NLTK学习笔记(八):文法--词关系研究的工具
对于一门语言来说,一句话有无限可能。问题是我们只能通过有限的程序来分析结构和含义。尝试将“语言”理解为:仅仅是所有合乎文法的句子的大集合。在这个思路的基础上,类似于 word -> word and/or/... word 就成立,这种式子叫做递归产生式。理论上,句子可以无限扩充。
文法
自定义文法
写法上与上一篇博文的分类规则思路基本一致,并且更简单、更直观,可以和之前的对比着看。
import nltk
from nltk import CFG
grammar = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" | "Bob" | Det N | Det N PP
Det -> "a" | "an" | "the" | "my"
N -> "man" | "dog" | "cat" | "telescope" | "park"
P -> "in" | "on" | "by" | "with"
""")
sent = 'Mary saw Bob'.split()
rd_parser = nltk.RecursiveDescentParser(grammar)
for i in rd_parser.parse(sent):
print(i)
在定义文法的时候,NP->'New York'应该写成 NP->'New_York',连接作用的空格应该用_代替。
文法用途
语言基本可以说是由修饰结构和并列结构拼接而成(不喜勿喷)。比如下面这样不断的扩充:
- he ran
- he ran there
- he saw it there
- the bear saw the font in it
显然正常的句子是第四句,如果将上述过程倒过来从4->1。最终就可以得到两个元素。也就是说:再复合语法规则句子中的词序列可以被一个更小的且不会导致句子不符合语法规则的序列代替。下面两张图,第一张代表词序列的替换。第二张是根据文法规则画出的图。(附截图*2)


开发文法
下面程序展示了利用简单的过滤器,找出带句子补语的动词
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
print(t) #查看封装好的文法
def filter(tree):
child_nodes = [child.label() for child in tree if isinstance(child,nltk.Tree)]
return (tree.label() == 'VP') and ('S' in child_nodes)#找出带句子补语的动词
[subtree for tree in treebank.parsed_sents() \
for subtree in tree.subtrees(filter)]
分析文法的算法
- 下降递归分析:自上而下
- 移进-归约分析:自下而上
- 左角落分析:自下而上过滤的自上而下的方法
- 图表法:动态规划技术
以下是前两种分析算法对应的解析器。
递归下降解析器
三个主要缺点:
- 左递归产生式:
NP-> NP PP会陷入死循环 - 处理不符合句子的词和结构时候浪费时间
- 回溯过程过重会丢掉计算过的分析,重新计算
import nltk
from nltk import CFG
grammar1 = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" | "Bob" | Det N | Det N PP
Det -> "a" | "an" | "the" | "my"
N -> "man" | "dog" | "cat" | "telescope" | "park"
P -> "in" | "on" | "by" | "with"
""")
rd_parser = nltk.RecursiveDescentParser(grammar1)
sent = 'Mary saw a dog'.split()
for t in rd_parser.parse(sent):
print(t)
可以调用nltk.app.rdparser()来查看分析过程
移进-归约解析器
此解析器反复将下个输入词push进堆栈,成为移位操作。如果堆栈前n项,匹配表达式右侧的n个项目,弹出栈,并且将产生式左边项目压如栈,称为归约操作。
两个缺点:
- 由于堆栈的特殊性,只能找到一种解析
- 不能保证一定能找到解析
sr_parse = nltk.ShiftReduceParser(grammar1)
for t in sr_parse.parse(sent):
print(t)
基于特征的文法
怎么对文法进行更细微的控制,用什么结构来表示?可以将标签分解为类似字典的结构,提取一系列的值作为特征。
属性和约束
首先看一个例子,通过nltk.data.show_cfg('grammars/book_grammars/feat0.fcfg') :
% start S
# ###################
# Grammar Productions
# ###################
# S expansion productions
S -> NP[NUM=?n] VP[NUM=?n]
# NP expansion productions
NP[NUM=?n] -> N[NUM=?n]
NP[NUM=?n] -> PropN[NUM=?n]
NP[NUM=?n] -> Det[NUM=?n] N[NUM=?n]
NP[NUM=pl] -> N[NUM=pl]
# VP expansion productions
VP[TENSE=?t, NUM=?n] -> IV[TENSE=?t, NUM=?n]
VP[TENSE=?t, NUM=?n] -> TV[TENSE=?t, NUM=?n] NP
# ###################
# Lexical Productions
# ###################
Det[NUM=sg] -> 'this' | 'every'
Det[NUM=pl] -> 'these' | 'all'
Det -> 'the' | 'some' | 'several'
PropN[NUM=sg]-> 'Kim' | 'Jody'
N[NUM=sg] -> 'dog' | 'girl' | 'car' | 'child'
N[NUM=pl] -> 'dogs' | 'girls' | 'cars' | 'children'
IV[TENSE=pres, NUM=sg] -> 'disappears' | 'walks'
TV[TENSE=pres, NUM=sg] -> 'sees' | 'likes'
IV[TENSE=pres, NUM=pl] -> 'disappear' | 'walk'
TV[TENSE=pres, NUM=pl] -> 'see' | 'like'
IV[TENSE=past] -> 'disappeared' | 'walked'
TV[TENSE=past] -> 'saw' | 'liked'
类似于字典的规则,NUM,TENSE等就是属性,press,sg,pl就是约束。这样我们就能显示指明'the some dogs'这样的句子,而不是'the some dog'。
其中,sg代表单数,pl代表复数,?n代表不确定(皆可)。类似sg,pl这样的特征值称为原子,原子也可以是bool值,并且用+aux 和 -aux分别表示True 和 False。
处理特征结构
NLTK的特征结构使用构造函数FeatStuct()来进行声明,原子特征值可以是字符串或者整数。简单示例:
fs1 = nltk.FeatStruct("[TENSE = 'past',NUM = 'sg',AGR=[NUM='pl',GND = 'fem']]")
print(fs1)
print(fs1['NUM'])#可以像字典那样进行访问
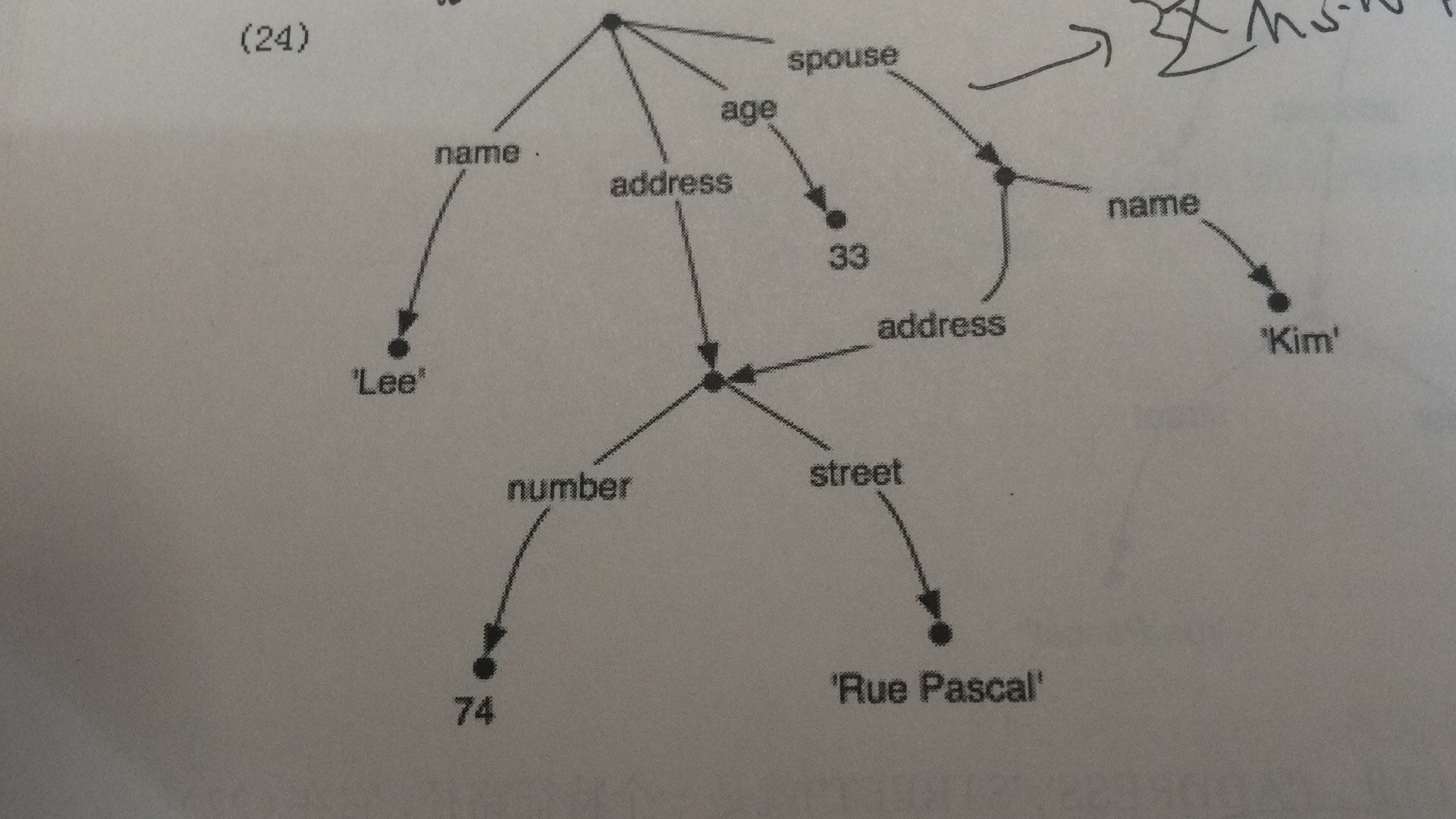
打印出来发现是矩阵形式。为了在矩阵中表示重入,可以在共享特征结构的地方加一个括号包围的数字前缀,例如(1)。以后对任意这个结构的引用都使用(1)
print(nltk.FeatStruct("""[NAME = 'Lee',ADDRESS=(1)[NUMBER=74,STREET='rue Pascal'],SPOUSE =[NAME='Kim',ADDRESS->(1)]]"""))
结果如下:
[ ADDRESS = (1) [ NUMBER = 74 ] ]
[ [ STREET = 'rue Pascal' ] ]
[ ]
[ NAME = 'Lee' ]
[ ]
[ SPOUSE = [ ADDRESS -> (1) ] ]
[ [ NAME = 'Kim' ] ]
结果可以看成一个图结构,如果没有这种(num),就是有向无环图;有的话,就有环了。(附截图)
包含和统一
如果有两种结构:
a.[num = 74]
b.[num = 74]
[street = 'BeiJing']
那么b包含a。类似于集合运算,这个顺序称为包含。
统一就是合并两个结构,但是如果相同的属性有不同的值,那么会返回None类型。
fs1 = nltk.FeatStruct(NUMBER = 74)
fs2 = nltk.FeatStruct(City = 'BeiJint')
#fs2 = nltk.FeatStruct(NUMBER= 45)#返回None
print(fs2.unify(fs1))
总结
在NLP中中,简单的说:文法=语法=词法+句法。
它是语言学的一个分支,研究按确定用法来运用的"词类"、"词"的曲折变化或表示相互关系的其他手段以及词在句中的功能和关系。包含词的构词、构形的规则和组词成句的规则。
由于,不同的文法框架在写法上也有差异,所以在构造的时候需要具体查看相关文档和库的要求。这方面的编程,更多的是在规则的基础上对词和词类的关系进行研究,并且不断完善文法规则。
欢迎进一步交流本博文相关内容:
博客园地址 : http://www.cnblogs.com/AsuraDong/
CSDN地址 : http://blog.csdn.net/asuradong
也可以致信进行交流 : xiaochiyijiu@163.com
欢迎转载 , 但请指明出处 : )
NLTK学习笔记(八):文法--词关系研究的工具的更多相关文章
- go微服务框架kratos学习笔记八 (kratos的依赖注入)
目录 go微服务框架kratos学习笔记八(kratos的依赖注入) 什么是依赖注入 google wire kratos中的wire Providers injector(注入器) Binding ...
- Learning ROS forRobotics Programming Second Edition学习笔记(八)indigo rviz gazebo
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS forRobotics Pro ...
- python3.4学习笔记(八) Python第三方库安装与使用,包管理工具解惑
python3.4学习笔记(八) Python第三方库安装与使用,包管理工具解惑 许多人在安装Python第三方库的时候, 经常会为一个问题困扰:到底应该下载什么格式的文件?当我们点开下载页时, 一般 ...
- Go语言学习笔记八: 数组
Go语言学习笔记八: 数组 数组地球人都知道.所以只说说Go语言的特殊(奇葩)写法. 我一直在想一个人参与了两种语言的设计,但是最后两种语言的语法差异这么大.这是自己否定自己么,为什么不与之前统一一下 ...
- 【opencv学习笔记八】创建TrackBar轨迹条
createTrackbar这个函数我们以后会经常用到,它创建一个可以调整数值的轨迹条,并将轨迹条附加到指定的窗口上,使用起来很方便.首先大家要记住,它往往会和一个回调函数配合起来使用.先看下他的函数 ...
- Redis学习笔记八:集群模式
作者:Grey 原文地址:Redis学习笔记八:集群模式 前面提到的Redis学习笔记七:主从复制和哨兵只能解决Redis的单点压力大和单点故障问题,接下来要讲的Redis Cluster模式,主要是 ...
- Java IO学习笔记八:Netty入门
作者:Grey 原文地址:Java IO学习笔记八:Netty入门 多路复用多线程方式还是有点麻烦,Netty帮我们做了封装,大大简化了编码的复杂度,接下来熟悉一下netty的基本使用. Netty+ ...
- ROS学习笔记八:基于Qt搭建ROS开发环境
1 前言 本文介绍一种Qt下进行ROS开发的完美方案,使用的是ros-industrial的Levi-Armstrong在2015年12月开发的一个Qt插件ros_qtc_plugin,这个插件使得Q ...
- vue学习笔记(八)组件校验&通信
前言 在上一章博客的内容中vue学习笔记(七)组件我们初步的认识了组件,并学会了如何定义局部组件和全局组件,上一篇内容仅仅只是对组件一个简单的入门,并没有深入的了解组件当中的其它机制,本篇博客将会带大 ...
随机推荐
- 十分钟彻底理解javascript 的 this指向,不懂请砸店
函数的this指向谁,和函数在哪里被定义的,函数在哪里被执行的没有半毛钱关系,只遵守下面的规律: 在非严格模式中: 1.自执行函数里面,this永远指向window; <script> v ...
- 576. Out of Boundary Paths
Problem statement: There is an m by n grid with a ball. Given the start coordinate (i,j) of the ball ...
- eclipse中集成hadoop插件
1.下载并安装eclipse2.https://github.com/winghc/hadoop2x-eclipse-plugin3.下载插件到eclipse的插件目录 4.配置hadoop安装目录 ...
- Maven学习-简介、安装
Maven是一个项目管理工具,它包含了一个项目对象模型,一组标准集合,一个项目声明周期,一个依赖管理系统和用来运行定义在生命周期阶段中插件目标的逻辑.Maven采用了约定优于配置这一基本原则.在没有自 ...
- 搭建struct环境
昨天学习了struts,发现struts并不是struts2同一框架的升级,完全是属于两个框架.struts2是在freework的基础上进行封装的. 1.struts的环境搭载 (1)创建web ...
- Linux环境g++编译GDAL动态库
一.编译步骤 解压下载的GDAL源程序,并在命令行中切换到解压目录. tar -xzvf gdal-2.1.3.tar.gz cd gdal-2.1.3 GDAL可通过configure来实现一些自定 ...
- Error:Android Source Generator: [sdk] Android SDK is not specified.
有时候使用intellij idea 带入android 项目,运行提示Error:Android Source Generator: [sdk] Android SDK is not specifi ...
- Github 开源:升讯威 Winform 开源控件库( Sheng.Winform.Controls)
Github 地址:https://github.com/iccb1013/Sheng.Winform.Controls 本控件库中的代码大约写于10年前(2007年左右),难免有不成熟与欠考虑之处, ...
- JavaScript Style Guide中文总结
github原址:https://github.com/airbnb/javascript 类型*基本类型:包括string.number.boolean.null.undefined,存储的是值本身 ...
- 浅谈MVC数据验证
一.一般情况 对于使用过MVC框架的人来说,对MVC的数据验证不会陌生,比如,我有一个Model如下: public class UserInfo { [Required(ErrorMessage = ...