MLlib--GBDT算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/8b9cb1875288d9f6cfc2f5a9b2f10eac.html
GBDT算法

1.决策树
1.1决策树的分类
| 决策树 | 分类决策树 | 用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。 |
| 回归决策树 | 预测实数值,如明天的温度、用户的年龄、网页的相关程度 |
| 强调:回归决策树的结果(数值)加减是有意义的,但是分类决策树是没有意义的,因为它是类别 |
1.2什么是回归决策树?
1.3回归决策树划分的原则_CART算法
2.GBDT算法_Boosting迭代
2.2图解Boosting迭代
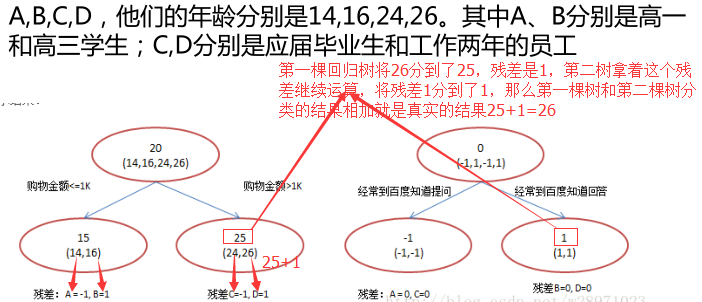
2.3GBDT算法_构建决策树的步骤
2.4GBDT和其他的比较
2.4.1GBDT和随机森林的比较
2.4.2GBDT和SVM
2.4.3如何用回归决策树来进行分类?
2.4.4数据处理--归一化
2.5回归决策树code
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.feature.{StandardScaler, StandardScalerModel}
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.tree.{GradientBoostedTrees, DecisionTree}
import org.apache.spark.mllib.tree.configuration.{BoostingStrategy, Algo}
import org.apache.spark.mllib.tree.impurity.Entropy
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hzf
*/
object GBDT_new {
// E:\IDEA_Projects\mlib\data\GBDT\train E:\IDEA_Projects\mlib\data\GBDT\train\model 10 local
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
if (args.length < 4) {
System.err.println("Usage: DecisionTrees <inputPath> <modelPath> <maxDepth> <master> [<AppName>]")
System.err.println("eg: hdfs://192.168.57.104:8020/user/000000_0 10 0.1 spark://192.168.57.104:7077 DecisionTrees")
System.exit(1)
}
val appName = if (args.length > 4) args(4) else "DecisionTrees"
val conf = new SparkConf().setAppName(appName).setMaster(args(3))
val sc = new SparkContext(conf)
val traindata: RDD[LabeledPoint] = MLUtils.loadLabeledPoints(sc, args(0))
val features = traindata.map(_.features)
val scaler: StandardScalerModel = new StandardScaler(withMean = true, withStd = true).fit(features)
val train: RDD[LabeledPoint] = traindata.map(sample => {
val label = sample.label
val feature = scaler.transform(sample.features)
new LabeledPoint(label, feature)
})
val splitRdd: Array[RDD[LabeledPoint]] = traindata.randomSplit(Array(1.0, 9.0))
val testData: RDD[LabeledPoint] = splitRdd(0)
val realTrainData: RDD[LabeledPoint] = splitRdd(1)
val boostingStrategy: BoostingStrategy = BoostingStrategy.defaultParams("Classification")
boostingStrategy.setNumIterations(3)
boostingStrategy.treeStrategy.setNumClasses(2)
boostingStrategy.treeStrategy.setMaxDepth(args(2).toInt)
boostingStrategy.setLearningRate(0.8)
// boostingStrategy.treeStrategy.setCategoricalFeaturesInfo(Map[Int, Int]())
val model = GradientBoostedTrees.train(realTrainData, boostingStrategy)
val labelAndPreds = testData.map(point => {
val prediction = model.predict(point.features)
(point.label, prediction)
})
val acc = labelAndPreds.filter(r => r._1 == r._2).count.toDouble / testData.count()
println("Test Error = " + acc)
model.save(sc, args(1))
}
}
E:\IDEA_Projects\mlib\data\GBDT\train E:\IDEA_Projects\mlib\data\GBDT\train\model 10 local

MLlib--GBDT算法的更多相关文章
- GBDT算法原理深入解析
GBDT算法原理深入解析 标签: 机器学习 集成学习 GBM GBDT XGBoost 梯度提升(Gradient boosting)是一种用于回归.分类和排序任务的机器学习技术,属于Boosting ...
- 机器学习系列------1. GBDT算法的原理
GBDT算法是一种监督学习算法.监督学习算法需要解决如下两个问题: 1.损失函数尽可能的小,这样使得目标函数能够尽可能的符合样本 2.正则化函数对训练结果进行惩罚,避免过拟合,这样在预测的时候才能够准 ...
- 机器学习技法-GBDT算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 之前看过别人的竞赛视频,知道GBDT这个算法应用十分广泛.林在第八讲,简单的介绍了AdaBoo ...
- 工业级GBDT算法︱微软开源 的LightGBM(R包正在开发....)
看完一篇介绍文章后,第一个直觉就是这算法已经配得上工业级属性.日前看到微软已经公开了这一算法,而且已经发开python版本,本人觉得等hadoop+Spark这些平台配齐之后,就可以大规模宣传啦~如果 ...
- GBDT 算法:原理篇
本文由云+社区发表 GBDT 是常用的机器学习算法之一,因其出色的特征自动组合能力和高效的运算大受欢迎. 这里简单介绍一下 GBDT 算法的原理,后续再写一个实战篇. 1.决策树的分类 决策树分为两大 ...
- GBDT算法
GBDT通过多轮迭代,每轮迭代产生一个弱分类器,其中弱分类器通常选择为CART树,每个分类器在上一轮分类器的残差基础上进行训练. 对于GBDT算法,其中重要的知识点为: 1.GBDT是梯度下降法从参数 ...
- 转载:GBDT算法梳理
学习内容: 前向分布算法 负梯度拟合 损失函数 回归 二分类,多分类 正则化 优缺点 sklearn参数 应用场景 转自:https://zhuanlan.zhihu.com/p/58105824 G ...
- 进阶:2.GBDT算法梳理
GBDT算法梳理 学习内容: 1.前向分布算法 2.负梯度拟合 3.损失函数 4.回归 5.二分类,多分类 6.正则化 7.优缺点 8.sklearn参数 9.应用场景 1.前向分布算法 在学习模型时 ...
- 梯度提升树GBDT算法
转自https://zhuanlan.zhihu.com/p/29802325 本文对Boosting家族中一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 简 ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
随机推荐
- Java <clinit> & <init>
在编译生成class文件时,会自动产生两个方法,一个是类的初始化方法<clinit>, 另一个是实例的初始化方法<init>. <clinit>:在jvm第 ...
- [摘抄]VC6.0移植到VS2008(vs2005)后的错误总结(未全部验证)
============================================================================================= 201405 ...
- SecureCRT连接本地的Vmware虚拟机(CentOS)时提示连接超时“Connection timed out”
测试了一下,直接在Vmware的VM里面可以ping通宿主机. 但是宿主机无法ping通VM. 后面发现是本地的网络设置里面的vmware的NAT的网卡设置了手工填写地址和DNS. 修改为自动获取.问 ...
- Java中静态代码块、构造代码块、构造函数、普通代码块
在Java中,静态代码块.构造代码块.构造函数.普通代码块的执行顺序是一个笔试的考点,通过这篇文章希望大家能彻底了解它们之间的执行顺序. 1.静态代码块 ①.格式 在java类中(方法中不能存在静态代 ...
- centos 打包RPM包 ntopng
需要在centos7上,将ntopng及其依赖的包一起打包成rpm包,了解centos7打包. 1.执行: yum -y install rpmdevtools 安装rpm工具 2.接下来执行:rp ...
- Django__RBAC
RBAC : 基于角色的权限访问控制(Role-Based Access Control) RBAC 模型作为目前最为广泛接受的权限模型 角色访问控制(RBAC)引入了Role的概念,目的是为了隔离U ...
- leetcode — word-break-ii
import java.util.*; /** * Source : https://oj.leetcode.com/problems/word-break-ii/ * * Given a strin ...
- Swift语言中与C/C++和Java不同的语法(三)
这一部分的主要内容是Swift中的Collections 我们知道Java中的Collection基本上是每一个Java程序猿接触到的第一个重要的知识点. 在Swift中也不例外,Swift中的Col ...
- js 客户端打印html 并且去掉页眉、页脚
print() 方法用于打印当前窗口的内容,支持部分或者整个网页打印. 调用 print() 方法所引发的行为就像用户单击浏览器的打印按钮.通常,这会产生一个对话框,让用户可以取消或定制打印请求. w ...
- git和github新手安装使用教程(三步入门)
git和github新手安装使用教程(三步入门) 对于新手来说,每次更换设备时,github的安装和配置都会耗费大量时间.主要原因是每次安装时都只关心了[怎么做],而忘记了记住[为什么].本文从操作的 ...