[CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/
Introduction to neural networks



-Training Neural Network

_____________________________________________________________________________________________________________________________________________________________________________
-Activation Functions

为什么要把线性转换为非线性?
引用ufldl:


*sigmoid neuron

(引自:http://blog.csdn.net/han_xiaoyang/article/details/50447834):
- sigmoid函数在实际梯度下降中,容易饱和和终止梯度传递。我们来解释一下,大家知道反向传播过程,依赖于计算的梯度,在一元函数中,即斜率。而在sigmoid函数图像上,大家可以很明显看到,在纵坐标接近0和1的那些位置(也就是输入信号的幅度很大的时候),斜率都趋于0了。我们回想一下反向传播的过程,我们最后用于迭代的梯度,是由中间这些梯度值结果相乘得到的,因此如果中间的局部梯度值非常小,直接会把最终梯度结果拉近0,也就是说,残差回传的过程,因为sigmoid函数的饱和被杀死了。说个极端的情况,如果一开始初始化权重的时候,我们取值不是很恰当,而激励函数又全用的sigmoid函数,那么很有可能神经元一个不剩地饱和到无法学习,整个神经网络也根本没办法训练起来。
- sigmoid函数的输出没有
0中心化,这是一个比较闹心的事情,因为每一层的输出都要作为下一层的输入,而未0中心化会直接影响梯度下降,我们这么举个例子吧,如果输出的结果均值不为0,举个极端的例子,全部为正的话(例如 f=wTx+b中所有
f=wTx+b中所有 x>0),那么反向传播回传到W上的梯度将全部为负,这带来的后果是,梯度更新的时候,不是平缓地迭代变化,而是类似锯齿状的突变。当然,要多说一句的是,这个缺点相对于第一个缺点,还稍微好一点,第一个缺点的后果是,很多场景下,神经网络根本没办法学习。
x>0),那么反向传播回传到W上的梯度将全部为负,这带来的后果是,梯度更新的时候,不是平缓地迭代变化,而是类似锯齿状的突变。当然,要多说一句的是,这个缺点相对于第一个缺点,还稍微好一点,第一个缺点的后果是,很多场景下,神经网络根本没办法学习。

*tanh

Tanh函数的图像如上图所示。它会将输入值压缩至-1到1之间,当然,它同样也有sigmoid函数里说到的第一个缺点,在很大或者很小的输入值下,神经元很容易饱和。但是它缓解了第二个缺点,它的输出是0中心化的。所以在实际应用中,tanh激励函数还是比sigmoid要用的多一些的。
*ReLU

ReLU是修正线性单元(The Rectified Linear Unit)的简称,近些年使用的非常多,图像如上图所示。它对于输入x计算 f(x)=max(0,x)。换言之,以0为分界线,左侧都为0,右侧是y=x这条直线。
f(x)=max(0,x)。换言之,以0为分界线,左侧都为0,右侧是y=x这条直线。
它有它对应的优势,也有缺点:
- 优点1:实验表明,它的使用,相对于sigmoid和tanh,可以非常大程度地提升随机梯度下降的收敛速度。不过有意思的是,很多人说,这个结果的原因是它是线性的,而不像sigmoid和tanh一样是非线性的。具体的收敛速度结果对比如下图,收敛速度大概能快上6倍:
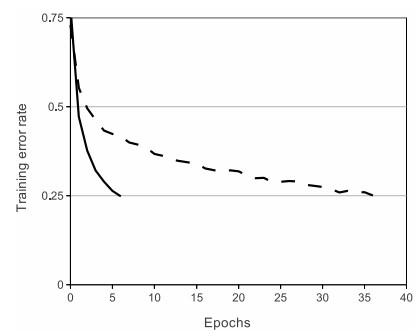
- 优点2:相对于tanh和sigmoid激励神经元,求梯度不要简单太多好么!!!毕竟,是线性的嘛。。。
- 缺点1:ReLU单元也有它的缺点,在训练过程中,它其实挺脆弱的,有时候甚至会挂掉。举个例子说吧,如果一个很大的梯度
流经ReLU单元,那权重的更新结果可能是,在此之后任何的数据点都没有办法再激活它了。一旦这种情况发生,那本应经这个ReLU回传的梯度,将永远变为0。当然,这和参数设置有关系,所以我们要特别小心,再举个实际的例子哈,如果学习速率被设的太高,结果你会发现,训练的过程中可能有高达40%的ReLU单元都挂掉了。所以我们要小心设定初始的学习率等参数,在一定程度上控制这个问题。
*Leaky ReLU

上面不是提到ReLU单元的弱点了嘛,所以孜孜不倦的ML researcher们,就尝试修复这个问题咯,他们做了这么一件事,在x<0的部分,leaky ReLU不再让y的取值为0了,而是也设定为一个坡度很小(比如斜率0.01)的直线。f(x)因此是一个分段函数,x<0时, f(x)=αx(α是一个很小的常数),x>0时,
f(x)=αx(α是一个很小的常数),x>0时, f(x)=x。有一些researcher们说这样一个形式的激励函数帮助他们取得更好的效果,不过似乎并不是每次都比ReLU有优势。
f(x)=x。有一些researcher们说这样一个形式的激励函数帮助他们取得更好的效果,不过似乎并不是每次都比ReLU有优势。
*Maxout

也有一些其他的激励函数,它们并不是对 WTX+b做非线性映射
WTX+b做非线性映射 f(WTX+b)。一个近些年非常popular的激励函数是Maxout(详细内容请参见Maxout)。简单说来,它是ReLU和Leaky ReLU的一个泛化版本。对于输入x,Maxout神经元计算
f(WTX+b)。一个近些年非常popular的激励函数是Maxout(详细内容请参见Maxout)。简单说来,它是ReLU和Leaky ReLU的一个泛化版本。对于输入x,Maxout神经元计算 max(wT1x+b1,wT2x+b2)。有意思的是,如果你仔细观察,你会发现ReLU和Leaky ReLU都是它的一个特殊形式(比如ReLU,你只需要把
max(wT1x+b1,wT2x+b2)。有意思的是,如果你仔细观察,你会发现ReLU和Leaky ReLU都是它的一个特殊形式(比如ReLU,你只需要把 w1,b1设为0)。因此Maxout神经元继承了ReLU单元的优点,同时又没有『一不小心就挂了』的担忧。如果要说缺点的话,你也看到了,相比之于ReLU,因为有2次线性映射运算,因此计算量也double了。
w1,b1设为0)。因此Maxout神经元继承了ReLU单元的优点,同时又没有『一不小心就挂了』的担忧。如果要说缺点的话,你也看到了,相比之于ReLU,因为有2次线性映射运算,因此计算量也double了。
*summary

以上就是我们总结的常用的神经元和激励函数类型。顺便说一句,即使从计算和训练的角度看来是可行的,实际应用中,其实我们很少会把多种激励函数混在一起使用。
那我们咋选用神经元/激励函数呢?一般说来,用的最多的依旧是ReLU,但是我们确实得小心设定学习率,同时在训练过程中,还得时不时看看神经元此时的状态(是否还『活着』)。当然,如果你非常担心神经元训练过程中挂掉,你可以试试Leaky ReLU和Maxout。额,少用sigmoid老古董吧,有兴趣倒是可以试试tanh,不过话说回来,通常状况下,它的效果不如ReLU/Maxout。
_____________________________________________________________________________________________________________________________________________________________________________
-Data Preprocessing
*Preprocess the data


*Weight Initialization

learning nothing
随机生成初始W值:

导致反向传递时,由于需要计算对w的偏导,由于x的值太小,所以乘到最前面的层时,结果几乎为0.


但是,如果用relu作为激活函数时,


*batch normalisation
以下引自知乎:
1. What is BN?
顾名思义,batch normalization嘛,就是“批规范化”咯。Google在ICML文中描述的非常清晰,即在每次SGD(stochastic gradient descent)时,通过mini-batch来对相应的activation做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1. 而最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入(即当
&amp;amp;amp;amp;lt;img src="https://pic2.zhimg.com/9ad70be49c408d464c71b8e9a006d141_b.jpg" data-rawwidth="776" data-rawheight="616" class="origin_image zh-lightbox-thumb" width="776" data-original="https://pic2.zhimg.com/9ad70be49c408d464c71b8e9a006d141_r.jpg"&amp;amp;amp;amp;gt;关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.
 关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.
关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.
2. How to Batch Normalize?
怎样学BN的参数在此就不赘述了,就是经典的chain rule:
&amp;amp;amp;amp;lt;img src="https://pic1.zhimg.com/beb44145200caafe24fe88e7480e9730_b.jpg" data-rawwidth="658" data-rawheight="380" class="origin_image zh-lightbox-thumb" width="658" data-original="https://pic1.zhimg.com/beb44145200caafe24fe88e7480e9730_r.jpg"&amp;amp;amp;amp;gt;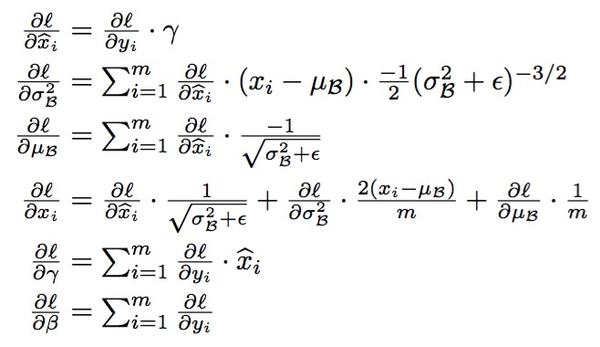
3. Where to use BN?
BN可以应用于网络中任意的activation set。文中还特别指出在CNN中,BN应作用在非线性映射前,即对做规范化。另外对CNN的“权值共享”策略,BN还有其对应的做法(详见文中3.2节)。
4. Why BN?
好了,现在才是重头戏--为什么要用BN?BN work的原因是什么?
说到底,BN的提出还是为了克服深度神经网络难以训练的弊病。其实BN背后的insight非常简单,只是在文章中被Google复杂化了。
首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有,
,但是
. 大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
那么好,为什么前面我说Google将其复杂化了。其实如果严格按照解决covariate shift的路子来做的话,大概就是上“importance weight”(ref)之类的机器学习方法。可是这里Google仅仅说“通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差”就可以解决问题。如果covariate shift可以用这么简单的方法解决,那前人对其的研究也真真是白做了。此外,试想,均值方差一致的分布就是同样的分布吗?当然不是。显然,ICS只是这个问题的“包装纸”嘛,仅仅是一种high-level demonstration。
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:。在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。
5. When to use BN?
OK,说完BN的优势,自然可以知道什么时候用BN比较好。例如,在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
诚然,在DL中还有许多除BN之外的“小trick”。别看是“小trick”,实则是“大杀器”,正所谓“The devil is in the details”。希望了解其它DL trick(特别是CNN)的各位请移步我之前总结的:Must Know Tips/Tricks in Deep Neural Networks
链接:https://www.zhihu.com/question/38102762/answer/85238569
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

_____________________________________________________________________________________________________________________________________________________________________________
check:




_________________________________________________________________________________
Hyperparameter Optimization










[CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization的更多相关文章
- [Converge] Training Neural Networks
CS231n Winter 2016: Lecture 5: Neural Networks Part 2 CS231n Winter 2016: Lecture 6: Neural Networks ...
- 实现径向变换用于样本增强《Training Neural Networks with Very Little Data-A Draft》
背景: 做大规模机器学习算法,特别是神经网络最怕什么--没有数据!!没有数据意味着,机器学不会,人工不智能!通常使用样本增强来扩充数据一直都是解决这个问题的一个好方法. 最近的一篇论文<Trai ...
- (转)A Recipe for Training Neural Networks
A Recipe for Training Neural Networks Andrej Karpathy blog 2019-04-27 09:37:05 This blog is copied ...
- 1506.01186-Cyclical Learning Rates for Training Neural Networks
1506.01186-Cyclical Learning Rates for Training Neural Networks 论文中提出了一种循环调整学习率来训练模型的方式. 如下图: 通过循环的线 ...
- Training Neural Networks: Q&A with Ian Goodfellow, Google
Training Neural Networks: Q&A with Ian Goodfellow, Google Neural networks require considerable t ...
- A Recipe for Training Neural Networks [中文翻译, part 1]
最近拜读大神Karpathy的经验之谈 A Recipe for Training Neural Networks https://karpathy.github.io/2019/04/25/rec ...
- Implicit Neural Representations with Periodic Activation Functions
目录 概 主要内容 初始化策略 其它的好处 Sitzmann V., Martel J. N. P., Bergman A. W., Lindell D. B., Wetzstein G. Impli ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture6 Training Neural Networks I 听课笔记
1. 激活函数: 1)Sigmoid,σ(x)=1/(1+e-x).把输出压缩在(0,1)之间.几个问题:(a)x比较大或者比较小(比如10,-10),sigmoid的曲线很平缓,导数为0,在用链式法 ...
随机推荐
- Install wget for mac
Download: http://ftp.gnu.org/gnu/wget/ Unpack: tar zxvf wget-1.16.tar Configuration: ./configure If ...
- Atitit.提升稳定性-----分析内存泄漏PermGen OOM跟解决之道...java
Atitit.提升稳定性-----分析内存泄漏PermGen OOM跟解决之道...java 1. 内存区域的划分 1 2. PermGen内存溢出深入分析 1 3. PermGen OOM原因总结 ...
- Leetcode 283 Move Zeroes 字符串
class Solution { public: void moveZeroes(vector<int>& nums) { ; ; i< nums.size(); ++i){ ...
- Java和.net常用开发框架组合
Java: SSH和SSM 1.SSH是Spring(控制)+Struts(展现)+Hibernate(ORM)的缩写:此组合更严谨,适合企业级行业开发等等.2.SSM是Spring(控制)+Spri ...
- TexturePacker压缩png的命令
压缩png效果最好的当然是TinyPNG这种神器了,不过一般情况下TexturePacker压缩出来的也基本上能达到效果. 你需要先安装TP(TexturePacker的简称,以下TP无特殊说明均指T ...
- input type=file美化
最近碰到input type=file 之前用模拟点击来实现美化,发现在IE7下会有bug导致图片上传不上去,最后改用直接美化的方法 <!DOCTYPE html> <html la ...
- linux web服务器,防火墙iptables最简配置
配置防火墙(服务器安全优化) 安全规划:开启 80 22 端口并 打开回路(回环地址 127.0.0.1) # iptables –P INPUT ACCEPT # iptables –P OUTP ...
- activemq安全设置 设置admin的用户名和密码
ActiveMQ使用的是jetty服务器, 打开conf/jetty.xml文件,找到 <bean id="securityConstraint" class="o ...
- linux系统date命令详解
Linux时钟分为系统时钟(System Clock)和硬件(Real Time Clock,简称RTC)时钟.系统时钟是指当前Linux Kernel中的时钟,而硬件时钟则是主板上由电池供电的时钟, ...
- linux部署war包方案
batch.sh内容: su - -c" 使用管理员权限 service tomcat6 stop; 停止tomca6t服务 mkdir /home/jnfwzFtp/bushubackup ...