基于pytorch实现word2vec
一、介绍
- word2vec是Google于2013年推出的开源的获取词向量word2vec的工具包。它包括了一组用于word embedding的模型,这些模型通常都是用浅层(两层)神经网络训练词向量。
- Word2vec的模型以大规模语料库作为输入,然后生成一个向量空间(通常为几百维)。词典中的每个词都对应了向量空间中的一个独一的向量,而且语料库中拥有共同上下文的词映射到向量空间中的距离会更近。
- word2vec目前普遍使用的是Google2013年发布的C语言版本,现在也有Java、C++、python版本的实现,但是从效果和速度上还是C的更胜一筹,速度很快。
二、Word2Vec中的两种模型、两种加速方法
1、CBOW model 和 Skip-Gram model
- CBOW 是 Continuous Bag-of-Words Model 的缩写,CBOW是通过上下文预测中间词的模型
- Skip-Gram model与CBOW正好相反,是通过中间词来预测上下文,一般可以认为位置距离接近的词之间的联系要比位置距离较远的词的联系紧密。两种model如下图所示。

2、Hierarchical Softmax 和 Negative sampling
Negative sampling:负采样,目的是减少分母的规模,随机采样几个词,仅计算这几个词和预测词的分类问题,这样就将一个规模庞大的多元分类转换成了几个二分类问题。负采样用在Skip-Gram model上就是增加共线的词对出现的频率,而负采样不出现的额词随机抽样,降低他们的概率。
Hierarchical Softmax:层次化Softmax,将所有的词放在树的叶子节点上,构造Huffman树,使⽤哈夫曼编码,将计算复杂度较⾼的Softmax过程转化为多次⼆元分类任
务
。
三、Code 和 测试
1、Code
- 地址:https://github.com/bamtercelboo/pytorch_word2vec
- 目前的demo简单的实现了Skip-Gram + Hierarchical Softmax 、Skip-Gram + Negative sampling、CBOW + Hierarchical Softmax、CBOW + Negative sampling四种方法。
2、测试
- 测试是基于C版本的Word2vec跑出来的词向量与pytorch跑出来的词向量进行了简单的测试,当然两种都是在相同模型以及相同方法上的测试。
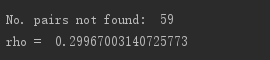
- 评分测试:C版本与pytorch版本的测试结果很接近(结果很低,是因为语料不是很大)
- 测试结果说明,pytortch跑出来的词向量效果和C版本跑出来的词向量版本效果是相近的,但是在速度方面C明显高于pytorch。

四、参考
- https://github.com/Adoni/word2vec_pytorch
- http://blog.csdn.net/itplus/article/details/37969519 (word2vec中的数学原理)
- https://en.wikipedia.org/wiki/Word2vec
基于pytorch实现word2vec的更多相关文章
- 基于pytorch实现HighWay Networks之Highway Networks详解
(一)简述---承接上文---基于pytorch实现HighWay Networks之Train Deep Networks 上文已经介绍过Highway Netwotrks提出的目的就是解决深层神经 ...
- 基于pytorch的电影推荐系统
本文介绍一个基于pytorch的电影推荐系统. 代码移植自https://github.com/chengstone/movie_recommender. 原作者用了tf1.0实现了这个基于movie ...
- 目标检测-基于Pytorch实现Yolov3(1)- 搭建模型
原文地址:https://www.cnblogs.com/jacklu/p/9853599.html 本人前段时间在T厂做了目标检测的项目,对一些目标检测框架也有了一定理解.其中Yolov3速度非常快 ...
- 基于Pytorch的简单小案例
神经网络的理论知识不是本文讨论的重点,假设读者们都是已经了解RNN的基本概念,并希望能用一些框架做一些简单的实现.这里推荐神经网络必读书目:邱锡鹏<神经网络与深度学习>.本文基于Pytor ...
- 实践torch.fx第一篇——基于Pytorch的模型优化量化神器
第一篇--什么是torch.fx 今天聊一下比较重要的torch.fx,也趁着这次机会把之前的torch.fx笔记整理下,笔记大概拆成三份,分别对应三篇: 什么是torch.fx 基于torch.fx ...
- 基于 PyTorch 和神经网络给 GirlFriend 制作漫画风头像
摘要:本文中我们介绍的 AnimeGAN 就是 GitHub 上一款爆火的二次元漫画风格迁移工具,可以实现快速的动画风格迁移. 本文分享自华为云社区<AnimeGANv2 照片动漫化:如何基于 ...
- 使用LabVIEW实现基于pytorch的DeepLabv3图像语义分割
前言 今天我们一起来看一下如何使用LabVIEW实现语义分割. 一.什么是语义分割 图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,例 ...
- 基于pytorch的CNN、LSTM神经网络模型调参小结
(Demo) 这是最近两个月来的一个小总结,实现的demo已经上传github,里面包含了CNN.LSTM.BiLSTM.GRU以及CNN与LSTM.BiLSTM的结合还有多层多通道CNN.LSTM. ...
- 艾伦AI研究院发布AllenNLP:基于PyTorch的NLP工具包
https://www.jiqizhixin.com/articles/2017-09-09-5 AllenNLP 可以让你轻松地设计和评估几乎所有 NLP 问题上最新的深度学习模型,并同基础设施一起 ...
随机推荐
- springboot 1.5.2 thymeleaf 添加templates 静态资源访问路径
从velocity 模板切换到thymeleaf 后, 默认模板位置为templates , 有时候静态资源方在该目录下会出现访问404错误 解决办法: application.properties ...
- Rxjava observeOn()和subscribeOn()初探
Rxjava这么强大的类库怎么可能没有多线程切换呢? 其中observeOn()与subscribeOn()就是实现这样的作用的.本文主要讲解observeOn()与subscribeOn()的用法, ...
- oracle创建用户四部曲
创建用户一般分四步: 第一步:创建临时表空间 第二步:创建数据表空间 第三步:创建用户并制定表空间 第四步:给用户授予权限 创建临时表空间 create temporary tablespace ho ...
- 网络编程应用:基于TCP协议【实现文件上传】--练习
要求: 基于TCP协议实现一个向服务器端上传文件的功能 客户端代码: package Homework2; import java.io.File; import java.io.FileInputS ...
- Nmap原理-01选项介绍
Nmap原理-01选项介绍 1.Nmap原理图 Nmap包含四项基本功能:主机发现/端口扫描/版本探测/操作系统探测.这四项功能之间存在大致的依赖关系,比如图片中的先后关系,除此之外,Nmap还提供规 ...
- 包装FTPWebRequest类
上篇文章讨论了C#从基于FTPS的FTP server下载数据 (FtpWebRequest 的使用)SSL 加密.不过细心的朋友应该可以发现FTPWebRequest 每次都是新生成一个reques ...
- python爬虫番外篇(一)进程,线程的初步了解
一.进程 程序并不能单独和运行只有将程序装载到内存中,系统为他分配资源才能运行,而这种执行的程序就称之为进程.程序和进程的区别在于:程序是指令的集合,它是进程的静态描述文本:进程是程序的一次执行活动, ...
- Chapter 1:Introduction
作者:桂. 时间:2017-05-24 08:06:45 主要是<Speech enhancement: theory and practice>的读书笔记,全部内容可以点击这里. 1. ...
- centOS下服务启动
nginx应该在mongodb之后启动,也可以通过chkconfig <服务名> on将服务设置为开机自启动.具体命令如下 service mysql start service memc ...
- 在Windows上远程运行Linux程序
1.在Windows主机上安装X Server软件,如Cygwin带的XWin Server 2.在Windows主机上启动X服务器,并将Linux主机设为允许访问该Windows主机上的X服务器. ...