初识Scrapy——1—scrapy简单学习,伯乐在线实战、json数据保存
Scrapy——1
目录
什么是Scrapy框架?
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。多用于抓取大量静态页面。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常方便。
- Scrapy使用了Twisted[‘twistid](其主要对手是Toronto)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy的安装
- Windows安装
pip install Scrapy
Windows使用Scrapy需要很多的依赖环境,根据个人的电脑的情况而定,在cmd的安装下,缺少的环境会报错提示,在此网站下搜索下载,通过wheel方法安装即可。如果不懂wheel法安装的,可以参考我之前的随笔,方法雷同
- 虚拟机Ubuntu的安装
通过如下代码安装依赖环境,最后也是通过pip install Scrapy进行安装
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
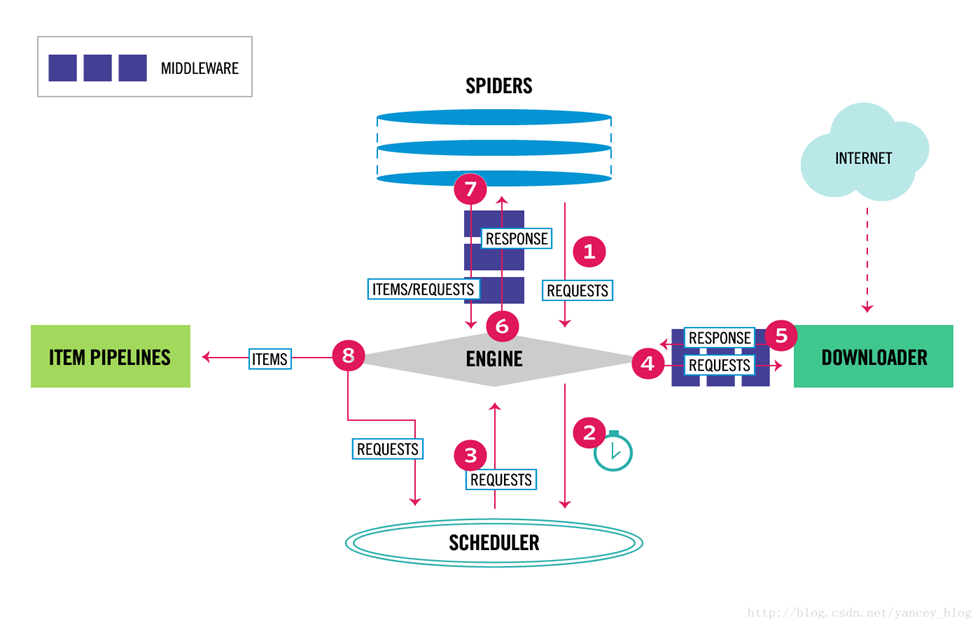
Scrapy的运行流程
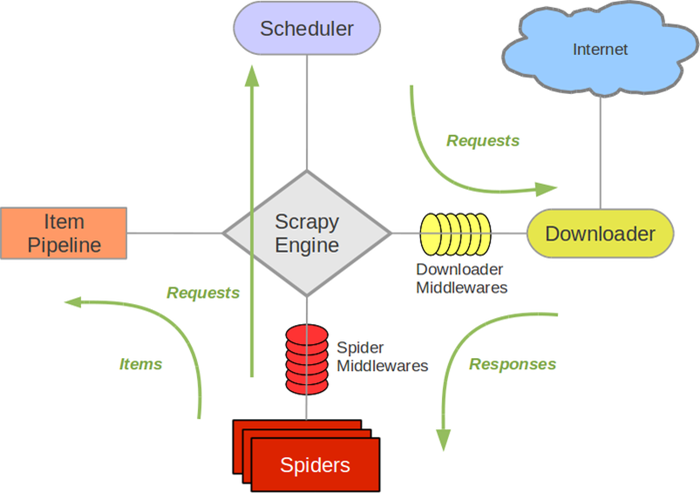
- Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Schedule中间件,信号,数据传递等
- Schedule(调度器):它负责接收引擎发送过来的Requests请求,并按照一定的方式进行排序,入队,当引擎需要时,交还给引擎
- Downloader(下载器):负责下载负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
- Spider(爬虫):他负责处理所有的Response,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Schedule来处理
- ItemPipeline(管道):它负责处理Spider中获取到的Item,并进行后期的处理(详细分析、过滤、存储等)的地方
- Downloader Middlewares(下载器中间件):可以当作是一个可以自定义下载功能的组件
- Spider Middlewares(Spider中间件):可以理解为是一个可以自定义扩展和操作引擎和Spider中间件通信的功能组件(比如进入Spider的Response;和从Spider出去的Requests)
Scrapy的使用
- 在虚拟机中用命令行输入
scrapy startproject project_name
- 根据提示,cd到创建的项目中,再创建根爬虫(spider_name是爬虫程序的文件名,spider_url是所要爬取的网站域名)
scrapy genspider spider_name spider_url(scrapy genspider spider tanzhouedu.com)
会相应生成如下文件
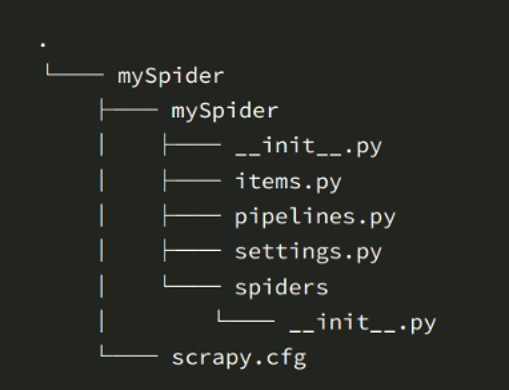
- scrapy.cfg:项目的配置文件
- mySpider/: 项目的Python模块,将会从这里引入代码
- mySpider/items.py :项目的目标文件
- mySpider/pipelines.py :项目的管道文件
- mySpider/settings.py :项目的设置文件
- mySpider/spiders/ :存储爬虫代码目录
Scrapy知识点介绍
- 制作爬虫(spiders/xxspider.py)
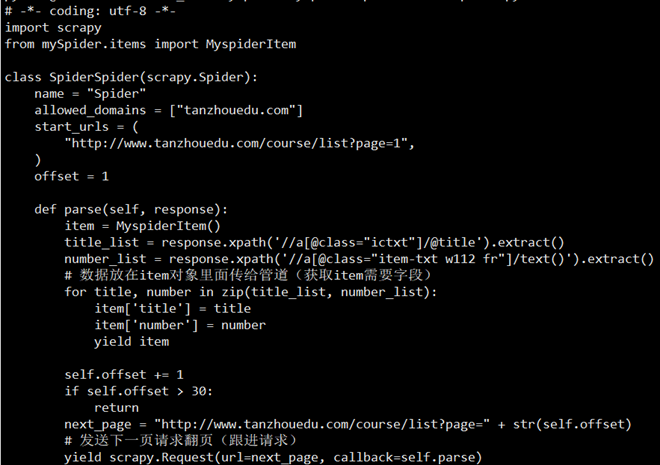
- 存储内容(pipelines.py):设计管道存储数据
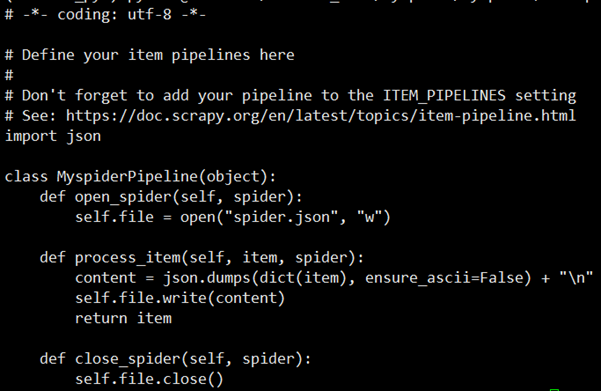
- mySpider/settings.py里面的注册管道

- 程序的运行:在虚拟机中相应文件夹下,输入scrapy list ,他会显示可以运行的scrapy程序,然后输入scrapy crawl scrapy_name开始运行
实战:伯乐在线案例(json文件保存)
创建项目
- bolezaixain\bolezaixain\items.py 设置需要的数据
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class BolezaixainItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
time = scrapy.Field()
- bolezaixain\bolezaixain\settings.py 激活管道

- bolezaixain\bolezaixain\spiders\blog_jobbole.py 编写爬虫代码
# -*- coding: utf-8 -*-
import scrapy
from ..items import BolezaixainItem #导入本文件夹外的items文件 class BlogJobboleSpider(scrapy.Spider):
name = 'blog.jobbole'
allowed_domains = ['blog.jobbole.com/all-posts/']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
title = response.xpath('//div[@class="post-meta"]/p/a[1]/@title').extract()
url = response.xpath('//div[@class="post-meta"]/p/a[1]/@href').extract()
times = response.xpath('//div[@class="post floated-thumb"]/div[@class="post-meta"]/p[1]/text()').extract()
time = [time.strip().replace('\r\n', '').replace('·', '') for time in times if '/' in time] for title, url, time in zip(title, url, time):
blzx_items = BolezaixainItem() # 实例化管道
blzx_items['title'] = title
blzx_items['url'] = url
blzx_items['time'] = time
yield blzx_items
# 翻页
next = response.xpath('//a[@class="next page-numbers"]/@href').extract_first()
# next = http://blog.jobbole.com/all-posts/page/2/
yield scrapy.Request(url=next, callback=self.parse) # 回调
- bolezaixain\bolezaixain\pipelines.py 保存数据
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymysql
import json class BolezaixainPipeline(object):
def __init__(self):
pass
print('======================')
self.f = open('blzx.json', 'w', encoding='utf-8') def open_spider(self, spider):
pass def process_item(self, item, spider):
s = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.f.write(s)
return item def close_spider(self, spider):
pass
self.f.close()
时间,url, 标题
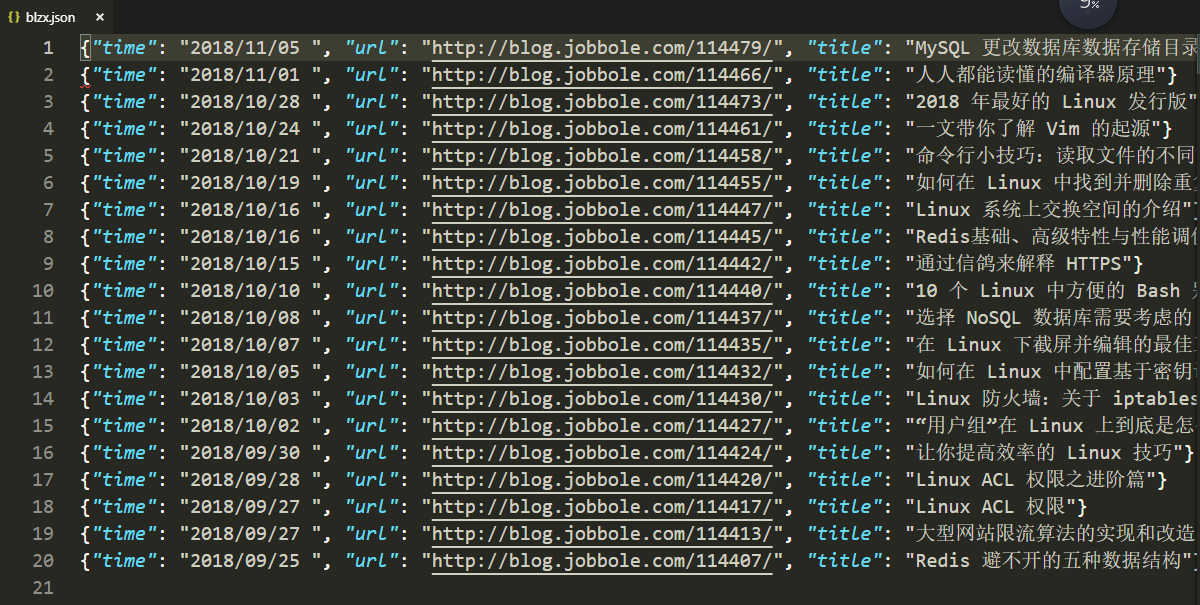
幸苦码字,转载请附链接
初识Scrapy——1—scrapy简单学习,伯乐在线实战、json数据保存的更多相关文章
- (1-1)入门—最简单的树(使用json数据)
1.<!DOCTYPE html>是必须的. 2.zTree 的容器 className 别忘了设置为 "ztree". 使用ztree创建树,首先要引用ztree相关 ...
- 吴裕雄--天生自然python学习笔记:Python3 JSON 数据解析
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. Python3 中可以使用 json 模块来对 JSON 数据进 ...
- PHP学习(五)----jQuery和JSON数据
对于jQuery: jQuery 是一个 JavaScript 库. jQuery 极大地简化了 JavaScript 编程.
- 2018百度之星开发者大赛-paddlepaddle学习(二)将数据保存为recordio文件并读取
paddlepaddle将数据保存为recordio文件并读取 因为有时候一次性将数据加载到内存中有可能太大,所以我们可以选择将数据转换成标准格式recordio文件并读取供我们的网络利用,接下来记录 ...
- Android学习笔记之JSON数据解析
转载:Android学习笔记44:JSON数据解析 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,为Web应用开发提供了一种 ...
- Android(java)学习笔记208:Android中操作JSON数据(Json和Jsonarray)
1.Json 和 Xml JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. JSON采用完全独立于语言的 ...
- Android(java)学习笔记151:Android中操作JSON数据(Json和Jsonarray)
1.Json 和 Xml JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. JSON采用完全独立于语言的 ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- Scrapy分布式爬虫打造搜索引擎- (二)伯乐在线爬取所有文章
二.伯乐在线爬取所有文章 1. 初始化文件目录 基础环境 python 3.6.5 JetBrains PyCharm 2018.1 mysql+navicat 为了便于日后的部署:我们开发使用了虚拟 ...
随机推荐
- Window attributes属性详解
以下属性以Dialog为例来讲解: <item name="windowBackground"> 窗体的背景 </item><item name=&q ...
- ASP.NET_SessionId vs .ASPXAUTH why do we need both of them?
https://stackoverflow.com/questions/23758704/asp-net-sessionid-vs-aspxauth-why-do-we-need-both-of-th ...
- how to use webpart container in kentico
https://docs.kentico.com/k11/developing-websites/developing-websites-using-the-portal-engine/using-w ...
- Mysql的简单使用(二)
接上文Mysql的简单使用(一) 字段参数以“(字段名1 数据类型1,字段名2 数据类型2,......)”的形式构建. 关于mysql常用的数据类型,一下是比较常用的几种,想查阅比较详细的资料可以自 ...
- AAC的AudioSpecificConfig细节
AAC格式里有个复杂的AudioSpecificConfig, 在FLV格式里称为AAC sequence header.在正式播放ADTS AAC数据包之前,需要用AudioSpecificConf ...
- PCB genesis大孔加小孔(即卸力孔)实现方法
一.为什么 大孔中要加小孔(即卸力孔) 这其实跟钻刀的排屑有关了,当钻刀越大孔,排屑量也越大(当然这也得跟转速,下刀速的参数有关系),通常当钻刀越大,转速越慢,下刀速也越慢(因为要保证它的排屑通畅). ...
- [Swift通天遁地]二、表格表单-(12)设置表单文字对齐方式以及自适应高度的文本区域TextArea
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...
- Akka源码分析-local-DeathWatch
生命周期监控,也就是死亡监控,是akka编程中常用的机制.比如我们有了某个actor的ActorRef之后,希望在该actor死亡之后收到响应的消息,此时我们就可以使用watch函数达到这一目的. c ...
- hdu2030
http://acm.hdu.edu.cn/showproblem.php?pid=2030 #include<stdio.h> #include<math.h> #inclu ...
- 关于学习C语言
c语言作为一种计算机的语言,我们学习它,有助于我们更好的了解计算机,与计算机进行交流,因此,c语言的学习对我们尤其重要. 在这个星期里,我们专业的学生在专业老师的带领下进行了c语言程序实践学习.在这之 ...