第九章:用Python处理省份城市编码数据
本文可以学习到以下内容:
- 免费获取全国省份、城市编码以及经纬度数
- 使用 pandas 中的 read_sql 读取 sqlite 中的数据
- 使用 pandas 中的 merge 方法合并数据
- 使用 groupgy+sort_values 方法实现统计各省人数并降序排列
关注微信公众号《帅帅的Python》,后台回复《数据分析》获取数据及源码
项目背景
“小凡,数据库users表中有客户的资料,我需要你统计一下各省份的客户数量发给我”,经理在早会上给每个人布置任务时说道。
“收到”,小凡一边记录着一边回答到。
早会结束后,小凡接杯热水,回到工位上,打开dataworks、jupyter、datav、quickbi等工具,开始了新一天的工作…
为什么没有省份的数据呢?小凡看着要统计的数据,满脸疑问。
本来以为是简单的统计数据任务,没想到 users 表中只有城市编码数据,没有省份编码,也没有对应的省份中文名。小凡心中顿时有种不祥的预感,在钉钉上联系数据库运维人员询问情况。
运维同学说,当初在设计表的时候没有考虑到省份,所以数据库没有省份字段,让小凡自己想想办法。
小凡也很无奈,现在急切需要找到一份省份编码映射表,逛了各大论坛,找了各种博客网站,问了许多技术朋友
终于在高德地图网站上找到了需要的数据资源:
- 数据已经写入 data.db 数据库中的 adcode_lng_lat 表中
- Excel 文件《省市adcode与经纬度映射表.xlsx》存放在文件夹【数据加工厂】中
剩下的就交给代码吧!
项目代码
小凡常用的数据分析工具:
import os
import datetime
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
数据放在上一级的目录下名为 data.db 的文件
# 数据库地址:数据库放在上一级目录下
db_path = os.path.join(os.path.dirname(os.getcwd()), "data.db")
engine_path = "sqlite:///" + db_path
# 创建数据库引擎
engine = create_engine(engine_path)
sql = """
select * from users
"""
df = pd.read_sql(sql, engine)
用 pandas 的 head() 方法查看前5条数据:
df.head()

新增省份编码
adcode 是城市编码,用前2位加上0000就是省份编码,比如:431081对应的省份编码是430000。
在df后面新增一列省份编码:
df = df.astype(str)
df["province_adcode"] = df["adcode"].map(lambda x:x[:2]+"0000")
获取编码映射数据
sql = """
select * from adcode_lng_lat
"""
adcode_lng_lat_df = pd.read_sql(sql, engine)
合并数据
result_df = pd.merge(df,adcode_lng_lat_df[["adcode","name"]].astype(str),left_on="province_adcode",right_on="adcode",how="left")
用pandas 中的 sample() 方法随机查看10条数据:
result_df.sample(10)
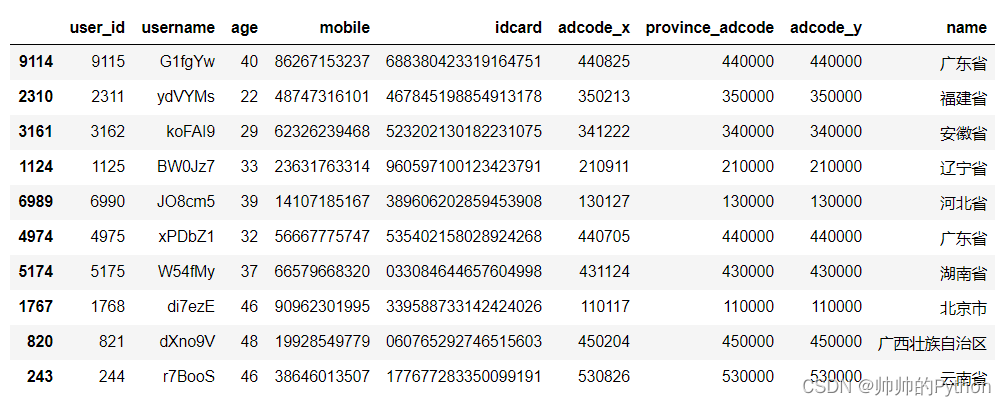
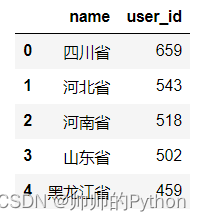
统计省份用户数
使用 groupgy+sort_values 方法实现统计各省人数并降序排列,代码如下:
province_count_df = result_df.groupby(by="name").agg(
{"user_id":"count"}
).sort_values(by="user_id",ascending=False).reset_index()
用 pandas 的 head() 方法查看前5条数据:
province_count_df.head()
使用SQL实现
- sqlite3 的字符串拼接用"||"符号实现
- sqlite3 字符串切割用 SUBSTRING(字符串,开始位置,结束位置)
select
b.name
,count(a.user_id) as users_num
from
(
select
user_id,
username,
adcode,
SUBSTRING(adcode, 1, 2) || '0000' as province_code
from
users
) as a
left join
(
select
adcode as province_code,
name
FROM
adcode_lng_lat
) as b on a.province_code = b.province_code
group by b.name
order by count(a.user_id) desc
;
源码地址
链接:https://pan.baidu.com/s/1ldj51uKEPjpXmAz3XgHiLg?pwd=cj2v
提取码:cj2v
第九章:用Python处理省份城市编码数据的更多相关文章
- 第九章、python文件的两种用途
目录 第九章.python文件的两种用途 一.用途 第九章.python文件的两种用途 一.用途 当前运行的文件(脚本) 被导入的文件(模块) # aaa.py x = 1 def f1(): pri ...
- 第九章:Python高级编程-Python socket编程
第九章:Python高级编程-Python socket编程 Python3高级核心技术97讲 笔记 9.1 弄懂HTTP.Socket.TCP这几个概念 Socket为我们封装好了协议 9.2 cl ...
- 第九章:Python の 网络编程基础(一)
本課主題 何为TCP/IP协议 初认识什么是网络编程 网络编程中的 "粘包" 自定义 MySocket 类 本周作业 何为TCP/IP 协议 TCP/IP协议是主机接入互网以及接入 ...
- 流畅的python第九章符合Python风格的对象学习记录
对象表示形式 每门面向对象的语言至少都有一种获取对象的字符串表示形式的标准方式.Python提供了两种方式 repr()便于开发者理解的方式返回对象的字符串表示形式 str()便于用户理解的方式返回对 ...
- 流畅的python第九章笔记 python风格的python
9.1对象表示形式 __repr__和__str__这两个方法都是用于显示的,__str__是面向用户的,而__repr__面向程序员. 我们打印下面的A是默认输出这个对象的类型,我们对B进行了修改_ ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- python 教程 第九章、 类与面向对象
第九章. 类与面向对象 1) 类 基本类/超类/父类被导出类或子类继承. Inheritance继承 Inheritance is based on attribute lookup in Py ...
- 通过游戏学python 3.6 第一季 第九章 实例项目 猜数字游戏--核心代码--猜测次数--随机函数和屏蔽错误代码--优化代码及注释--简单账号密码登陆--账号的注册查询和密码的找回修改--锁定账号--锁定次数--菜单功能'menufile
通过游戏学python 3.6 第一季 第九章 实例项目 猜数字游戏--核心代码--猜测次数--随机函数和屏蔽错误代码--优化代码及注释--简单账号密码登陆--账号的注册查询和密码的找回修改--锁 ...
- Python 数据分析—第九章 数据聚合与分组运算
打算从后往前来做笔记 第九章 数据聚合与分组运算 分组 #生成数据,五行四列 df = pd.DataFrame({'key1':['a','a','b','b','a'], 'key2':['one ...
- 精通Web Analytics 2.0 (11) 第九章: 新兴分析—社交,移动和视频
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第九章: 新兴分析-社交,移动和视频 网络在过去几年中发生了不可思议的发展变化:从单向对话到双向对话的转变; 由视频,Ajax和 ...
随机推荐
- 【踩坑记录】docker启动报错mountpoint for cgroup not found
具体报错信息: docker: Error response from daemon: OCI runtime create failed: container_linux.go:345: start ...
- iTab浏览器插件使用教程
iTab浏览器插件 iTab是一个好看好用的自定义卡片式浏览器新标签页扩展. 安装iTab标签页扩展后,您将告别呆板无趣的原生标签页,享受iTab标签页为您带来的个性化新体验: iTab资源 安装教程 ...
- 详谈pytest中的xfail
详谈pytest中的xfail 原文链接: https://docs.pytest.org/en/7.2.x/how-to/skipping.html 链接中详细阐述了skip和xfail两种情况 x ...
- python爬取丁香园疫情数据
毕设需求了就是说 导师要做关于时间线的- -看发展趋势 不得不今天又现学现卖 首先 创建一个python文件 python.file 引入一点资源 # 发送请求 import requests # 页 ...
- RocketMQ - 生产者原理
https://rocketmq.apache.org/ Apache RocketMQ是一款开源的.分布式的消息投递与流数据平台.出生自阿里巴巴,在阿里巴巴内部经历了3个版本后,作为Apache 顶 ...
- 树莓派VNC复制粘贴
1.安装sudo apt install autocutsel 2.运行autocutsel -f
- 安装kali2021.1系统
基本安装 下载地址:Downloads | Kali Linux 去官网下载,会得到kali2021.1的镜像和哈希值 打开VMware软件,新建虚拟机........................ ...
- vue3 语法糖setup 兄弟组件传值
使用 mitt // 全局引入 npm install mitt 或者 cnpm install mitt 在main文件中挂载 import { createApp } from 'vue' imp ...
- Typescript 回调函数、事件侦听的类型定义与注释--拾人牙慧
实际项目中会运到的 Typescript 回调函数.事件侦听的类型定义,如果刚碰到会一脸蒙真的,我就是 这是第一次我自己对 Typescript 记录学习,所以得先说一下我与 Typescript 的 ...
- KMP字符串 AcWing 831
题目:https://www.acwing.com/problem/content/833/ 题意:求子串在母串中每次出现时的下标位置. 题解:哈哈哈,敲题时想到之前看到一个人叫 kmp 算法为 看毛 ...