Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优
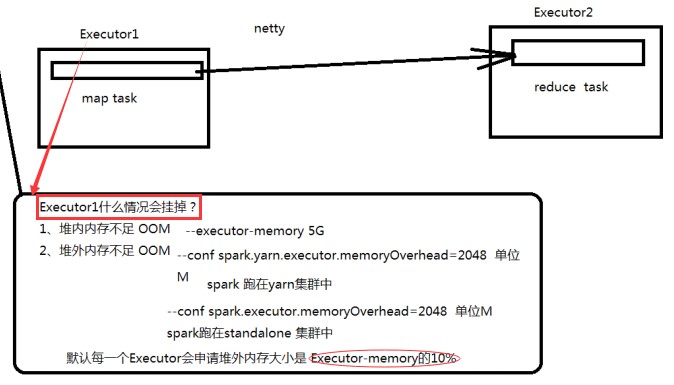
Spark性能调优之Shuffle调优的更多相关文章
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark性能优化:开发调优篇
1.前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算 ...
- spark调优——Shuffle调优
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节m ...
- Spark性能调优-高级篇
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
随机推荐
- DataInputStream EOFEXCEPTION
在编写socket通信时,服务端使用了DataInputStream.readUTF()读取字节流时,出现EOFEXCEPTION 原因是客户端没有使用DataOutputStream.writeUT ...
- WebSocket协议:5分钟从入门到精通
一.内容概览 WebSocket的出现,使得浏览器具备了实时双向通信的能力.本文由浅入深,介绍了WebSocket如何建立连接.交换数据的细节,以及数据帧的格式.此外,还简要介绍了针对WebSocke ...
- 消息队列一:为什么需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- Chrome 里的请求报错 "CAUTION: Provisional headers are shown" 是什么意思?
在调试器中看到文件显示提示为 CAUTION: Provisional headers are shown, 可是直接复制链接访问资源却可以正常访问, 最后发现是https 问题,资源采用ssl协议, ...
- Java容器---Map基础
1.Map API (1)Map 集合类用于存储元素对(称作"键"和"值"),其中每个键映射到一个值. java.util Interface Map<K ...
- python的sorted函数
sorted很简单,没太多好写的 ,只是给自己做个笔记. sorted接受三个参数,返回一个排序之后的list. 第一个接受一个可迭代的对象(因为sorted实现了迭代协议,所以接受的参数不一定需要l ...
- amaze UI 笔记 - CSS
导航添加依据 http://amazeui.org/css/ 下面内容属学习笔记,如有理解偏差和错误请留言相告,感谢!* =(官网这块写的很详细) 一.基本样式 1.统一样式 说明了为什么使用Nor ...
- 【Java框架型项目从入门到装逼】第五节 - 在Servlet中接收和返回数据
在上一节的程序中,我们可以看到HttpServletRequest, HttpServletResponse这两个对象.可以说,这是JavaWeb中至关重要的两个对象.接下来,我们来做一个简短的说明: ...
- Standard PHP Library(SPL)中的数据结构
SPL提供了一组标准数据结构. SplDoublyLinkedList Class:双向链表(DLL)是在两个方向上相互链接的节点列表.当底层结构是dll时,迭代器的操作.对两端的访问.节点的添加或删 ...
- 设计模式(三)装饰者模式Decorator
装饰者模式针对的问题是:对一个结构已经确定的类,在不改变该类的结构的情况下,动态增加一些功能. 一般来说,都是对一些已经写好的架构增加自己的功能,或者应对多种情况,增加功能. 我们还是来玩一句红警,首 ...