Python3 Scrapy 框架学习
1.安装scrapy 框架
windows 打开cmd输入
pip install Scrapy2.新建一个项目:
比如这里我新建的项目名为first
scrapy startproject first然后看一些目录结构
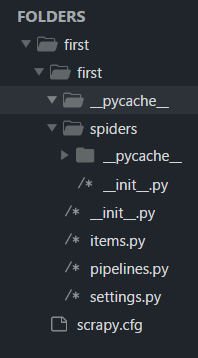
首先在项目目录下有一个scrapy.cfg 文件,这个文件是关于整个项目的一些配置,这个具体后面再说
然后是一个项目同名的文件夹,里面具体文件作用如下:
__init__.py 初始化信息
items.py 作为爬虫项目的数据容器文件,主要用来定义我们要获取的数据
pipelines.py 爬虫项目的管道文件,主要用来对items 里面定义的数据进行进一步的加工处理
settings.py 文件为爬虫项目的设置文件,主要为爬虫项目的一些设置信息
然后下一层的spiders 文件夹里面放置一些爬虫,当然现在里面什么都没有,因为我们还没有新建一个爬虫
这里介绍一下全局命令 和项目 命令
全局命令:不在scrapy项目里就可以使用的命令
项目命令:必须在scrapy项目中才可以使用的命令
全局命令:
注意网址一定要加上http://
fetch : scrapy fetch 网址(不显示调试信息可以加 --nolog 参数)
runspider: scrapy runspider 爬虫(现在项目中没有爬虫,后面具体再讲)
settings:scrapy settings --get 配置项(后面具体再讲)
shell:scrapy shell 网址(在shell终端里面处理爬下来的数据)
view:scrapy view 网址 (将网址数据趴下来并在浏览器中打开)
项目命令:
bench:scrapy bench(测试本地硬件的性能)
genspider:scrapy genspider 爬虫的文件名 定义爬取的域名(scrapy genspider baidu baidu.com)
另外:
-l :查看可以使用的模板 (scrapy genspider -l)
-d:查看模板内容 (scrapy genspider -d basic)
-t:使用模板 (scrapy genspider -t basic 爬虫名 定义爬取的域名)
check:scrapy check 爬虫名(使用合同contract的方式对爬虫进行测试)
crawl:scrapy crawl 爬虫名(启动爬虫,不显示调试信息可以加--nolog参数)
list:scrapy list(显示项目中有哪些爬虫)
edit (这个命令在windows上用不了所以我就不介绍了)
持续更新。。。。。。。。。
Python3 Scrapy 框架学习的更多相关文章
- 自己的Scrapy框架学习之路
开始自己的Scrapy 框架学习之路. 一.Scrapy安装介绍 参考网上资料,先进行安装 使用pip来安装Scrapy 在开始菜单打开cmd命令行窗口执行如下命令即可 pip install Scr ...
- scrapy框架学习之路
一.基础学习 - scrapy框架 介绍:大而全的爬虫组件. 安装: - Win: 下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 ...
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- Scrapy框架学习(一)Scrapy框架介绍
Scrapy框架的架构图如上. Scrapy中的数据流由引擎控制,数据流的过程如下: 1.Engine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取得URL. 2.En ...
- scrapy框架学习
一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- Scrapy框架学习参考资料
00.Python网络爬虫第三弹<爬取get请求的页面数据> 01.jupyter环境安装 02.Python网络爬虫第二弹<http和https协议> 03.Python网络 ...
- scrapy框架学习第一天
今天是学习的第一天: 知识总结如下: 1,调试器相当于原料出口地(URL提供) 2,scrapy相当于中间加工商(具有销售权利)封装URL为request(请求) 3,下载器使用request(请求) ...
- Scrapy框架学习(三)Spider、Downloader Middleware、Spider Middleware、Item Pipeline的用法
Spider有以下属性: Spider属性 name 爬虫名称,定义Spider名字的字符串,必须是唯一的.常见的命名方法是以爬取网站的域名来命名,比如爬取baidu.com,那就将Spider的名字 ...
- Scrapy 框架 (学习笔记-1)
环境: 1.windows 10 2.Python 3.7 3.Scrapy 1.7.3 4.mysql 5.5.53 一.Scrapy 安装 1. Scrapy:是一套基于Twisted的一部处理框 ...
随机推荐
- Eclipse配置Tomcat搭建java Web (JSP)开发环境
配置Tomcat服务 1.打开窗口-首选项-Server-Runtiome Environments 2.点击ADD,选择对应的Tomcat版本,点击下一步 路径选择Tomcat解压后的文件夹目录,点 ...
- Python Client API文档
官网文档地址:http://docs.minio.org.cn/docs/master/python-client-api-reference 初使化MinIO Client对象 from minio ...
- ES重要配置解析
path.data和path.logs 如果您使用.zip或.tar.gz存档,则data和logs 目录是子文件夹$ES_HOME.如果这些重要文件夹保留在其默认位置,则在将Elasticsearc ...
- Elasticsearch方案选型必须了解的10件事!
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484372&idx=1&sn=e863e46 ...
- Java泛型的总结
泛型可以用于接口.类.方法上.还有泛型通配符这个概念 泛型的好处:可以在编译时检查 1.用于方法中,指定该方法中的形参的类型. 语法:修饰符 <代表泛型的变量> 返回值类型 方法名(参数) ...
- 我公司是属于生产制造业,最近考虑实施ERP,生产制造业的ERP那家比较好?
直接告诉你用哪家ERP,那我就太不负责任了,不同企业的规模选用不同的系统,匹配很重要!比如你大型企业,业务管理都比较标准规范,变化性也不大,不差钱预算没问题(千万元起步),你可以考虑下头部厂商.但如果 ...
- 洛谷P7167 [eJOI 2020 Day1] Fountain (单调栈+ST)
开两个数组:to[i][j]表示从i这个位置向下的第2j个圆盘是哪个,f[i][j]表示流满从i这个位置向下的 2j 个圆盘需要多少体积的水. 详情见代码: 1 #include<bits/st ...
- n维偏序 方法记录
题解 首先我们要对一个地点能否到达建立认知:一个地点能到达不仅仅是能从它的上一个点或上上个点跳到,而是能从第一个点开始跳一路跳到.就好比说,咱吃了6个包子吃饱了,但咱不能只付第6个包子的钱. 方法一: ...
- pthread_mutex_t & pthread_cond_t 总结
pthread_mutex_t & pthread_cond_t 总结 一.多线程并发 1.1 多线程并发引起的问题 我们先来看如下代码: #include <stdio.h> # ...
- MySQL安装卸载、idea中Database的使用、常用的sql语句
MySQL安装卸载 MySQL安装 在下面的资源链接中下载MySQL软件压缩包(绿色版),这个版本是MySQL5.7.29的,本教程也只适用于这个绿色版的,如果下载的是安装包那就可能有些地方不一样了, ...