抹平了其他正确边的影响,使优化算法专注于调整一个错误的值。
于是就有了核函数的存在。核函数保证每条边的误差不会大的没边,掩盖掉其他的边。具体的方式是,把原先误差的二范数度量,替换成一个增长没有那么快的函数,同时保证自己的光滑性质(不然没法求导啊!)。因为它们使得整个优化结果更为鲁棒,所以又叫它们为robust kernel(鲁棒核函数)。
很多鲁棒核函数都是分段函数,在输入较大时给出线性的增长速率,例如cauchy核,huber核等等。当然具体的我们也不展开细说了。
核函数在许多优化环境中都有应用,博主个人印象较深的时当年有一大堆人在机器学习算法里加各种各样的核,我们现在用的svm也会带个核函数。
小结
最后总结一下做图优化的流程。
- 选择你想要的图里的节点与边的类型,确定它们的参数化形式;
- 往图里加入实际的节点和边;
- 选择初值,开始迭代;
- 每一步迭代中,计算对应于当前估计值的雅可比矩阵和海塞矩阵;
- 求解稀疏线性方程$H_k \Delta x = -b_k$,得到梯度方向;
- 继续用GN或LM进行迭代。如果迭代结束,返回优化值。
实际上,g2o能帮你做好第3-6步,你要做的只是前两步而已。下节我们就来尝试这件事。
深入理解图优化与g2o:图优化篇的更多相关文章
- 深入理解图优化与g2o:g2o篇
内容提要 讲完了优化的基本知识,我们来看一下g2o的结构.本篇将讨论g2o的代码结构,并带着大家一起写一个简单的双视图bundle adjustment:从两张图像中估计相机运动和特征点位置.你可以把 ...
- 分享一个基于小米 soar 的开源 sql 分析与优化的 WEB 图形化工具
soar-web 基于小米 soar 的开源 sql 分析与优化的 WEB 图形化工具,支持 soar 配置的添加.修改.复制,多配置切换,配置的导出.导入与导入功能. 环境需求 python3.xF ...
- mysql数据库优化总结 有图 有用
对于一个以数据为中心的应用,数据库的好坏直接影响到程序的性能,因此数据库性能至关重要.一般来说,要保证数据库的效率,要做好以下四个方面的工作:数据库设计.sql语句优化.数据库参数配置.恰当的硬件资源 ...
- MYSQL索引优化思维导图
有关索引的优化.MYSQL索引优化 文章来源:刘俊涛的博客 地址:http://www.cnblogs.com/lovebing
- [Unity3D]图形渲染优化、渲染管线优化、图形性能优化
原地址:http://blog.sina.com.cn/s/blog_5b6cb9500101dmh0.html 转载请留下本文原始链接,谢谢.本文会不定期更新维护,最近更新于2013.11.09 ...
- ORACLE性能优化之SQL语句优化
版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[+] 操作环境:AIX +11g+PLSQL 包含以下内容: 1. SQL语句执行过程 2. 优化器及执行计划 3. 合 ...
- Shader中贴图知识汇总: 漫反射贴图、凹凸贴图、高光贴图、 AO贴图、环境贴图、 光照纹理及细节贴图
原文过于冗余,精读后做了部分简化与测试实践,原文地址:http://www.j2megame.com/html/xwzx/ty/2571.html http://www.cnblogs.com/z ...
- 【UML 建模】UML建模语言入门 -- 静态图详解 类图 对象图 包图 静态图建模实战
发现个好东西思维导图, 最近开始用MindManager整理博客 . 作者 :万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/deta ...
- (转)学习MySQL优化原理,这一篇就够了!
原文:https://mp.weixin.qq.com/s__biz=MzI4NTA1MDEwNg==&mid=2650763421&idx=1&sn=2515421f09c1 ...
随机推荐
- 为什么心跳包(HeartBeat)是必须的?
几乎所有的网游服务端都有心跳包(HeartBeat或Ping)的设计,在最近开发手游服务端时,也用到了心跳包.思考思考,心跳包是必须的吗?为什么需要心跳包?TCP没有提供断线检测的方法吗?TCP提供的 ...
- [BTS] SQL Adapter. New transaction cannot enlist in the specified transaction coordinator
The adapter "SQL" raised an error message. Details "New transaction cannot enlist in ...
- VS2013编译经常卡在正在从以下位置加载xxx.dll的符号
换了系统后,重新下载了一个vs2013 with update2安装,编译的时候总是卡在 正在从以下位置加载xxx.dll的符号 如图: 解决方法: 进入VS---工具---选项----调试----符 ...
- iOS开发——高级技术&签名机制
签名机制 最近看了objc.io上第17期中的文章 <Inside Code Signing> 对应的中文翻译版 <代码签名探析> ,受益颇深,对iOS代码签名机制有了进一步的 ...
- 关于TCP的粘包
2014年与宗宗一起去厦门测试软件接口的时候,与上级系统基于TCP方式通讯,数据量大时,经常通讯失败,检查日志发现是上级系统应该多次返回的数据一次性接收到了. 上网搜索了一下,才了解到TCP粘包的问题 ...
- python实现自动发送微博,当自己写博客时同步上去。
一.需求: 自己在github上搭建一个基于Jekyll的博客(http://beginman.cn/),每次写完博客后就要push上去,博客写的再好,基本上没人访问,为了增加访问量,就想利用起来微博 ...
- 【1】CommonCode快速代码集
阅读目录 CommonCode是什么? CommonCode包括哪些内容? 版本信息 回到顶部 CommonCode是什么? 简单的说,CommonCode是作者在经历各种"试错&quo ...
- 【转】Xcode概览(Xcode 6版):循序渐进认识Xcode
该系列文章翻译自苹果的Xcode Overview文档,对大部分开发者来说,已经非常熟悉Xcode的功能和特性,不过伴随着iOS 8 SDK的发布,Xcode 6中也有些许调整,所以对该文档进行了翻译 ...
- XMPP系列2:如何掌握XMPP协议
michaely 回答于 2012-08-07 08:34 举报我要说的是:1.任何一个协议想学习并熟练掌握,都不是一天两天的事情.2.XMPP协议现在已经有很多成熟的架构和客户端,无需重新造轮子.3 ...
- Python 目录操作
知道两个文件的绝对目录,怎样计算出两个文件的相对目录,例如:知道 a = '/usr/share/pyshared/test/a.py' b = '/usr/lib/dist/test/a.py' 可 ...