信息论之从熵、惊奇到交叉熵、KL散度和互信息
一、熵(PRML)
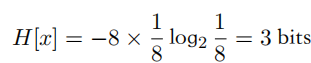
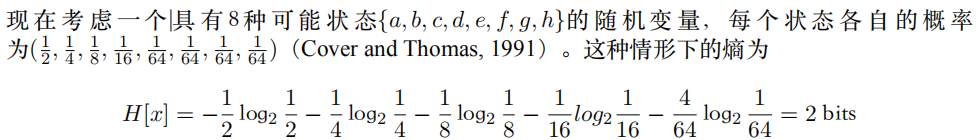
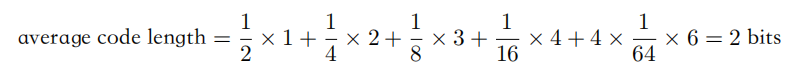
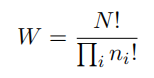
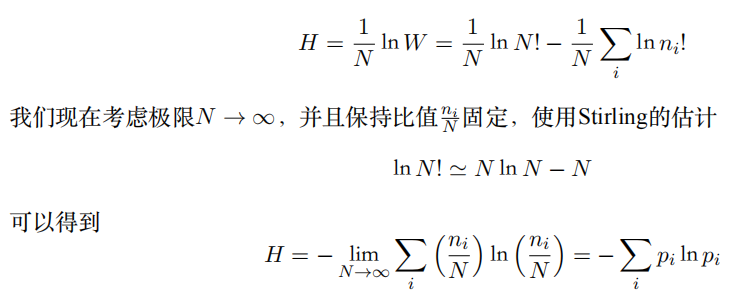
二、惊奇与信息

- 如果有⼈告诉我们⼀个相当不可能的事件发⽣了,我们收到的信息要多于我们被告知某个很可能发⽣的事件发⽣时收到的信息。
- 如果听到⼀个必然事情,那么就不会接收到信息。EX: 明天有24h
- 如果有两个不相关的事件x和y,那么观察到两个事件同时发⽣时获得的信息应该等于观察到事件各⾃发⽣时获得的信息之和,即h(x, y) = h(x) + h(y)。
- 两个不相关事件是统计独⽴的,因此p(x, y) = p(x)p(y)。
- 其中,负号确保了信息⼀定是正数或者是零。
- 注意,低概率事件x对应于⾼的信息量。
- 对数的底遵循信息论使⽤2作为对数的底(2进制编码最短)。


三、熵的相关变量
熵用于衡量不确定性,其相当于是编码一个随机变量的平均最小编码长度(最优编码的下界,即huffman编码)
1.自信息-二进制编码长度
\]
2.信息熵
= - \int p(x)\ln p(x)dx
\\ = \int p(x)\ln \frac{1}{p(x)}dx
= \mathbb{E}_{x\sim p(x)}\left[\ln\frac{1}{p(x)}\right]
\]
3.交叉熵,用一个分布p(x)的编码去编码另一个分布q(x)的代价(平均编码长度)
= - \int p(x)\ln q(x)dx
\\ = \mathbb{E}_{x\sim p(x)}\left[\ln\frac{1}{q(x)}\right]
\]
分布q(x)的自信息(最小编码长度)关于分布p(x)的期望
Ex: q(x1) = 0.25需要2bits,例如00来编码,但p(x1)=0.01
,相当于用更短的编码来编码低频取值(不符合高频短码),可能导致编码代价更大。
随机变量取值越多,熵越大(信息增益)
4.KL散度,衡量两个分布p(x)和q(x)的距离(不相似程度):
用一个分布p(x)的编码去编码另一个分布q(x)的额外代价
若KL散度为0,则表示编码额外代价为0,即两个分布相同
= - \int p(x)\ln \frac{q(x)}{p(x)} dx
= \int p(x)\ln \frac{p(x)}{q(x)} dx
\\= \int p(x)\ln p(x) - p(x)\ln q(x)dx
\\ = - \int p(x)\ln q(x)dx - (-\int p(x)\ln p(x) )
\\ = C\Big(p(x)\Big\Vert q(x)\Big) - H\Big(p(x)\Big)
\\ =
\mathbb{E}_{x\sim p(x)}\left[\ln\frac{p(x)}{q(x)}\right] \]
由于熵为常数项,最小化交叉熵,相当于最小化KL散度(最大似然),离散形式即求和。
- 互信息

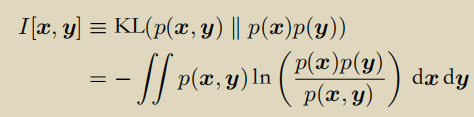
联合分布p(x, y)和边缘分布乘积累p(x)p(y)的KL散度。
如果互信息为0,则两个边缘分布独立p(x, y) = p(x) p(y)
信息论之从熵、惊奇到交叉熵、KL散度和互信息的更多相关文章
- 深度学习面试题07:sigmod交叉熵、softmax交叉熵
目录 sigmod交叉熵 Softmax转换 Softmax交叉熵 参考资料 sigmod交叉熵 Sigmod交叉熵实际就是我们所说的对数损失,它是针对二分类任务的损失函数,在神经网络中,一般输出层只 ...
- 信息论相关概念:熵 交叉熵 KL散度 JS散度
目录 机器学习基础--信息论相关概念总结以及理解 1. 信息量(熵) 2. KL散度 3. 交叉熵 4. JS散度 机器学习基础--信息论相关概念总结以及理解 摘要: 熵(entropy).KL 散度 ...
- 【机器学习基础】熵、KL散度、交叉熵
熵(entropy).KL 散度(Kullback-Leibler (KL) divergence)和交叉熵(cross-entropy)在机器学习的很多地方会用到.比如在决策树模型使用信息增益来选择 ...
- 交叉熵理解:softmax_cross_entropy,binary_cross_entropy,sigmoid_cross_entropy简介
cross entropy 交叉熵的概念网上一大堆了,具体问度娘,这里主要介绍深度学习中,使用交叉熵作为类别分类. 1.二元交叉熵 binary_cross_entropy 我们通常见的交叉熵是二元交 ...
- 第五节,损失函数:MSE和交叉熵
损失函数用于描述模型预测值与真实值的差距大小,一般有两种比较常见的算法——均值平方差(MSE)和交叉熵. 1.均值平方差(MSE):指参数估计值与参数真实值之差平方的期望值. 在神经网络计算时,预测值 ...
- 理解交叉熵(cross_entropy)作为损失函数在神经网络中的作用
交叉熵的作用 通过神经网络解决多分类问题时,最常用的一种方式就是在最后一层设置n个输出节点,无论在浅层神经网络还是在CNN中都是如此,比如,在AlexNet中最后的输出层有1000个节点: 而即便是R ...
- 信息论随笔3: 交叉熵与TF-IDF模型
接上文:信息论随笔2: 交叉熵.相对熵,及上上文:信息论随笔 在读<数学之美>的时候,相关性那一节对TF-IDF模型有这样一句描述:"其实 IDF 的概念就是一个特定条件下.关键 ...
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
- 熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练模型的时候就不停地调整参数使得我们预测出来的概率和真是的概率更加接近. 这篇文章我们关注在我们的模型假设这些类 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
随机推荐
- centos7 系统运行中做raid磁盘阵列
插入磁盘 lsblk查看磁盘总体情况 对sdb1等需要做的硬盘进行制作 fdisk /dev/sdb 开始 n 创建 p 给资源回车 重选代码 t 确认磁盘阵列代码 fd 保存w 首先安装工具 mda ...
- SSD目标检测网络解读(含网络结构和内容解读)
SSD实现思路 SSD具有如下主要特点: 从YOLO中继承了将detection转化为regression的思路,一次完成目标定位与分类 基于Faster RCNN中的Anchor,提出了相似的Pri ...
- Jmeter读取Csv文件,字段中有逗号分隔,读取不成功
Jmeter读取Csv文件,字段中有逗号分隔,读取不成功
- C++ condition_variable
一.使用场景 在主线程中创建一个子线程去计数,计数累计100次后认为成功,并告诉主线程:主线程收到计数100次完成的信息后继续往下执行 二.条件变量的成员函数 wait:当前线程调用 wait() 后 ...
- 实验二:Open vSwitch虚拟交换机实践
基础要求提交 a) /home/用户名/学号/lab2/目录下执行ovs-vsctl show命令.以及p0和p1连通性测试的执行结果截图: b) /home/用户名/学号/lab2/目录下开启Min ...
- Windows Oracle 启动OracleDBConsoleorcl 服务时报 Window不能在 本地计算机启动 OracleDBConsoleorcl 。有关更多信息,查阅系统事件日志。如果这是非Microsoft服务,请与服务厂商联系,并参考特定服务错误代码 2 。
一.报错信息如图 二.原因分析: 计算机主机名或IP地址有变化 三.解决方法 依次输入命令: Microsoft Windows [版本 10.0.22000.795](c) Microsoft Co ...
- django+easyui
django+easyui 快速构建网站 演示地址:http://demo.topjui.com/?from=360tg
- Cesium渲染模块之Shader
1. 引言 Cesium是一款三维地球和地图可视化开源JavaScript库,使用WebGL来进行硬件加速图形,使用时不需要任何插件支持,基于Apache2.0许可的开源程序,可以免费用于商业和非商业 ...
- 为什么 Go 语言 struct 要使用 tags
原文链接:为什么 Go 语言 struct 要使用 tags 在 Go 语言中,struct 是一种常见的数据类型,它可以用来表示复杂的数据结构.在 struct 中,我们可以定义多个字段,每个字段可 ...
- Spring--AOP切入点表达式
AOP工作流程 能够与做代理的那个类匹配得上的话,叫做代理对象,否则为原始对象. (SpringAOP的本质:代理模式) AOP的切入点表达式 切入点表达式描述的标准格式 描述方式一:定位到某某包下的 ...