Kafka - SQL 引擎分享
1.概述
大多数情况下,我们使用 Kafka 只是作为消息处理。在有些情况下,我们需要多次读取 Kafka 集群中的数据。当然,我们可以通过调用 Kafka 的 API 来完成,但是针对不同的业务需求,我们需要去编写不同的接口,在经过编译,打包,发布等一系列流程。最后才能看到我们预想的结果。那么,我们能不能有一种简便的方式去实现这一部分功能,通过编写 SQL 的方式,来可视化我们的结果。今天,笔者给大家分享一些心得,通过使用 SQL 的形式来完成这些需求。
2.内容
实现这些功能,其架构和思路并不复杂。这里笔者将整个实现流程,通过一个原理图来呈现。如下图所示:

这里笔者给大家详述一下上图的含义,消息数据源存放与 Kafka 集群当中,开启低阶和高阶两个消费线程,将消费的结果以 RPC 的方式共享出去(即:请求者)。数据共享出去后,回流经到 SQL 引擎处,将内存中的数据翻译成 SQL Tree,这里使用到了 Apache 的 Calcite 项目来承担这一部分工作。然后,我们通过 Thrift 协议来响应 Web Console 的 SQL 请求,最后将结果返回给前端,让其以图表的实行可视化。
3.插件配置
这里,我们需要遵循 Calcite 的 JSON Models,比如,针对 Kafka 集群,我们需要配置一下内容:
{
version: '1.0',
defaultSchema: 'kafka',
schemas: [
{
name: 'kafka',
type: 'custom',
factory: 'cn.smartloli.kafka.visual.engine.KafkaMemorySchemaFactory',
operand: {
database: 'kafka_db'
}
}
]
}
另外,这里最好对表也做一个表述,配置内容如下所示:
[
{
"table":"Kafka",
"schemas":{
"_plat":"varchar",
"_uid":"varchar",
"_tm":"varchar",
"ip":"varchar",
"country":"varchar",
"city":"varchar",
"location":"jsonarray"
}
}
]
4.操作
下面,笔者给大家演示通过 SQL 来操作相关内容。相关截图如下所示:
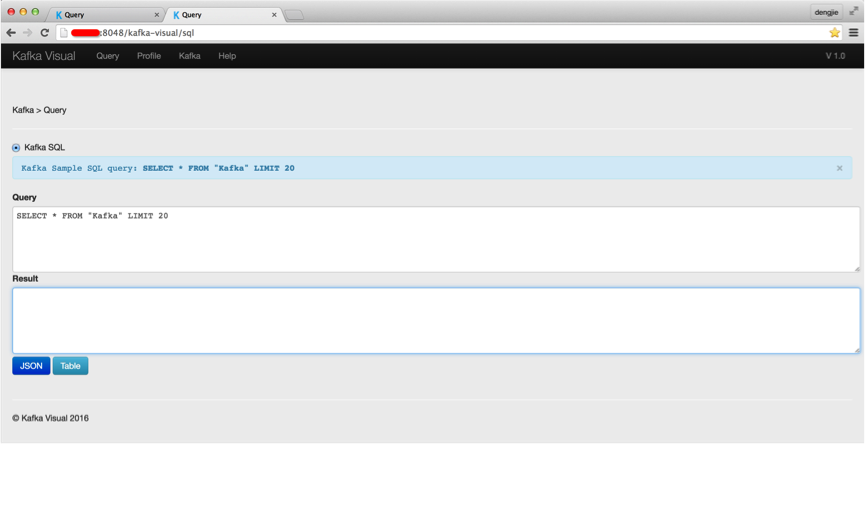
在查询处,填写相关 SQL 查询语句。点击 Table 按钮,得到如下所示结果:

我们,可以将获取的结果以报表的形式进行导出。
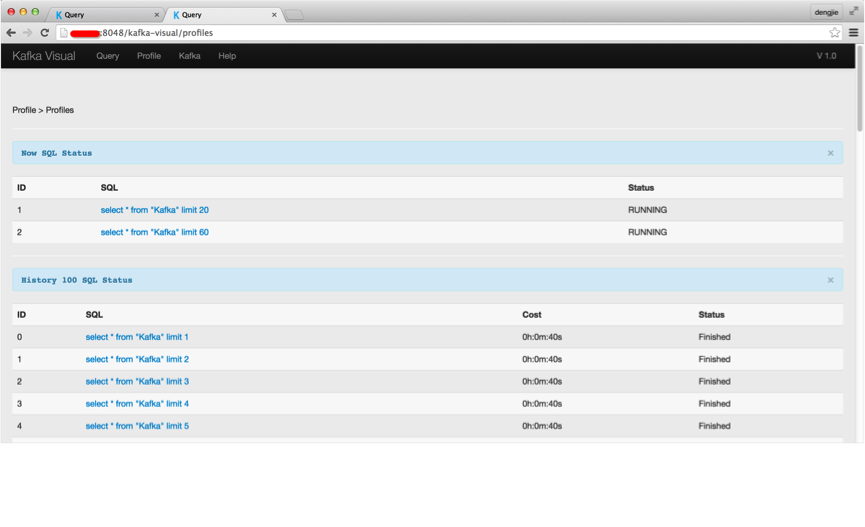
当然,我们可以在 Profile 模块下,浏览查询历史记录和当前正在运行的查询任务。至于其他模块,都属于辅助功能(展示集群信息,Topic 的 Partition 信息等)这里就不多赘述了。
5.总结
分析下来,整体架构和实现的思路都不算太复杂,也不存在太大的难点,需要注意一些实现上的细节,比如消费 API 针对集群消息参数的调整,特别是低阶消费 API,尤为需要注意,其 fetch_size 的大小,以及 offset 是需要我们自己维护的。在使用 Calcite 作为 SQL 树时,我们要遵循其 JSON Model 和标准的 SQL 语法来操作数据源。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Kafka - SQL 引擎分享的更多相关文章
- Kafka - SQL 引擎
Kafka - SQL 引擎分享 1.概述 大多数情况下,我们使用 Kafka 只是作为消息处理.在有些情况下,我们需要多次读取 Kafka 集群中的数据.当然,我们可以通过调用 Kafka 的 AP ...
- Kafka - SQL 代码实现
1.概述 上次给大家分享了关于 Kafka SQL 的实现思路,这次给大家分享如何实现 Kafka SQL.要实现 Kafka SQL,在上一篇<Kafka - SQL 引擎分享>中分享了 ...
- 重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL.推出KSQL 是为了降低流式处理的门槛,为处理 ...
- 开发一个不需要重写成Hive QL的大数据SQL引擎
摘要:开发一款能支持标准数据库SQL的大数据仓库引擎,让那些在Oracle上运行良好的SQL可以直接运行在Hadoop上,而不需要重写成Hive QL. 本文分享自华为云社区< ...
- 20个免费的 JavaScript 游戏引擎分享给开发者
这篇文章收集了20个免费的 JavaScript 游戏引擎分享给开发者.这些游戏引擎能够帮助游戏开发人员更快速高效的开发出各种好玩的游戏. 使用 HTML5.CSS3 和 Javascript 可以帮 ...
- DRDS分布式SQL引擎—执行计划介绍
摘要: 本文着重介绍 DRDS 执行计划中各个操作符的含义,以便用户通过查询计划了解 SQL 执行流程,从而有针对性的调优 SQL. DRDS分布式SQL引擎 — 执行计划介绍 前言 数据库系统中,执 ...
- 六大主流开源SQL引擎
导读 本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以 ...
- 六大主流开源SQL引擎总结
本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以及2个 ...
- 大数据时代快速SQL引擎-Impala
背景 随着大数据时代的到来,Hadoop在过去几年以接近统治性的方式包揽的ETL和数据分析查询的工作,大家也无意间的想往大数据方向靠拢,即使每天数据也就几十.几百M也要放到Hadoop上作分析,只会适 ...
随机推荐
- 使用的组件:ckeditor
老牌Web文本编辑器,无需多言. 官网地址:http://ckeditor.com/
- Orchard Compact v1.7.2
1. 仅包留了Core中的Settings和Shapes, 及Modules, Themes和jQuery模块. 2. 添加了对Oracle的支持. 下载地址: 二进制: Orchard.Compac ...
- 大熊君说说JS与设计模式之------状态模式State
一,总体概要 1,笔者浅谈 状态模式,又称状态对象模式(Pattern of Objects for States),状态模式是对象的行为模式. 状态模式主要解决的是当控制一个对象状态的条件表达式过于 ...
- 在Mac/Linux/Windows上编译corefx遇到的问题及解决方法
这两天尝试在Mac/Linux/Windows三大平台上编译.NET跨平台三驾马车(coreclr/corefx/dnx)之一的corefx(.NET Core Framework),结果三个平台的编 ...
- onFocus="this.blur()"的解释
onFocus="this.blur()" onFocus即获取焦点的意思,而blur却是失去焦点的意思,因此onFocus="this.blur()"的通俗理 ...
- [自娱自乐] 3、超声波测距模块DIY笔记(三)
前言 上一节我们已经研究了超声波接收模块并自己设计了一个超声波接收模块,在此基础上又尝试用单片机加反相器构成生成40KHz的超声波发射电路,可是发现采用这种设计的发射电路存在严重的发射功率太低问题,对 ...
- Jenkins pipeline 入门到精通系列文章
Jenkins2 入门到精通系列文章. Jenkins2 下载与启动jenkins2 插件安装jenkins2 hellopipelinejenkins2 pipeline介绍jenkins2 jav ...
- [DOS] Net Use
Please use following command for regist a login user. net use \\server\folder [password] /user:[use ...
- ClassLoader.getSystemResourceAsStream()
一: 要加载的文件和.class文件在同一目录下,例如:com.x.y 下有类Test.class ,同时有资源文件config.properties 那么,应该有如下代码: //前面没有" ...
- 使用TabBarController(代码实现)
step01:使用Xcode创建一个项目 step02:填写项目必要信息 step03:检查文件结构树是否正确 step04:创建一些类,这些类将会在后面用到!(选择Swift File) step0 ...