Flume基本概念
1 Apache Flume
1.1 概述
Flume是Cloudera提供的一个高可用,高可靠的,分布式的海量日志采集、聚合和传输的软件。
Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据。
Flume支持定制各类数据发送方,用于收集各类型数据:同时,Flume支持定制各种数据接受放,用于最终存储数据。一般的采集需求,通过对flume的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume可以适用于大部分的日常数据采集场景。
当前Flume有两个版本。Flume0.9X版本的通常Flume OG(original generation),Flume1.X版本的统称Flume NG(next generation)。由于Flume NG经过核心组件、核心配置以及代码架构重构,与Flume OG有很大不同,使用时请注意区分。改动的另一个原因是将Flume纳入Apache旗下,Cloudera Flume改名为Apache Flume。
1.2 运行机制
Flume日志采集传输系统中核心的角色是agent,agent本身是一个java进程,一般运行在日志收集节点,当然也可以运行在数据下沉的节点。Source、Sink、Channel三个组件是Flume运行的核心。
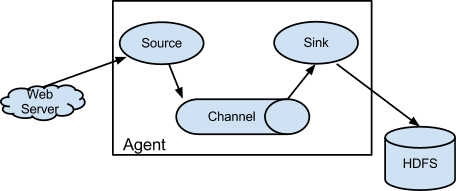
每一个agent相当于一个数据传递员,关于三个组件的介绍:
Source:采集源,用于跟数据源对接,以获取数据;
Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据;
Channel:agent内部的数据传输通道,用于从source将数据传递到sink;
在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本的单元。event将传输的数据进行封装。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的event包括:event headers、event body、event信息,其中event信息就是flume收集到的日记记录。
1.3 Flume采集系统结构图
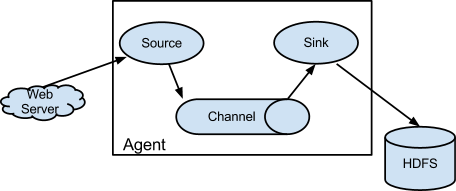
1.3.1 简单结构
单个agent采集数据
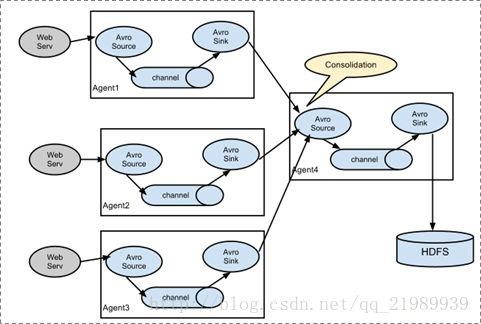
1.3.2 复杂结构
多级agent之间串联。
我们知道Flume一个很重要的功能就是应用于大数据环境中采集日志信息,那么对于分布式系统就需要用到下面这种复杂结构的Flume采集系统。在每一台服务器上都部署一个agent进程进行数据采集,再通过一个agent进程对所有采集到的数据进行汇总,并下沉到数据存储系统。
1.4 官网
documentation-> Flume User Guide页面左边菜单的Configuration下面我们可以看到Flume Sources、Flume Sinks、Flume Channels。这里所列举的数据源、下沉地和传输通道基本上包含了大数据领域常用的软件,能满足大部分的需求,特殊情况下Flume也支持自定义。
由此我们也可以知道,Flume使用起来重点在于采集方案的配置。针对采集需求使用的是什么样的source、sink和channel,把服务配置好并启动起来,就可以进行数据采集、数据的传输和数据的下沉。
Flume基本概念的更多相关文章
- flume基本概念及相关参数详解
1.flume是分布式的日志收集系统,把手机来的数据传送到目的地去 2.flume传输的数据的基本单位是 event,如果是文本文件,通常是一行记录. event代表着一个数据流的最小完整 ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- 利用Flume将MySQL表数据准实时抽取到HDFS
转自:http://blog.csdn.net/wzy0623/article/details/73650053 一.为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取 ...
- Flume架构以及应用介绍[转]
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出 ...
- Flume架构以及应用介绍
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引 ...
- Flume日志收集系统介绍
转自:http://blog.csdn.net/a2011480169/article/details/51544664 在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Ha ...
- 吴超老师课程--Flume的安装和介绍
常用的分布式日志收集系统
- flume介绍及应用
版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 flume的概念 1. ...
随机推荐
- leetcode快排相关
leetcode:75颜色分类(3way).215数组中的第K个最大元素(normal) 3way private static void quick3waySort(int[] arr, int l ...
- thinkphp关联操作
比如:你要求删除用户的时候,同时删除与用户有关的所有信息. 一对一: 有 (HAS_ONE) 属于 (BELONGS_TO) 一对多: 有 (HAS_MANY) 属于 (BELONG_ ...
- 小HY的四元组
4.7 比赛T1,然而这题爆零了 其实很简单的...其实哈希都不用 所以首先记录每组的差值,按其sort一下再暴力找即可 #include<cstdio> #include<iost ...
- dubbo+zookeeper下生产者和消费者配置(基于springboot开发)
一.总共分为三个目录: dubbo-api 服务的接口用于对接客户端和服务端 dubbo-client 客户端配置文件为:consumer.xml dubbo-service 服务 ...
- ASP.NET MVC5 之 Log4Net 的学习和使用
最近在学习 log4Net 插件,在博客园找到了好多资料,但是实现起来还是有点麻烦. 现在记录下学习的过程,期间可能加载着借鉴和转载的代码. 1.配置文件的设置: 新建config文件夹下 log4n ...
- 灾备还原之gitlab
灾备还原之gitlab 备份情景:服务器A架设了gitlab,定期通过duplicity发送加密备份给B服务器,现在由于某种情况生产机器A完全无法访问(主机商跑路?硬盘冒烟?服务器BOOM了?),本地 ...
- 在下载jar包时,要有三个包,分别为使用的把class、查看文档的api、查看源代码的资源包
字节码包: spring-webmvc-4.1.6.RELEASE.jar 文档包: spring-webmvc-4.1.6.RELEASE-javadoc.jar 资源包: webmvc ...
- mysql外键创建失败原因
引用:http://blog.csdn.net/wangpeng047/article/details/19624351 首先,如果和外键相关的几张表中已经插入了数据,可能导致外键插入的失败 在MyS ...
- iOS CoreData 开发
新年新气象,曾经的妹子结婚了,而光棍的我决定书写博客~ 废话结束. 本人不爱使用第三方的东东,喜欢原汁原味的官方版本,本次带来CoreData数据存储篇~ 创建应用
- Unity引擎 UGUI
Unity UGUI讲解 1.导入UI图片资源 2.设置参数: TextureType(纹理类型) 精灵 2D and UI SpriteMode(精灵模式) Single(单) multiple( ...