基于Cat的分布式调用追踪
Cat是美团点评出的一款APM工具,同类的产品也有不少,知名的开源产品如zipkin和pinpoint;国内收费的产品如oneapm。考虑到Cat在互联网公司的应用比较广,因此被纳入选型队列,我也有幸参与技术预言。
使用Cat断断续续将近两周的时间,感觉它还算是很轻量级的。文档相对来说薄弱一些,没有太全面的官方文档(官方文档大多是介绍每个名词是什么意思,界面是什么意思,部署方面比较欠缺);但是好在有一个非常活跃的群,群里有很多经验丰富的高手,不会的问题基本都能得到解答。
下面就开始步入正题吧,本篇主要讲述一下如何利用Cat进行分布式的调用链追踪。
分布式开发基础
在最开始网站基本都是单节点的,由于业务逐渐发展,使用者开始增多,单节点已经无法支撑了。于是开始切分系统,把系统拆分成几个独立的模块,模块之间采用远程调用的方式进行通信。
那么远程调用是如何做到的呢?下面就用最古老的RMI的方式来举个例子吧!
RMI(Remote method invocation)是java从1.1就开始支持的功能,它支持跨进程间的方法调用。
大体上的原理可以理解为,服务端会持续监听一个端口。客户端通过proxy代理的方式远程调用服务端。即客户端会把方法的参数以字符串的的方式序列化传给服务端。服务端反序列化后调用本地的方法执行,执行结果再序列化返回给客户端。
服务端的代码可以参考如下:
interface IBusiness extends Remote{
String echo(String message) throws RemoteException;
}
class BusinessImpl extends UnicastRemoteObject implements IBusiness {
public BusinessImpl() throws RemoteException {}
@Override
public String echo(String message) throws RemoteException {
return "hello,"+message;
}
}
public class RpcServer {
public static void main(String[] args) throws RemoteException, AlreadyBoundException, MalformedURLException {
IBusiness business = new BusinessImpl();
LocateRegistry.createRegistry(8888);
Naming.bind("rmi://localhost:8888/Business",business);
System.out.println("Hello, RMI Server!");
}
}
客户端的代码如下:
IBusiness business = (IBusiness) Naming.lookup("rmi://localhost:8888/Business");
business.echo("xingoo",ctx);
上面的例子就可以实现客户端跨进程调用的例子。
Cat监控
Cat的监控跟传统的APM产品差不多,模式都是相似的,需要一个agent在客户端进行埋点,然后把数据发送给服务端,服务端进行解析并存储。只要你埋点足够全,那么它是可以进行全面监控的。监控到的数据会首先按照某种规则进行消息的合并,合并成一个MessageTree,这个MessageTree会被放入BlockingQueue里面,这样就解决了多线程数据存储的问题。
队列会限制存储的MessageTree的个数,但是如果服务端挂掉,客户端也有可能因为堆积大量的心跳而导致内存溢出(心跳是Cat客户端自动向服务端发出的,里面包含了jvm本地磁盘IO等很多的内容,所以MesssageTree挺大的)。
因此数据在客户端的流程可以理解为:
Trasaction\Event-->MessageTree-->BlockingQueue-->netty发出网络流
即Transaction、Event等消息会先合并为消息树,以消息树为单位存储在内存中(并未进行本地持久化),专门有一个TcpSocketSender负责向外发送数据。
再说说服务端,服务端暂时看的不深,大体上可以理解为专门有一个TcpSocketReciever接收数据,由于数据在传输过程中是需要序列化的。因此接收后首先要进行decode,生成消息树。然后把消息放入BlockingQueue,有分析器不断的来队列拿消息树进行分析,分析后按照一定的规则把报表存储到数据库,把原始数据存储到本地文件中(默认是存储到本地)。
因此数据在服务端的流程大致可以理解为:
网络流-->decode反序列化-->BlockingQueue-->analyzer分析--->报表存储在DB
|---->原始数据存储在本地或hdfs
简单的Transaction例子
在Cat里面,消息大致可以分为几个类型:
- Transaction 有可能出错、需要记录处理的时间的监控,比如SQL查询、URL访问等
- Event 普通的监控,没有处理时间的要求,比如一次偶然的异常,一些基本的信息
- Hearbeat 心跳检测,常常用于一些基本的指标监控,一般是一分钟一次
- Metric 指标,比如有一个值,每次访问都要加一,就可以使用它
Transaction支持嵌套,即可以作为消息树的根节点,也可以作为叶子节点。但是Event、Heartbeat和Metric只能作为叶子节点。有了这种树形结构,就可以描述出下面这种调用链的结果了:

Transaction和Event的使用很简单,比如:
@RequestMapping("t")
public @ResponseBody String test() {
Transaction t = Cat.newTransaction("MY-TRANSACTION","test in TransactionTest");
try{
Cat.logEvent("EVENT-TYPE-1","EVENT-NAME-1");
// ....
}catch(Exception e){
Cat.logError(e);
t.setStatus(e);
}finally {
t.setStatus(Transaction.SUCCESS);
t.complete();
}
return "trasaction test!";
}
这是一个最基本的Transaction的例子。
分布式调用链监控
在分布式环境中,应用是运行在独立的进程中的,有可能是不同的机器,或者不同的服务器进程。那么他们如果想要彼此联系在一起,形成一个调用链,就需要通过几个ID进行串联。这种串联的模式,基本上都是一样的。
举个例子,A系统在aaa()中调用了B系统的bbb()方法,如果我们在aaa方法中埋点记录上面例子中的信息,在bbb中也记录信息,但是这两个信息是彼此独立的。因此就需要使用一个全局的id,证明他们是一个调用链中的调用方法。除此之外,还需要一个标识谁在调用它的ID,以及一个标识它调用的方法的ID。
总结来说,每个Transaction需要三个ID:
- RootId,用于标识唯一的一个调用链
- ParentId,父Id是谁?谁在调用我
- ChildId,我在调用谁?
其实ParentId和ChildId有点冗余,但是Cat里面还是都加上吧!
那么问题来了,如何传递这些ID呢?在Cat中需要你自己实现一个Context,因为Cat里面只提供了一个内部的接口:
public interface Context {
String ROOT = "_catRootMessageId";
String PARENT = "_catParentMessageId";
String CHILD = "_catChildMessageId";
void addProperty(String var1, String var2);
String getProperty(String var1);
}
我们需要自己实现这个接口,并存储相关的ID:
public class MyContext implements Cat.Context,Serializable{
private static final long serialVersionUID = 7426007315111778513L;
private Map<String,String> properties = new HashMap<String,String>();
@Override
public void addProperty(String s, String s1) {
properties.put(s,s1);
}
@Override
public String getProperty(String s) {
return properties.get(s);
}
}
由于这个Context需要跨进程网络传输,因此需要实现序列化接口。
在Cat中其实已经给我们实现了两个方法logRemoteCallClient以及logRemoteCallServer,可以简化处理逻辑,有兴趣可以看一下Cat中的逻辑实现:
//客户端需要创建一个Context,然后初始化三个ID
public static void logRemoteCallClient(Cat.Context ctx) {
MessageTree tree = getManager().getThreadLocalMessageTree();
String messageId = tree.getMessageId();//获取当前的MessageId
if(messageId == null) {
messageId = createMessageId();
tree.setMessageId(messageId);
}
String childId = createMessageId();//创建子MessageId
logEvent("RemoteCall", "", "0", childId);
String root = tree.getRootMessageId();//获取全局唯一的MessageId
if(root == null) {
root = messageId;
}
ctx.addProperty("_catRootMessageId", root);
ctx.addProperty("_catParentMessageId", messageId);//把自己的ID作为ParentId传给调用的方法
ctx.addProperty("_catChildMessageId", childId);
}
//服务端需要接受这个context,然后设置到自己的Transaction中
public static void logRemoteCallServer(Cat.Context ctx) {
MessageTree tree = getManager().getThreadLocalMessageTree();
String messageId = ctx.getProperty("_catChildMessageId");
String rootId = ctx.getProperty("_catRootMessageId");
String parentId = ctx.getProperty("_catParentMessageId");
if(messageId != null) {
tree.setMessageId(messageId);//把传过来的子ID作为自己的ID
}
if(parentId != null) {
tree.setParentMessageId(parentId);//把传过来的parentId作为
}
if(rootId != null) {
tree.setRootMessageId(rootId);//把传过来的RootId设置成自己的RootId
}
}
这样,结合前面的RMI调用,整个思路就清晰多了.
客户端调用者的埋点:
@RequestMapping("t2")
public @ResponseBody String test2() {
Transaction t = Cat.newTransaction("Call","test2");
try{
Cat.logEvent("Call.server","localhost");
Cat.logEvent("Call.app","business");
Cat.logEvent("Call.port","8888");
MyContext ctx = new MyContext();
Cat.logRemoteCallClient(ctx);
IBusiness business = (IBusiness) Naming.lookup("rmi://localhost:8888/Business");
business.echo("xingoo",ctx);
}catch(Exception e){
Cat.logError(e);
t.setStatus(e);
}finally {
t.setStatus(Transaction.SUCCESS);
t.complete();
}
return "cross!";
}
远程被调用者的埋点:
interface IBusiness extends Remote{
String echo(String message,MyContext ctx) throws RemoteException;
}
class BusinessImpl extends UnicastRemoteObject implements IBusiness {
public BusinessImpl() throws RemoteException {}
@Override
public String echo(String message,MyContext ctx) throws RemoteException {
Transaction t = Cat.newTransaction("Service","echo");
try{
Cat.logEvent("Service.client","localhost");
Cat.logEvent("Service.app","cat-client");
Cat.logRemoteCallServer(ctx);
System.out.println(message);
}catch(Exception e){
Cat.logError(e);
t.setStatus(e);
}finally {
t.setStatus(Transaction.SUCCESS);
t.complete();
}
return "hello,"+message;
}
}
public class RpcServer {
public static void main(String[] args) throws RemoteException, AlreadyBoundException, MalformedURLException {
IBusiness business = new BusinessImpl();
LocateRegistry.createRegistry(8888);
Naming.bind("rmi://localhost:8888/Business",business);
System.out.println("Hello, RMI Server!");
}
}
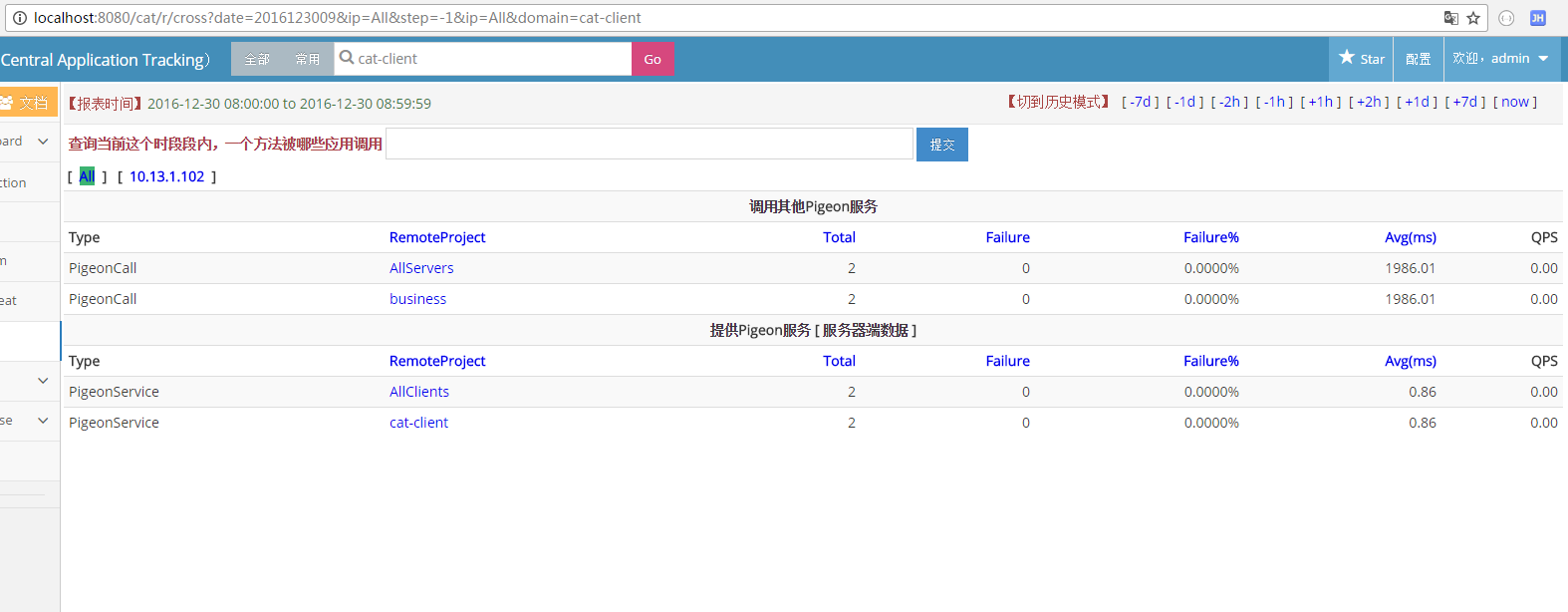
需要注意的是,Service的client和app需要和Call的server以及app对应上,要不然图表是分析不出东西的!
最后
Cat对于一些分布式的开源框架,都有很好的集成,比如dubbo,有兴趣的可以查看它在script中的文档,结合上面的例子可以更好地理解。
基于Cat的分布式调用追踪的更多相关文章
- 个推基于 Zipkin 的分布式链路追踪实践
作者:个推应用平台基础架构高级研发工程师 阿飞 01业务背景 随着微服务架构的流行,系统变得越来越复杂,单体的系统被拆成很多个模块,各个模块通过轻量级的通信协议进行通讯,相互协作,共同实现系统 ...
- 基于Dapper的分布式链路追踪入门——Opencensus+Zipkin+Jaeger
微信搜索公众号 「程序员白泽」,进入白泽的编程知识分享星球 最近做了一些分布式链路追踪有关的东西,写篇文章来梳理一下思路,或许可以帮到想入门的同学.下面我将从原理到demo为大家一一进行讲解,欢迎评论 ...
- Laravel + go-micro + grpc 实践基于 Zipkin 的分布式链路追踪系统 摘自https://mp.weixin.qq.com/s/JkLMNabnYbod-b4syMB3Hw?
分布式调用链跟踪系统,属于监控系统的一类.系统架构逐步演进时,后期形态往往是一个平台由很多不同的服务.组件构成,用户请求过来后,可能会经过其中多个服务,如图 不过,出问题时往往很难排查,如整个请求变慢 ...
- 基于Protobuf的分布式高性能RPC框架——Navi-Pbrpc
基于Protobuf的分布式高性能RPC框架——Navi-Pbrpc 二月 8, 2016 1 简介 Navi-pbrpc框架是一个高性能的远程调用RPC框架,使用netty4技术提供非阻塞.异步.全 ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- 手撸基于swoole 的分布式框架 实现分布式调用(20)讲
最近看的一个swoole的课程,前段时间被邀请的参与的这个课程 比较有特点跟一定的深度,swoole的实战教程一直也不多,结合swoole构建一个新型框架,最后讲解如何实现分布式RPC的调用. 内容听 ...
- 分布式服务追踪与调用链 Zikpin
分布式服务追踪与调用链系统产生的背景 在为服务中,如果服务与服务之间的依赖关系非常复杂,如果某个服务出现了一些问题,很难追查到原因,特别是服务与服务之间调用的时候. 在微服务系统中,随着业务的发展,系 ...
- (Dubbo架构)基于MDC+Filter的跨应用分布式日志追踪解决方案
在单体应用中,日志追踪通常的解决方案是给日志添加 tranID(追踪ID),生成规则因系统而异,大致效果如下: 查询时只要使用 grep 命令进行追踪id筛选即可查到此次调用链中所有日志,但是在 du ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
随机推荐
- 问题记录:EntityFramework 一对一关系映射
EntityFramework 一对一关系映射有很多种,比如主键作为关联,配置比较简单,示例代码: public class Teacher { public int Id { get; set; } ...
- Velocity笔记--使用Velocity获取动态Web项目名的问题
以前使用jsp开发的时候,可以通过request很轻松的获取到根项目名,现在换到使用velocity渲染视图,因为已经不依赖servlet,request等一些类的环境,而Web项目的根项目名又不是写 ...
- mount报错: you must specify the filesystem type
在linux mount /dev/vdb 到 /home 分区时报错: # mount /dev/vdb /homemount: you must specify the filesystem ty ...
- SSH框架和Redis的整合(2)
5. 添加功能的实现 新建一个Action:RClasAction,实现向Redis添加课程数据,并同步到MySQL. package com.school.action; import java.u ...
- UML图中经常用到几种的关系图例
学习这个东西挺奇怪的,时间一长就容易忘记,或者记不清楚.今天看到一些UML图的关系,发现有些出入了,索性就写下来,以后再忘记的时候过来看看. 在UML的类图中,常见的有以下几种关系: 继承(Gener ...
- iOS 数据存储之SQLite3的使用
SQLite3是iOS内嵌的数据库,SQLite3在存储和检索大量数据方面非常有效,它使得不必将每个对象都加到内存中.还能够对数据进行负责的聚合,与使用对象执行这些操作相比,获得结果的速度更快. SQ ...
- 1.Hibernate简介
1.框架简介: 定义:基于java语言开发的一套ORM框架: 优点:a.方便开发; b.大大减少代码量; c.性能稍高(不能与数据库高手相比,较一般数据库使用者 ...
- Visual Studio Code,完美的编辑器
今日凌晨,微软的文本(代码)编辑器 Visual Studio Code(简称 VS Code),发布了首个正式版,距离首个 beta 版上线时间刚好一年. 在十多年的编程经历中,我使用过非常多的的代 ...
- Linux下UPnP sample分析
一.UPnP简介 UPnP(Universal Plug and Play)技术是一种屏蔽各种数字设备的硬件和操作系统的通信协议.它是一种数字网络中间件技术,建立在TCP/IP.HTTP协 ...
- Java线程池解析
Java的一大优势是能完成多线程任务,对线程的封装和调度非常好,那么它又是如何实现的呢? jdk的包下和线程相关类的类图. 从上面可以看出Java的线程池主的实现类主要有两个类ThreadPoolEx ...