cf.VK CUP 2015.B.Mean Requests
4 seconds
256 megabytes
standard input
standard output
In this problem you will have to deal with a real algorithm that is used in the VK social network.
As in any other company that creates high-loaded websites, the VK developers have to deal with request statistics regularly. An important indicator reflecting the load of the site is the mean number of requests for a certain period of time of T seconds (for example, T = 60 seconds = 1 min and T = 86400 seconds = 1 day). For example, if this value drops dramatically, that shows that the site has access problem. If this value grows, that may be a reason to analyze the cause for the growth and add more servers to the website if it is really needed.
However, even such a natural problem as counting the mean number of queries for some period of time can be a challenge when you process the amount of data of a huge social network. That's why the developers have to use original techniques to solve problems approximately, but more effectively at the same time.
Let's consider the following formal model. We have a service that works for n seconds. We know the number of queries to this resourceat at each moment of time t (1 ≤ t ≤ n). Let's formulate the following algorithm of calculating the mean with exponential decay. Let c be some real number, strictly larger than one.
// setting this constant value correctly can adjust // the time range for which statistics will be calculated double c = some constant value;
// as the result of the algorithm's performance this variable will contain // the mean number of queries for the last // T seconds by the current moment of time double mean = 0.0;
for t = 1..n: // at each second, we do the following: // at is the number of queries that came at the last second; mean = (mean + at / T) / c;
Thus, the mean variable is recalculated each second using the number of queries that came at that second. We can make some mathematical calculations and prove that choosing the value of constant c correctly will make the value of mean not very different from the real mean value ax at t - T + 1 ≤ x ≤ t.
The advantage of such approach is that it only uses the number of requests at the current moment of time and doesn't require storing the history of requests for a large time range. Also, it considers the recent values with the weight larger than the weight of the old ones, which helps to react to dramatic change in values quicker.
However before using the new theoretical approach in industrial programming, there is an obligatory step to make, that is, to test its credibility practically on given test data sets. Your task is to compare the data obtained as a result of the work of an approximate algorithm to the real data.
You are given n values at, integer T and real number c. Also, you are given m moments pj (1 ≤ j ≤ m), where we are interested in the mean value of the number of queries for the last T seconds. Implement two algorithms. The first one should calculate the required value by definition, i.e. by the formula 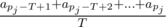 . The second algorithm should calculate the mean value as is described above. Print both values and calculate the relative error of the second algorithm by the formula
. The second algorithm should calculate the mean value as is described above. Print both values and calculate the relative error of the second algorithm by the formula 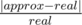 , where approx is the approximate value, obtained by the second algorithm, and real is the exact value obtained by the first algorithm.
, where approx is the approximate value, obtained by the second algorithm, and real is the exact value obtained by the first algorithm.
The first line contains integer n (1 ≤ n ≤ 2·105), integer T (1 ≤ T ≤ n) and real number c (1 < c ≤ 100) — the time range when the resource should work, the length of the time range during which we need the mean number of requests and the coefficient c of the work of approximate algorithm. Number c is given with exactly six digits after the decimal point.
The next line contains n integers at (1 ≤ at ≤ 106) — the number of queries to the service at each moment of time.
The next line contains integer m (1 ≤ m ≤ n) — the number of moments of time when we are interested in the mean number of queries for the last T seconds.
The next line contains m integers pj (T ≤ pj ≤ n), representing another moment of time for which we need statistics. Moments pj are strictly increasing.
Print m lines. The j-th line must contain three numbers real, approx and error, where:
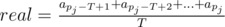 is the real mean number of queries for the last T seconds;
is the real mean number of queries for the last T seconds;- approx is calculated by the given algorithm and equals mean at the moment of time t = pj (that is, after implementing the pj-th iteration of the cycle);
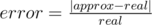 is the relative error of the approximate algorithm.
is the relative error of the approximate algorithm.
The numbers you printed will be compared to the correct numbers with the relative or absolute error 10 - 4. It is recommended to print the numbers with at least five digits after the decimal point.
1 1 2.000000 1 1 1
1.000000 0.500000 0.500000
11 4 1.250000 9 11 7 5 15 6 6 6 6 6 6 8 4 5 6 7 8 9 10 11
8.000000 4.449600 0.443800 9.500000 6.559680 0.309507 8.250000 6.447744 0.218455 8.000000 6.358195 0.205226 8.250000 6.286556 0.237993 6.000000 6.229245 0.038207 6.000000 6.183396 0.030566 6.000000 6.146717 0.024453
13 4 1.250000 3 3 3 3 3 20 3 3 3 3 3 3 3 10 4 5 6 7 8 9 10 11 12 13
3.000000 1.771200 0.409600 3.000000 2.016960 0.327680 7.250000 5.613568 0.225715 7.250000 5.090854 0.297813 7.250000 4.672684 0.355492 7.250000 4.338147 0.401635 3.000000 4.070517 0.356839 3.000000 3.856414 0.285471 3.000000 3.685131 0.228377 3.000000 3.548105 0.182702
我看不懂关于real的那个公式。后来发现他是前T个的mean,orz
#include<stdio.h>
#include<string.h>
#include<math.h>
using namespace std;
typedef long long ll ;
const int M = * 1e5 + ;
int a [M] ;
int n , T , m;
double c ;
double real , mean , error ; int main ()
{
// freopen ("a.txt" , "r" , stdin ) ;
scanf ("%d%d%lf" , &n , &T , &c) ;
for (int i = ; i <= n ; i++) {
scanf ("%d", &a[i] ) ;
}
scanf ("%d" , &m) ; int b[M] ;
for (int i = ; i <= m ; i++) {
scanf ("%d" , &b[i]) ;
}
double sum = ;
double mean = ;
int k = ;
for (int i = ; i <= n ; i++) {
sum += a[i] ;
if (i > T) {
sum -= a[i - T] ;
}
mean = (double) 1.0 * (mean + 1.0 * a[i] / T) / c ;
if (i == b[k]) {
real = 1.0 * sum / T ;
error = fabs (real - mean) / real ;
printf ("%.6f %.6f %.6f\n" , real , mean , error ) ;
k++ ;
}
}
return ;
}
cf.VK CUP 2015.B.Mean Requests的更多相关文章
- cf.VK CUP 2015.C.Name Quest(贪心)
Name Quest time limit per test 2 seconds memory limit per test 256 megabytes input standard input ou ...
- Codeforces Round VK Cup 2015 - Round 1 (unofficial online mirror, Div. 1 only)E. The Art of Dealing with ATM 暴力出奇迹!
VK Cup 2015 - Round 1 (unofficial online mirror, Div. 1 only)E. The Art of Dealing with ATM Time Lim ...
- Codeforces VK CUP 2015 D. Closest Equals(线段树+扫描线)
题目链接:http://codeforces.com/contest/522/problem/D 题目大意: 给你一个长度为n的序列,然后有m次查询,每次查询输入一个区间[li,lj],对于每一个查 ...
- VK Cup 2015 - Round 2 (unofficial online mirror, Div. 1 only) E. Correcting Mistakes 水题
E. Correcting Mistakes Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/problemset ...
- VK Cup 2015 - Finals, online mirror D. Restructuring Company 并查集
D. Restructuring Company Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest/5 ...
- VK Cup 2015 - Round 1 -E. Rooks and Rectangles 线段树最值+扫描线
题意: n * m的棋盘, k个位置有"rook"(车),q次询问,问是否询问的方块内是否每一行都有一个车或者每一列都有一个车? 满足一个即可 先考虑第一种情况, 第二种类似,sw ...
- VK Cup 2015 - Round 2 (unofficial online mirror, Div. 1 only) B. Work Group 树形dp
题目链接: http://codeforces.com/problemset/problem/533/B B. Work Group time limit per test2 secondsmemor ...
- VK Cup 2015 - Qualification Round 1 D. Closest Equals 离线+线段树
题目链接: http://codeforces.com/problemset/problem/522/D D. Closest Equals time limit per test3 secondsm ...
- codeforces VK Cup 2015 - Qualification Round 1 B. Photo to Remember 水题
B. Photo to Remember Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest/522/ ...
随机推荐
- 玩转数据库之 Group by Grouping
有的时候我们要从数据库里把数据组织成树结构再展现到页面上 像下面这样 今天我们用Group 和Grouping实现它,并总结一下它俩. 先看一下概念,再用代码一点一点去理解它们,最后我会给出完整的代码 ...
- 嵌入式linux驱动开发之给linux系统添加温度传感器模块
忙了几天,终于可以让ds18b20在自己的开发板的linux系统上跑了!虽然ds18b20不是什么新鲜玩意,但是想想知己可以给linux系统添加模块了还是有点小鸡冻呢! 虽然说现在硬件的资源非常丰富而 ...
- Java并发编程-CopyOnWriteArrayList
CopyOnWriteArrayList原理 首先每次写操作,都将数组copy一份,并赋值给arrays 读操作读不加锁 写操作加锁 ReentrantLock 因为每次写都要copy数组,这是一项繁 ...
- 状态机——Javascript词法扫描示例
所谓的状态机实质其实很很简单,其存在的目的也是把大量复杂的处理分散,使处理变得简单化一些.状态机只有一个当前状态,并且在当前状态下根据输入进行处理,然后再决定是否改变当前状态,然后再处理下一个输入,如 ...
- ThinkPHP之项目搭建
前言 在做javaweb开发时,我们创建一个项目,MyEclipse会自动为我们生成相应的目录结构,我们在此结构上才进行web开发,在使用TinkPHP框架做PHP开发时,一样,我们如何生成一个标准的 ...
- HTML5——购物车
简要代码: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w ...
- javascript函数自调用
1. 函数是由事件驱动的或者当它被调用时执行的可重复使用的代码块. 2. 将函数用 “()”括起来, 后面再加一个“()” 3. javascript函数的内置对象arguments对象, 它包 ...
- php empty()和isset()的区别
在使用 php 编写页面程序时,我经常使用变量处理函数判断 php 页面尾部参数的某个变量值是否为空,开始的时候我习惯了使用 empty() 函数,却发现了一些问题,因此改用 isset() 函数,问 ...
- OC基础--关键字@property 和 @synthesize
一.@property关键字需要掌握的知识: 1.用在@interface中,用来自动生成setter和getter的声明 例:@property int age;--相当于执行了右边的代码--> ...
- hdu4287 字典树
#include<stdio.h> #include<string.h> #include<stdlib.h> #define maxn 10 struct tri ...