聚类--DBSCN
1、什么是DBSCN
DBSCAN也是一个非常有用的聚类算法。
- 它的主要优点:它不需要用户先验地设置簇的个数,可以划分具有复杂形状的簇,还可以找出不属于任何簇的点。
- DBSCAN比凝聚聚类和k均值稍慢,但仍可以扩展到相对较大的数据集。
1.1算法原理
DBSCAN的原理是识别特征空间的“拥挤”区域中的点,在这些区域中许多数据点靠近在一起。这些区域被称为特征空间中的密集区域。
- DBSCAN背后的思想:簇形成数据的密集区域,并由相对较空的区域分隔开。
在密集区域内的点被称为核心样本(或核心点),它们的定义如下。
- DBSCAN有两个参数:min_samples和eps。
- 如果在距一个给定数据点eps的距离内至少有min_samples个数据点,那么这个数据点就是核心样本。
- DBSCAN将彼此距离小于eps的核心样本放到同一个簇中。
一共有三种类型的点:核心点,与核心点的距离在eps之内的点(叫做边界点)和噪声。
- 如果DBSCAN算法在特定数据集上多次运行,那么核心点的聚类始终相同,同样的点也始终被标记为噪声。
- 但边界点可能与不止一个簇的核心样本相邻。因此,边界点所属的簇依赖于数据点的访问顺序。
- 一般来说只有很少的边界点,这种对访问顺序的轻度依赖并不重要。
2、应用于模拟数据make_blobs
X, y = make_blobs(random_state=0,n_samples=12)
dbscan = DBSCAN()
clusters = dbscan.fit_predict(X)
print("Cluster memberships:\n{}".format(clusters))
输出:
Cluster memberships:
[-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
因为eps和min_samples设置不当,所有的数据都被标记为噪声
可视化
mglearn.plots.plot_dbscan()
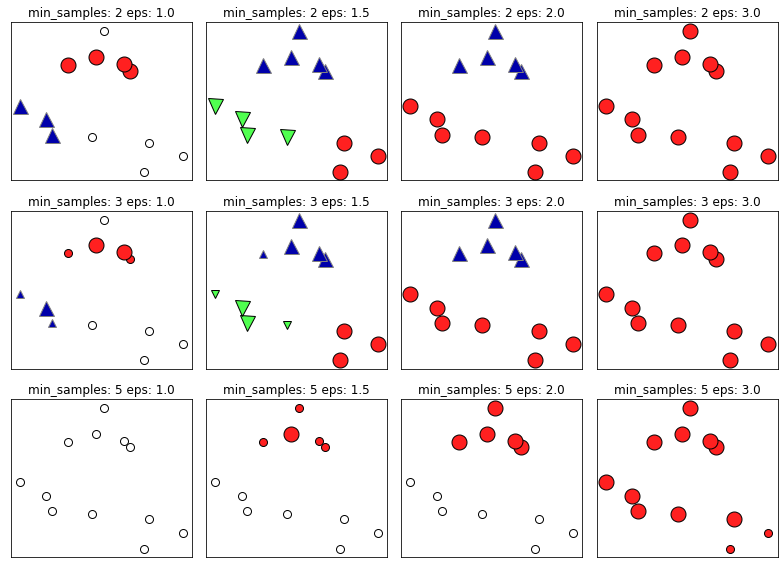
- 在这张图中,属于簇的点是实心的,噪声点为空心。核心样本显示为较大的标记,边界点则显示为较小的标记。
- 增大eps,扩大核心点的领域,会让一个簇变得更大
- 增大min_samples会让一个簇中包含更多的点,同时核心点变小,噪声变多
- eps更重要
- 它决定了点与点之间“接近的含义”。
- eps过小,没有点是核心样本
- eps过大,所有点成单个簇
- 它决定了点与点之间“接近的含义”。
- min_samples是为了判断稀疏区域内的点被标记为异常值还是形成自己的簇
- 决定了簇的尺寸
3、应用于模拟数据make_moons
虽然DBSCAN不需要显式地设置簇的个数,但设置eps可以隐式地控制找到的簇的个数。使用StandardScaler或MinMaxScaler对数据进行缩放之后,有时会更容易找到eps的较好取值,因为使用这些缩放技术将确保所有特征具有相似的范围.
from sklearn.datasets import make_moons
from sklearn.preprocessing import StandardScaler
from matplotlib import pyplot as plt
X, y = make_moons(n_samples=200,noise=0.05,random_state=0)
#将数据缩放成平均值为0,方差为1
scaler = StandardScaler().fit(X)
X_scaled = scaler.transform(X)
dbscan = DBSCAN()
clusters = dbscan.fit_predict(X_scaled)
#绘制簇分配
plt.scatter(X_scaled[:,0],X_scaled[:,1],c=clusters,cmap=mglearn.cm2,s=60)
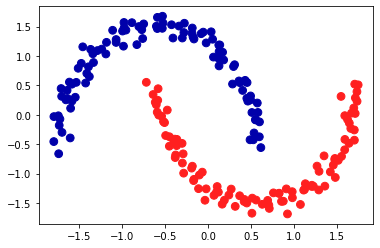
可以看到,利用DBSCAN的默认设置,算法找到了两个半圆形并将其分开。
由于算法找到了我们想要的簇的个数(2个),因此参数设置的效果很好。
- 如果将eps减小到0.2(默认值为0.5),我们将会得到8个簇,这显然太多了。
- 将eps增大到0.7则会导致只有一个簇。
4、参考文献
《python机器学习基础教程》P143-P147
聚类--DBSCN的更多相关文章
- 用scikit-learn学习谱聚类
在谱聚类(spectral clustering)原理总结中,我们对谱聚类的原理做了总结.这里我们就对scikit-learn中谱聚类的使用做一个总结. 1. scikit-learn谱聚类概述 在s ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 用scikit-learn学习BIRCH聚类
在BIRCH聚类算法原理中,我们对BIRCH聚类算法的原理做了总结,本文就对scikit-learn中BIRCH算法的使用做一个总结. 1. scikit-learn之BIRCH类 在scikit-l ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- BIRCH聚类算法原理
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理.这里我们再来看看另外一种常见的聚类算法BIRCH.BIRCH算法比较适合于数据量大,类别数K也 ...
随机推荐
- js 中的submit 回调函数
1.submit.php <?php $arr = $_POST; $arr['msg']=1; //echo $_POST['uname']; echo json_encode($arr); ...
- 标签页tab.js 在栏目之间切换,局部变化
1.在使用bootstrap 中,我们会用到在栏目之间切换,来刷新页面的局部,可以使用下面的方法 <link rel="stylesheet" href="http ...
- ES6-11学习笔记--代理Proxy
Proxy代理 常用拦截方法 ES5拦截: let obj = {} let newVal = '' Object.defineProperty(obj, 'name', { get() { cons ...
- ES6-11学习笔记--扩展运算符与rest参数
1.符号都是使用:... 2.扩展运算符:把数组或者类数组展开成用逗号隔开的值 3.rest参数:把逗号隔开的值组合成一个数组 扩展运算符: function foo(a, b, c) { con ...
- java中什么叫覆盖Override?请给实例
5.覆盖(Override) 马克-to-win:方法的覆盖(Override)是指子类重写从父类继承来的一个同名方法(参数.返回值也同). 例1.5.1-- class AAAMark_to_win ...
- webpack 4.0 配置方法以及错误解决
选取一个空目录来试验 全局安装webpack4.1之后 创建目录 mkdir webpacktest && cd webpacktes 初始化package.json npm init ...
- python---反转链表
class Node: def __init__(self, data): self.data = data self.next = None class Solution: "" ...
- Power App门户
1.创建门户 在powerapp应用中添加新应用选择:门户. 填写名称和地址,地址写完后会检测可用,创建会等待几分钟. 2.门户组件 节,容器分为1.2.3列 1.文本:可编辑字体 2.图像:可选择连 ...
- 3道常见的vue面试题,你都会了吗?
最近流传各大厂纷纷裁员,导致很多人"被迫"毕业,显然很多人还是想留级,无奈出现在名单中,只能感叹命运不公,不过拿了N+1,也算是很欣慰. 又得去面试了,接下来一起来巩固下vue的3 ...
- SpringMVC踩坑3——前后端传值问题
在前端页面点击修改,同时把需要修改的ID传到后端,后端根据ID去修改具体数据 这是前端代码 <a href="${pageContext.request.contextPath}/bo ...