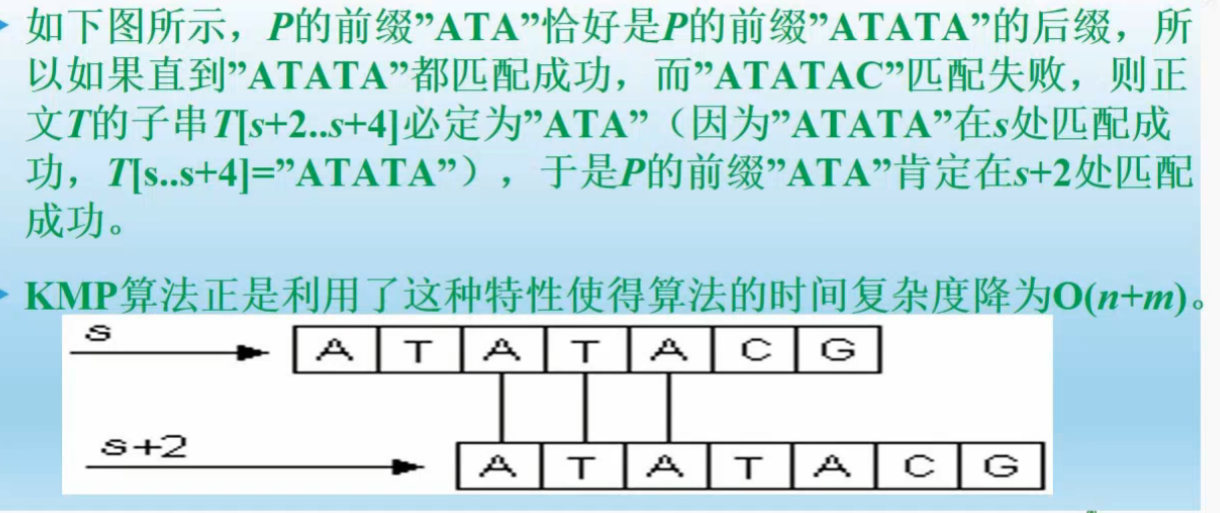
字符串处理------Brute Force与KMP
一,字符串的简单介绍




例:POJ1488 http://poj.org/problem?id=1488
题意:替换文本中的双引号;
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std; int main()
{
char c,flag=1;
//freopen("Atext.in","r",stdin);
while((c=getchar())!=EOF){
if(c=='"'){printf("%s",(flag? "``" : "''"));flag=!flag;}
else printf("%c",c);
}
return 0;
}
二,模式匹配------Brute Force与KMP简介
1,Brute Force算法


例:POJ3080 http://poj.org/problem?id=3080 枚举,BF
新:strstr(str1,str2) 函数用于判断字符串str2是否是str1的子串。如果是,则该函数返回str2在str1中首次出现的地址;否则,返回NULL。
Description
As an IBM researcher, you have been tasked with writing a program that will find commonalities amongst given snippets of DNA that can be correlated with individual survey information to identify new genetic markers.
A DNA base sequence is noted by listing the nitrogen bases in the order in which they are found in the molecule. There are four bases: adenine (A), thymine (T), guanine (G), and cytosine (C). A 6-base DNA sequence could be represented as TAGACC.
Given a set of DNA base sequences, determine the longest series of bases that occurs in all of the sequences.
Input
- A single positive integer m (2 <= m <= 10) indicating the number of base sequences in this dataset.
- m lines each containing a single base sequence consisting of 60 bases.
Output
Sample Input
3
2
GATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
3
GATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATACCAGATA
GATACTAGATACTAGATACTAGATACTAAAGGAAAGGGAAAAGGGGAAAAAGGGGGAAAA
GATACCAGATACCAGATACCAGATACCAAAGGAAAGGGAAAAGGGGAAAAAGGGGGAAAA
3
CATCATCATCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC
ACATCATCATAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AACATCATCATTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT
Sample Output
no significant commonalities
AGATAC
CATCATCAT
Source
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std; int main()
{
//freopen("Atext.in","r",stdin);
int n,m,len;
char ans[70],s[15][65],tmp[65];
cin >> n;
while(n--){
cin >> m;
int k=3,flag=0; //枚举的字符串长度;
ans[0]='\0',tmp[0]='\0',len=0;
for(int i=0;i<m;i++)
for(int j=0;j<60;j++)
cin >> s[i][j];
while(k<=60){ //字符串起点
for(int i=0;i<=60-k;i++){ //枚举长度为k的字符串的起点
memset(tmp,0,sizeof(tmp));//必须记得清空数组!!
for(int j=i,t=0;j<i+k;j++)//这里的i+k,原来敲的是k,傻了傻了,还找了半天!!!
tmp[t++]=s[0][j];
for(int j=1;j<m;j++){
if(strstr(s[j],tmp)==NULL){flag=1;break;}//不是公共子串就标记跳出;
}
if(flag==0){
if(k>len){strcpy(ans,tmp);len=k;}
else if(k==len&&strcmp(ans,tmp)>0){strcpy(ans,tmp);len=k;}
}
flag=0;
}
k++;
}
if(len!=0){
for(int i=0;i<len;i++)
cout << ans[i] ;
}
else
cout << "no significant commonalities" ;
cout << endl;
}
return 0;
}
2,KMP算法




例:POJ3461 Ouliop

例:POJ3461 Oulipo


#include <iostream>
#include <cstdio>
#include <cstring>
const int maxn=10005;
using namespace std;
string s,t;
int n,m;
int nex[maxn];
void getnex(){
int j=0,k=-1;
nex[0]=-1;
while(j<n){
if(k==-1||t[j]==s[k]){
nex[++j]=++k;
}else
k=nex[k];
}
}
int kmp(){
int i=0,j=0,cnt=0;
getnex();
while(i<m){
if(j==-1||s[i]==t[j]){
i++;j++;
}else
j=nex[j];
if(j==n)
cnt++;
}
return cnt;
}
int main()
{
int c;
//freopen("Atext.in","r",stdin);
ios::sync_with_stdio(false); //加了这个,关闭了输入输出同步就过了,不然超时;
cin >> c;
while(c--){
int ans=0;
cin >> t >> s;
n=t.size();
m=s.size();
ans=kmp();
cout << ans << endl;
}
return 0;
}
字符串处理------Brute Force与KMP的更多相关文章
- 常用字符串匹配算法(brute force, kmp, sunday)
1. 暴力解法 // 暴力求解 int Idx(string S, string T){ // 返回第一个匹配元素的位置,若没有匹配的子串,则返回-1 int S_size = S.length(); ...
- 数据结构(十六)模式匹配算法--Brute Force算法和KMP算法
一.模式匹配 串的查找定位操作(也称为串的模式匹配操作)指的是在当前串(主串)中寻找子串(模式串)的过程.若在主串中找到了一个和模式串相同的子串,则查找成功:若在主串中找不到与模式串相同的子串,则查找 ...
- 字符串模式匹配算法--BF和KMP详解
1,问题描述 字符串模式匹配:串的模式匹配 ,是求第一个字符串(模式串:str2)在第二个字符串(主串:str1)中的起始位置. 注意区分: 子串:要求连续 (如:abc 是abcdef的子串) ...
- DVWA全级别之Brute Force(暴力破解)
Brute Force Brute Force,即暴力(破解),是指黑客利用密码字典,使用穷举法猜解出用户口令. 首先我们登录DVWA(admin,password),之后我们看网络是否为无代理,: ...
- DVWA实验之Brute Force(暴力破解)- High
DVWA实验之Brute Force(暴力破解)- High 有关DVWA环境搭建的教程请参考: https://www.cnblogs.com/0yst3r-2046/p/10928380.ht ...
- DVWA实验之Brute Force(暴力破解)- Medium
DVWA实验之Brute Force(暴力破解)- Medium 有关DVWA环境搭建的教程请参考: https://www.cnblogs.com/0yst3r-2046/p/10928380. ...
- DVWA Brute Force:暴力破解篇
DVWA Brute Force:暴力破解篇 前言 暴力破解是破解用户名密码的常用手段,主要是利用信息搜集得到有用信息来构造有针对性的弱口令字典,对网站进行爆破,以获取到用户的账号信息,有可能利用其权 ...
- DVWA之Brute Force
DVWA简介 DVWA(Damn Vulnerable Web Application)是一个用来进行安全脆弱性鉴定的PHP/MySQL Web应用,旨在为安全专业人员测试自己的专业技能和工具提供合法 ...
- DVWA(二): Brute Force(全等级暴力破解)
tags: DVWA Brute Force Burp Suite Firefox windows2003 暴力破解基本利用密码字典使用穷举法对于所有的账号密码组合全排列猜解出正确的组合. LEVEL ...
- 小白日记46:kali渗透测试之Web渗透-SqlMap自动注入(四)-sqlmap参数详解- Enumeration,Brute force,UDF injection,File system,OS,Windows Registry,General,Miscellaneous
sqlmap自动注入 Enumeration[数据枚举] --privileges -U username[CU 当前账号] -D dvwa -T users -C user --columns [ ...
随机推荐
- 在.net core中开发web页面,更新html代码刷新不生效的问题
因为在.net core之后的版本,程序都是以控制台应用程序的方式存在,所以一些老的项目升级后,会出现这样的情况, 解决方法,在nuget中引入 Microsoft.AspNetCore.Mvc.Ra ...
- Serverless 架构演进与实践
Serverless 架构演进与实践 1. 介绍 Serverless 并不仅仅是一个概念,很多地方都已经有了它的影子和思想,本文将给大家介绍最近比较火的 Serverless. 首先放出官方对 Se ...
- lavarel导航分类不显示,因为域名问题不一致导致
$front_menu = isset($category_map['hz9y.hzboso.com']) ? $category_map['hz9y.hzboso.com']->childre ...
- Vue2使用axios,request.js和vue.config.js
1.配置request.js,用来请求数据 import axios from 'axios' // 1:利用axios对象的方法create,创建一个axios实例 // 2:request就是ax ...
- docker学习随笔
总结自https://zhuanlan.zhihu.com/p/187505981 Linux内核提供了Namespace技术来隔离PID/IPC/网络资源等,还提供了Control Group(cg ...
- 学习记录--C++组合+依赖+依赖倒置
组合关系:表示类之间的关系是整体与部分的关系.即has a / contains a的关系 在面向对象程序设计中,将一个复杂对象分解为简单对象的组合. 在代码中,体现为将一个或多个类的对象作为另一个类 ...
- 前端小白启动开源框架vue-element
开发java的我按耐不住想学前端的冲动不想看培训机构的视频,决定自学遇到那种"前端知识图谱"的知识架构,看一眼就完了,不能拿来做入门用入门就得是先把工作环境搭起来,能出活就ok了 ...
- 《Zookeeper分布式过程协同技术详解》之简介-分布式与Zookeeper简介
[常见的分布式架构场景面临的问题]一般在主从架构中,主节点进程负责跟踪从节点的状态和任务的有效性,并分配任务到从节点.而这种架构中必须要解决的几个问题是,主节点崩溃.从节点崩溃.通信故障.主节点崩溃: ...
- K8S 性能优化 - OS sysctl 调优
前言 K8S 性能优化系列文章,本文为第一篇:OS sysctl 性能优化参数最佳实践. 参数一览 sysctl 调优参数一览 # Kubernetes Settings vm.max_map_cou ...
- ElasticSearch 实现分词全文检索 - id、ids、prefix、fuzzy、wildcard、range、regexp 查询
目录 ElasticSearch 实现分词全文检索 - 概述 ElasticSearch 实现分词全文检索 - ES.Kibana.IK安装 ElasticSearch 实现分词全文检索 - Rest ...