Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优
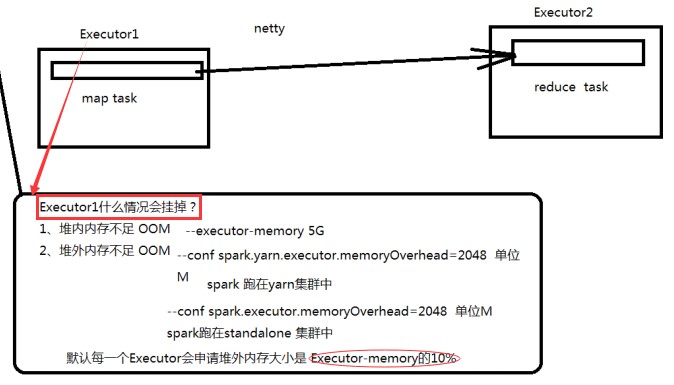
Spark性能调优之Shuffle调优的更多相关文章
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark性能优化:开发调优篇
1.前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算 ...
- spark调优——Shuffle调优
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节m ...
- Spark性能调优-高级篇
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
随机推荐
- 01.阿里云SDK调用,获取ESC主机详细信息
一:通过python SDK获取云主机的详细信息 1.创建Accessky码(不做展示) 2.通过pip安装SDK模块,这个阿里云帮助里面有,也不做详细展示. 3.详细使用方法看代码 我下面展示的返回 ...
- SpringBoot初步
1.创建maven 项目 quickstart类型 2.pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" ...
- MyBatis map foreach
以下资料来源于网络,仅供参考学习. mybatis 遍历map实例 map 数据如下 Map<String,List<Long>>. 测试代码如下: public vo ...
- 细说MyEclipse调试
在程序出现问题时,我们需要找到并解决掉这些恼人的Bug,才能使程序顺利的运行下去.但是,当代码很多,程序很大的时候,找起来就很麻烦. 所以,我们需要借助工具——Eclipse/MyEclipse中的 ...
- Python并发实践_01_线程与进程初探
进程与线程 在多任务处理中,每一个任务都有自己的进程,一个任务会有很多子任务,这些在进程中开启线程来执行这些子任务.一般来说,可以将独立调度.分配的基本单元作为线程运行,而进程是资源拥有的基本单位. ...
- 《Python cookbook》 “定义一个属性可由用户修改的装饰器” 笔记
看<Python cookbook>的时候,第9.5部分,"定义一个属性可由用户修改的装饰器",有个装饰器理解起来花了一些时间,做个笔记免得二刷这本书的时候忘了 完整代 ...
- 基于ASP.NET WEB API实现分布式数据访问中间层(提供对数据库的CRUD)
一些小的C/S项目(winform.WPF等),因需要访问操作数据库,但又不能把DB连接配置在客户端上,原因有很多,可能是DB连接无法直接访问,或客户端不想安装各种DB访问组件,或DB连接不想暴露在客 ...
- Nginx集群之.Net打造WebApp(支持IOS和安卓)
目录 1 大概思路... 1 2 Nginx集群之.Net打造WebApp(支持IOS和安卓) 1 3 安卓模拟器... 1 4 MUI框架... 3 ...
- 简易排水简车的制作 TurnipBit 系列教程
准备工作 ü TurnipBit 开发板 1块 ü 下载数据线 1条 ü 微型步进电机(28BYJ-48) 1个 ü 步进电机驱动板(ULN2003APG) 1块 ü TurnipBit 扩展板 ...
- Mongodb集群【三】
Mongodb常用三种集群 1 主从(Master/Slave) 不推荐,但是mongodb依然保留有.一主多从,不支持链式结构.简单主从,没有裁仲者不能自动恢复. 2 副本集(Relica Set) ...