Autoencoders and Sparsity(一)
An autoencoder neural network is an unsupervised learning algorithm that applies backpropagation, setting the target values to be equal to the inputs. I.e., it uses 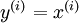 .
.
Here is an autoencoder:
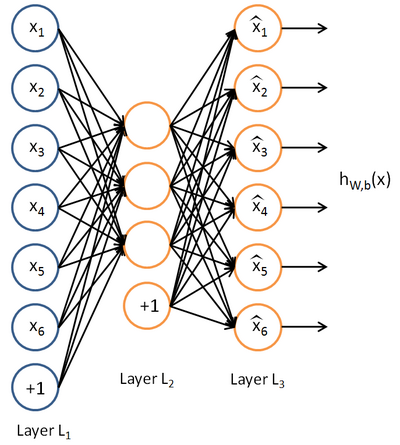
The autoencoder tries to learn a function 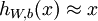 . In other words, it is trying to learn an approximation to the identity function, so as to output
. In other words, it is trying to learn an approximation to the identity function, so as to output 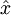 that is similar to
that is similar to  . The identity function seems a particularly trivial function to be trying to learn; but by placing constraints on the network, such as by limiting the number of hidden units, we can discover interesting structure about the data.
. The identity function seems a particularly trivial function to be trying to learn; but by placing constraints on the network, such as by limiting the number of hidden units, we can discover interesting structure about the data.
例子&用途
As a concrete example, suppose the inputs
image (100 pixels) so
, and there are
hidden units in layer
. Note that we also have
. Since there are only 50 hidden units, the network is forced to learn a compressed representation of the input. I.e., given only the vector of hidden unit activations
, it must try to reconstruct the 100-pixel input
comes from an IID Gaussian independent of the other features---then this compression task would be very difficult. But if there is structure in the data, for example, if some of the input features are correlated, then this algorithm will be able to discover some of those correlations. In fact, this simple autoencoder often ends up learning a low-dimensional representation very similar to PCAs
约束
Our argument above relied on the number of hidden units
being small. But even when the number of hidden units is large (perhaps even greater than the number of input pixels), we can still discover interesting structure, by imposing other constraints on the network. In particular, if we impose a sparsity constraint on the hidden units, then the autoencoder will still discover interesting structure in the data, even if the number of hidden units is large.
Recall that
denotes the activation of hidden unit
in the autoencoder. However, this notation doesn't make explicit what was the input
to denote the activation of this hidden unit when the network is given a specific input
be the average activation of hidden unit
where
is a sparsity parameter, typically a small value close to zero (say
). In other words, we would like the average activation of each hidden neuron
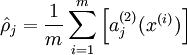
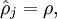
To achieve this, we will add an extra penalty term to our optimization objective that penalizes
deviating significantly from
Here,
where
is the Kullback-Leibler (KL) divergence between a Bernoulli random variable with mean
偏离,惩罚
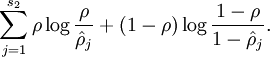
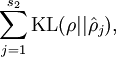
损失函数
无稀疏约束时网络的损失函数表达式如下:
带稀疏约束的损失函数如下:
where
is as defined previously, and
controls the weight of the sparsity penalty term. The term
also, because it is the average activation of hidden unit
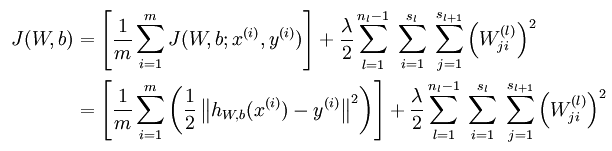
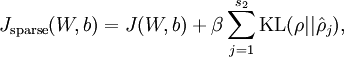
损失函数的偏导数的求法
而加入了稀疏性后,神经元节点的误差表达式由公式:
变成公式:

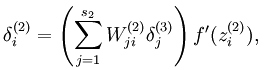
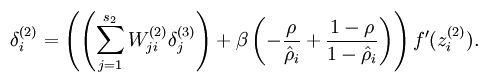
梯度下降法求解
有了损失函数及其偏导数后就可以采用梯度下降法来求网络最优化的参数了,整个流程如下所示:
从上面的公式可以看出,损失函数的偏导其实是个累加过程,每来一个样本数据就累加一次。这是因为损失函数本身就是由每个训练样本的损失叠加而成的,而按照加法的求导法则,损失函数的偏导也应该是由各个训练样本所损失的偏导叠加而成。从这里可以看出,训练样本输入网络的顺序并不重要,因为每个训练样本所进行的操作是等价的,后面样本的输入所产生的结果并不依靠前一次输入结果(只是简单的累加而已,而这里的累加是顺序无关的)。
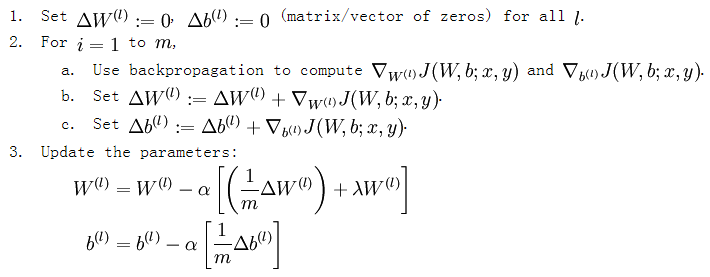
转自:http://www.cnblogs.com/tornadomeet/archive/2013/03/19/2970101.html
Autoencoders and Sparsity(一)的更多相关文章
- (六)6.4 Neurons Networks Autoencoders and Sparsity
BP算法是适合监督学习的,因为要计算损失函数,计算时y值又是必不可少的,现在假设有一系列的无标签train data: ,其中 ,autoencoders是一种无监督学习算法,它使用了本身作为标签以 ...
- CS229 6.4 Neurons Networks Autoencoders and Sparsity
BP算法是适合监督学习的,因为要计算损失函数,计算时y值又是必不可少的,现在假设有一系列的无标签train data: ,其中 ,autoencoders是一种无监督学习算法,它使用了本身作为标签以 ...
- Autoencoders and Sparsity(二)
In this problem set, you will implement the sparse autoencoder algorithm, and show how it discovers ...
- 【DeepLearning】UFLDL tutorial错误记录
(一)Autoencoders and Sparsity章节公式错误: s2 应为 s3. 意为从第2层(隐藏层)i节点到输出层j节点的误差加权和. (二)Support functions for ...
- Deep Learning 教程翻译
Deep Learning 教程翻译 非常激动地宣告,Stanford 教授 Andrew Ng 的 Deep Learning 教程,于今日,2013年4月8日,全部翻译成中文.这是中国屌丝军团,从 ...
- 三层神经网络自编码算法推导和MATLAB实现 (转载)
转载自:http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724.html 前言: 现在来进入sparse autoencoder的一 ...
- DL二(稀疏自编码器 Sparse Autoencoder)
稀疏自编码器 Sparse Autoencoder 一神经网络(Neural Networks) 1.1 基本术语 神经网络(neural networks) 激活函数(activation func ...
- Sparse Autoencoder(二)
Gradient checking and advanced optimization In this section, we describe a method for numerically ch ...
- 【DeepLearning】Exercise:Learning color features with Sparse Autoencoders
Exercise:Learning color features with Sparse Autoencoders 习题链接:Exercise:Learning color features with ...
随机推荐
- sql server 中查询数据库下有多少张表以及同义词等信息
--查询数据库有多少张表SELECT count(0) from sysobjects where xtype = 'u' 复制代码 解释:sysobjects系统对象表. 保存当前数据库的对象.如约 ...
- 51Nod 蜥蜴和地下室(搜索)
哈利喜欢玩角色扮演的电脑游戏<蜥蜴和地下室>.此时,他正在扮演一个魔术师.在最后一关,他必须和一排的弓箭手战斗.他唯一能消灭他们的办法是一个火球咒语.如果哈利用他的火球咒语攻击第i个弓箭手 ...
- vue的webpack打包
一个完整的项目离不开 开发环境 生产环境 测试环境 这三个环境 首先解释一下这三个环境的含义 开发环境:开发环境是程序猿们专门用于开发的服务器,配置可以比较随意,为了开发调试方便,一般打开全部错误报告 ...
- DedeCMS文章编辑不更新时间1970年1月1日
在修改文章或者后期优化的时候,织梦dedecms5.7版本存在一个问题,修改文章的同时也修改了文章的发布时间,这个功能可能有些人比较需要,但同时也有些站长朋友又不需要,因为我们编辑某个文章的时候,发现 ...
- 【转载】解决django models文件修改后的数据库同步问题——south模块
转载链接:https://www.cnblogs.com/frchen/p/5732490.html 在使用django进行开发时,往往需要根据不同的需求对model进行更改.而这时候,python ...
- caioj 1087 动态规划入门(非常规DP11:潜水员)(二维背包)
这道题的难点在于价值可以多. 这道题我一开始用的是前面的状态推现在的状态 实现比较麻烦,因为价值可以多,所以就设最大价值 为题目给的最大价值乘以10 #include<cstdio> #i ...
- linux学习之高并发服务器篇(二)
高并发服务器 1.线程池并发服务器 两种模型: 预先创建阻塞于accept多线程,使用互斥锁上锁保护accept(减少了每次创建线程的开销) 预先创建多线程,由主线程调用accept 线程池 3.多路 ...
- 【习题 8-18 UVA - 1619】Feel Good
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 用单调队列求出l[i]和r[i] 分别表示i的左边最近的大于a[i]的数的位置以及i右边最近的大于a[i]的数的位置. 则l[i]+ ...
- DOM基础及DOM操作HTML
文件对象模型(Document Object Model.简称fr=aladdin" target="_blank">DOM).是W3C组织推荐的处理可扩展标 ...
- 免费WiFi初体验——个小白的WiFi旅程
说来羞愧,真正接触到WiFi还是在毕业后,此前自己封闭在一个人的世界,再加上外在学校的包围,我还成了个"山里"的孩子. 去年毕业了,也算是个90后,可自觉得心态过于成熟.了解外界太 ...