Python3 Scrapy 框架学习
1.安装scrapy 框架
windows 打开cmd输入
pip install Scrapy2.新建一个项目:
比如这里我新建的项目名为first
scrapy startproject first然后看一些目录结构
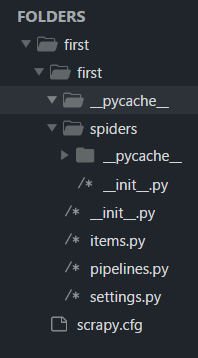
首先在项目目录下有一个scrapy.cfg 文件,这个文件是关于整个项目的一些配置,这个具体后面再说
然后是一个项目同名的文件夹,里面具体文件作用如下:
__init__.py 初始化信息
items.py 作为爬虫项目的数据容器文件,主要用来定义我们要获取的数据
pipelines.py 爬虫项目的管道文件,主要用来对items 里面定义的数据进行进一步的加工处理
settings.py 文件为爬虫项目的设置文件,主要为爬虫项目的一些设置信息
然后下一层的spiders 文件夹里面放置一些爬虫,当然现在里面什么都没有,因为我们还没有新建一个爬虫
这里介绍一下全局命令 和项目 命令
全局命令:不在scrapy项目里就可以使用的命令
项目命令:必须在scrapy项目中才可以使用的命令
全局命令:
注意网址一定要加上http://
fetch : scrapy fetch 网址(不显示调试信息可以加 --nolog 参数)
runspider: scrapy runspider 爬虫(现在项目中没有爬虫,后面具体再讲)
settings:scrapy settings --get 配置项(后面具体再讲)
shell:scrapy shell 网址(在shell终端里面处理爬下来的数据)
view:scrapy view 网址 (将网址数据趴下来并在浏览器中打开)
项目命令:
bench:scrapy bench(测试本地硬件的性能)
genspider:scrapy genspider 爬虫的文件名 定义爬取的域名(scrapy genspider baidu baidu.com)
另外:
-l :查看可以使用的模板 (scrapy genspider -l)
-d:查看模板内容 (scrapy genspider -d basic)
-t:使用模板 (scrapy genspider -t basic 爬虫名 定义爬取的域名)
check:scrapy check 爬虫名(使用合同contract的方式对爬虫进行测试)
crawl:scrapy crawl 爬虫名(启动爬虫,不显示调试信息可以加--nolog参数)
list:scrapy list(显示项目中有哪些爬虫)
edit (这个命令在windows上用不了所以我就不介绍了)
持续更新。。。。。。。。。
Python3 Scrapy 框架学习的更多相关文章
- 自己的Scrapy框架学习之路
开始自己的Scrapy 框架学习之路. 一.Scrapy安装介绍 参考网上资料,先进行安装 使用pip来安装Scrapy 在开始菜单打开cmd命令行窗口执行如下命令即可 pip install Scr ...
- scrapy框架学习之路
一.基础学习 - scrapy框架 介绍:大而全的爬虫组件. 安装: - Win: 下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 ...
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- Scrapy框架学习(一)Scrapy框架介绍
Scrapy框架的架构图如上. Scrapy中的数据流由引擎控制,数据流的过程如下: 1.Engine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取得URL. 2.En ...
- scrapy框架学习
一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- Scrapy框架学习参考资料
00.Python网络爬虫第三弹<爬取get请求的页面数据> 01.jupyter环境安装 02.Python网络爬虫第二弹<http和https协议> 03.Python网络 ...
- scrapy框架学习第一天
今天是学习的第一天: 知识总结如下: 1,调试器相当于原料出口地(URL提供) 2,scrapy相当于中间加工商(具有销售权利)封装URL为request(请求) 3,下载器使用request(请求) ...
- Scrapy框架学习(三)Spider、Downloader Middleware、Spider Middleware、Item Pipeline的用法
Spider有以下属性: Spider属性 name 爬虫名称,定义Spider名字的字符串,必须是唯一的.常见的命名方法是以爬取网站的域名来命名,比如爬取baidu.com,那就将Spider的名字 ...
- Scrapy 框架 (学习笔记-1)
环境: 1.windows 10 2.Python 3.7 3.Scrapy 1.7.3 4.mysql 5.5.53 一.Scrapy 安装 1. Scrapy:是一套基于Twisted的一部处理框 ...
随机推荐
- 第六章:Django 综合篇 - 2:核心配置项
Django的默认配置文件中,包含上百条配置项目,其中很多是我们'一辈子'都不碰到或者不需要单独配置的,这些项目在需要的时候再去查手册. 强调:配置的默认值不是在settings.py文件中!不要以为 ...
- [算法2-数组与字符串的查找与匹配] (.NET源码学习)
[算法2-数组与字符串的查找与匹配] (.NET源码学习) 关键词:1. 数组查找(算法) 2. 字符串查找(算法) 3. C#中的String(源码) 4. 特性Attribute 与内 ...
- 5G 与数字化转型的关系是怎样的?
5G提供的是通信网络服务,数字化转型需要网络服务,但并不是必须使用5G网络,也就是说5G在数字化转型中并不是必虚的,但可以作为备选项,不过在某些行业比如农业.林业.牧业.港口.建筑等布设有线网络.无线 ...
- 引擎之旅 Chapter.4 日志系统
关于近段时间为何没有更新的解释:Find a new job. 目录 引言 日志语句的分类 控制台窗体 和 VSOutput Tab的日志打印 存储至特定的文件中 展示堆栈信息 引言 一般来说,一个优 ...
- VideoPipe可视化视频结构化框架开源了!
完成多路视频并行接入.解码.多级推理.结构化数据分析.上报.编码推流等过程,插件式/pipe式编程风格,功能上类似英伟达的deepstream和华为的mxvision,但底层核心不依赖复杂难懂的gst ...
- 离线安装chrome浏览器的postman插件
最近开始研究webapi相关的东西,看到chrome浏览器的有个postman插件挺好用的,但是安装包下载下来以后会出现这种情况,这时候我们可以把crx后缀的改成zip格式的然后解压,然后选择开发者模 ...
- Windows常用快捷键及基本的Dos命令
Windows 常用快捷键 Ctrl + C: 复制 Ctrl + V: 粘贴 Ctrl + A: 全选 Ctrl + X: 剪贴 Ctrl + Z: 撤销 Ctrl + S: 保存 Alt + F4 ...
- git记不住用户名跟密码,每次提交拉取都需要再次输入
问题:之前为了测试git提交的一个问题,选择不记住用户名跟密码,输入如下命令即可不记住 git credential-manager uninstall git update-git-for-wind ...
- 19.MongoDB系列之批量更新写入Groovy版
Groovy作为脚本,比Java在数据处理中具有更高的灵活性 // 获取mongo连接略 .... def count = 0 for(Township town : townships) { Doc ...
- 深入剖析Sgementation fault原理
深入剖析Sgementation fault原理 前言 我们在日常的编程当中,我们很容易遇到的一个程序崩溃的错误就是segmentation fault,在本篇文章当中将主要分析段错误发生的原因! S ...