如何开发自己的搜索帝国之Elasticsearch
搜索引擎是什么?
Elasticsearch是什么?
ES基础架构
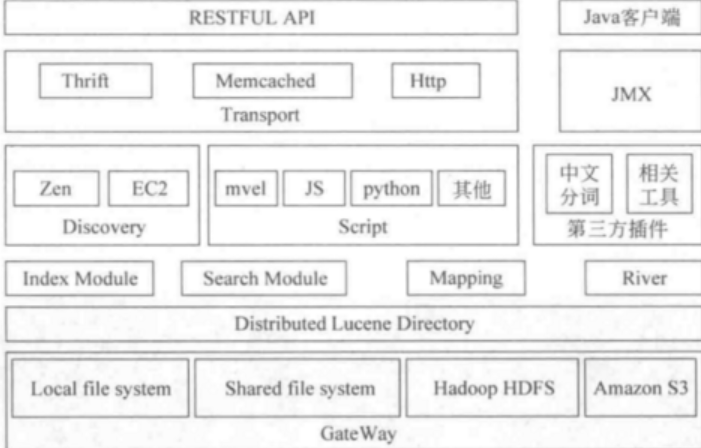
ElasticSearch vs Solr 总结
(1)二者安装都很简单。
(2)Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
(3)Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
(4)Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
(5)Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
(6)Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
三台机器做集群:192.168.80.30、192.168.80.32、192.168.80.33
环境
CentOS7.0
Java1.8
下载
下载地址:https://www.elastic.co/products/elasticsearch
下载后上传到CentOS中的/usr/local/ 文件夹中,并解压到当前文件中重命名为elasticsearch530 /usr/local/elasticsearch530
tar -zxvf elasticsearch-5.3.0.tar.gz
创建 elsearch运行账户和组
groupadd elsearch #添加elsearch组
useradd -g elsearch elsearch -s /bin/false
更改elasticsearch文件夹及内部文件的所属用户及组为elsearch:elsearch
chown -R elsearch:elsearch elasticsearch530
配置参数
cluster.name: es-application #这是集群名字,我们 起名为 es-application。es启动后会将具有相同集群名字的节点放到一个集群下。
node.name: "es-node1" #节点名字。
covery.zen.minimum_master_nodes: 1 #指定集群中的节点中有几个有master资格的节点。对于大集群可以写3个以上。
discovery.zen.ping.timeout: 40s #默认是3s,这是设置集群中自动发现其它节点时ping连接超时时间,为避免因为网络差而导致启动报错,我设成了40s。
discovery.zen.ping.multicast.enabled: false #设置是否打开多播发现节点,默认是true。
network.host: 0.0.0.0
http.port: 9200
node.master: true #节点从可作为选举为主节点
node.data: true #也用来存储数据,可作为负载器
discovery.zen.ping.unicast.hosts: ["192.168.80.32","192.168.80.33","192.168.80.30"] #discovery.zen.ping.unicast.hosts:["节点1的 ip","节点2 的ip","节点3的ip"] 指明集群中其它可能为master的节点ip,以防es启动后发现不了集群中的其他节点。第一对引号里是node1,默认端口是9300。第二个是 node2 ,在另外一台机器上。
node.name: "es-node2"和 node.name: "es-node3"
启动
su elsearch
cd /usr/local/elasticsearch530 目录
bin/elasticsearch -d #后台运行
此时启动服务会发现报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[root@H32 ~]# cat /etc/sysctl.conf | grep -v "vm.max_map_count" > /tmp/system_sysctl.conf
[root@H32 ~]# echo "vm.max_map_count=262144" >> /tmp/system_sysctl.conf
[root@H32 ~]# mv /tmp/system_sysctl.conf /etc/sysctl.conf
mv:是否覆盖"/etc/sysctl.conf"? y
[root@H32 ~]# cat /etc/sysctl.conf
# System default settings live in /usr/lib/sysctl.d/00-system.conf.
# To override those settings, enter new settings here, or in an /etc/sysctl.d/<name>.conf file
#
# For more information, see sysctl.conf(5) and sysctl.d(5).
vm.max_map_count=262144
[root@H32 ~]# sysctl -p
vm.max_map_count = 262144
修改后再次启动,可通过下命令查看启动后是否有进程
ps -ef |grep elasticsearch
ES的安装就此完成,接下来安装Head插件来监控Elasticsearch
Elasticsearch Head插件
设置内核参数
fs.file-max=65536
vm.max_map_count=262144
设置资源参数
elsearch soft nofile 65536
elsearch hard nofile 65536 sysctl -p
# 增加新的参数,这样head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
在5.X版本中不支持直接安装head插件,需要启动一个服务
git clone git://github.com/mobz/elasticsearch-head.git
下载 elasticsearch-head 或者 git clone 到 /usr/local/elasticsearch-head
cd elasticsearch-head npm install
yum -y install xz
xz -d node*.tar.xz tar -xvf node*.tar
解压完node的安装文件后,需要配置下环境变量,编辑/etc/profile,添加
# set node environment
export NODE_HOME=/usr/local/node790
export PATH=$PATH:$NODE_HOME/bin
别忘记立即执行以下
[root@H32 node790]# echo $NODE_HOME
/usr/local/node790
[root@H32 node790]# node -v
[root@H32 node790]# npm -v
安装grunt
cd elasticsearch-head
npm install grunt-cli
npm install grunt --save-dev
[root@H32 elasticsearch-head]# grunt -version
grunt-cli v1.2.0
grunt v1.0.1
启动服务
/usr/local/elasticsearch-head/node_modules/grunt/bin/gruntserver
修改head源码
connect: { server: { options: { port: 9100, hostname: '*', base: '.', keepalive: true } } }
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.80.32:9200";
运行head
cd /usr/local/elasticsearch-head
grunt server -d

现在可以在此页面操作ES数据了,但这只是一个开始。
如何开发自己的搜索帝国之Elasticsearch的更多相关文章
- 如何开发自己的搜索帝国之ES图形化Kibana安装与使用
在如何开发自己的搜索帝国之Elasticsearch中已经介绍安装好了ES,下面就Kibana对ES的查询监控作介绍,就是常提到的大数据日志处理组件ELK里的K. 什么是Kibana?现引用园友的一段 ...
- 如何开发自己的搜索帝国之安装ik分词器
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词,我是中国人 不能简单的分成一个个字,我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要 ...
- FlexPaper二次开发问题及搜索高亮显示
原文:FlexPaper二次开发问题及搜索高亮显示 最近有个需求,做一个IT知识库,类似于文库,说到文库肯定会用到在线浏览文档了,所有在网上翻阅了一下类似豆丁的在线浏览器插件的资料,将其进行了二次开发 ...
- OpenERP(odoo)开发实例之搜索检索过去3个月的数据
转自:http://www.chinamaker.net/ OpenERP(odoo)开发实例之搜索过滤:检索过去3个月的数据 解决这个问题的重点在于 relativedelta 的应用 示例代码如下 ...
- 搜索浅谈(Elasticsearch和Lucene4分享)
刚刚过去的双11,真是给线下运营商好好上了一课.当今的互联网真是炙手可热,大家对互联网的热情是如此之高.相信电商之间的竞争将更加的激烈和残酷,不过,搜索,作为用户体验很重要的一点,各大电商也做的越来越 ...
- (转)开源分布式搜索平台ELK(Elasticsearch+Logstash+Kibana)入门学习资源索引
Github, Soundcloud, FogCreek, Stackoverflow, Foursquare,等公司通过elasticsearch提供搜索或大规模日志分析可视化等服务.博主近4个月搜 ...
- Elasticsearch搜索异常-------org.elasticsearch.common.io.stream.NotSerializableExceptionWrapper: parse_exception
异常问题: Caused by: org.elasticsearch.index.query.QueryShardException: Failed to parse query [LOL: Uzi和 ...
- 开源分布式搜索平台ELK(Elasticsearch+Logstash+Kibana)入门学习资源索引
from: http://www.w3c.com.cn/%E5%BC%80%E6%BA%90%E5%88%86%E5%B8%83%E5%BC%8F%E6%90%9C%E7%B4%A2%E5%B9%B ...
- 可以执行全文搜索的原因 Elasticsearch full-text search Kibana RESTful API with JSON over HTTP elasticsearch_action es 模糊查询
https://www.elastic.co/guide/en/elasticsearch/guide/current/getting-started.html Elasticsearch is a ...
随机推荐
- 查看java线程cpu占用情况的脚本
#!/bin/bash [ $# -ne ] && exit jstack $ >/tmp/jstack.log -o THREAD,tid,time|sort -k2nr| s ...
- Reflect(反射)
反射.反射,程序员的快乐.反射是无处不在的. 那么什么是反射:通过反射,可以在运行时获得程序或程序集中每一个类型(包括类.结构.委托.接口和枚举等)的成员和成员的信息.有了反射,即可对每一个类型了如指 ...
- H5学习第二周
怎么说,在各种感觉中h5学习的第二周已经过来了,先总结一下,感觉学习h5是一件让我爱恨交加的事,学会一些新的知识并把它成功运行出来的时候是非常激动和兴奋的,但是有时候搞不懂一个标签或者属性的时候,就有 ...
- docker中执行sed: can't move '/etc/resolv.conf73UqmG' to '/etc/resolv.conf': Device or resource busy错误的处理原因及方式
错误现象 在docker容器中想要修改/etc/resolv.conf中的namesever,使用sed命令进行执行时遇到错误: / # sed -i 's/192.168.1.1/192.168.1 ...
- 无法将类型为excel.applicationclass的com 强制转换为接口类型的解决方法[转]
c#解决方案EXCEL 导出 今天碰到客户的电脑在导出EXCEL的时候提示,无法将类型为 excel.applicationclass 的 com 强制转换为接口类型 excel._applicati ...
- accp8.0转换教材第9章JQuery相关知识理解与练习
自定义动画 一.单词部分: ①animate动画②remove移除③validity有效性 ④required匹配⑤pattern模式 二.预习部分 1.简述JavaScript事件和jquery事件 ...
- linux命令行解刨
linux命令需要在命令行界面上操作(windows的cmd也是一个命令行界面).只有在了解命令行界面含义才能知道我们输入这些命令意义是什么,为什么要输入这些命令. 首先我们要知道怎么找出linux输 ...
- usaco training 4.1.3 fence6 题解
Fence Loops题解 The fences that surround Farmer Brown's collection of pastures have gotten out of cont ...
- Tkinter开发第一个桌面程序HelloWorld
在Python3中是tkinter,Python2中是Tkinter Tkinter是Python 官方承认的标准 GUI 方案(de-facto standard),因为是Python自带安装,决定 ...
- requireJS 源码(三) data-main 的加载实现
(一)入口 通过 data-main 去加载 JS 模块,是通过 req(cfg) 入口去进行处理的. 为了跟踪,你可以在此 加断点 进行调试跟踪. (二) req({ })执行时,functio ...