MixCSE:困难样本在句子表示中的使用
Unsupervised Sentence Representation via Contrastive Learning with Mixing Negatives
论文地址:https://www.aaai.org/AAAI22Papers/AAAI-8081.ZhangY.pdf
代码地址:https://github.com/BDBC-KG-NLP/MixCSE_AAAI2022
动机:困难样本挖掘对训练过程中维持强梯度信号是至关重要的,同时,随机采样负样本对于句子表示是无效的。
为什么直接用预训练的bert得到的句向量不好?
因为各向异性。各向异性是指嵌入在向量空间中占据一个狭窄的圆锥体。各向异性就有个问题,那就是最后学到的向量都挤在一起,彼此之间计算余弦相似度都很高,并不是一个很好的表示。一个好的向量表示应该同时满足Alignment 和 uniformity,前者表示相似的向量距离应该相近,后者就表示向量在空间上应该尽量均匀,最好是各向同性的[1]。因此,才会有一系列的论文旨在解决各向异性,比如bert-flow、bert-whitening。
对比学习在句子表示中的使用?
对比学习就是我们要学习到一个映射,当句子通过这个映射之后,比如x,我们希望和x相似的正样本的之间的分数要大于和x不相似的负样本的分数,当然,这个分数我们可以自定义一个计算方式。问题是对于大量的数据而言,我们怎么去构建正样本和负样本? ConsBERT使用大量的数据增强策略,比如token shuffling和cutoff。Kim, Yoo, and Lee利用bert的隐含层表示和最后的句嵌入构建正样本对。SimCSE 使用不同的dropout mask将相同的句子传递给预训练模型两次,以构建正样本对。目前的一些模型主要关注的是在生成正样本对时使用数据增强策略,而在生成负样本对时使用随机采样策略。在计算机视觉中,困难样本对于对比学习是至关重要的,而在无监督对比学习中还没有被探索。
对比学习的基本介绍?
我们先定义一个anchor(锚,可以是任意一个句子) \(h_{i}\),定义\((h_{i}, h_{i}^{'})\)是一个正样本对,N个负样本是随机采样得到,\((h_{i},h_{j}^{'})\)表示一个负样本对,那么我们就有最小化以下的对比损失:
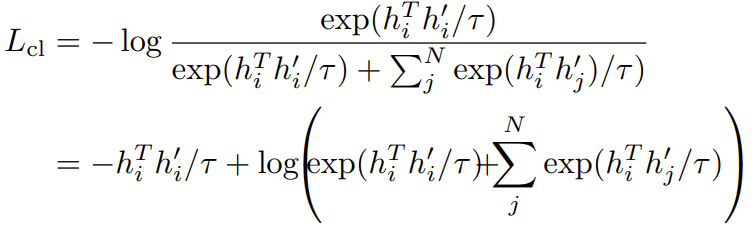
其中\(\tau\)是一个标量温度超参数。以上损失对\(h_{i}\)求偏导可以得到:
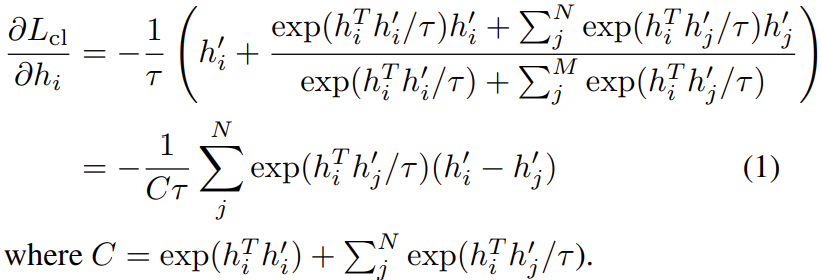
对于每一个负样本特征\(h_{j}^{'}\),\(h_{i}\)沿着\(h_{i}^{'}-h_{j}^{'}\)的方向进行更新。由于\(h_{i}^{'}-h_{j}^{'}=(h_{i}^{'}-h_{i})-(h_{j}^{'}-h_{i})\),这可以视为更新是沿着\(h_{i}^{'}-h_{i}\)的方向,而与\(h_{j}^{'}-h_{i}\)方向相反。换句话说,我们会让正样本\(h_{i}^{'}\)更接近于\(h_{i}\),而让负样本\(h_{j}^{'}\)更远离\(h_{i}\)。注意到公式(1)中第j项的梯度是依赖于\(exp(h_{i}^{T}h_{j}^{'}/\tau)\),所以它随内积\(h_{i}^{T}h_{j}^{'}\)呈指数增长。这扩大了和不同负样本\(h_{j}^{'}\)特征相关的梯度值。因此,锚点上不易分辨的负特征\(h_{j}^{'}\)(即那些内积\(h_{i}^{T}h_{j}^{'}\)较大的)接收到更大的梯度信号,从而将它们推离锚点。
另一方面,注意到\(exp(h_{i}^{T}h_{j}^{'}/\tau)\)<<\(exp(h_{i}^{T}h_{i}^{'}/\tau)\),让\(exp(h_{i}^{T}h_{j}^{'}/\tau)\)相对于\(exp(h_{i}^{T}h_{i}^{'}/\tau)\)显得更没有意义 ,特别是随着训练的进行,前者不断减小,后者不断增加直至接近\(e\)。然后公式(1)给出的梯度信号不断减小,使得训练变慢甚至停止。
在这一点上,我们看到锚附近的负特征的存在对于保持强梯度信号是至关重要的。我们将这种难以区分的负面特征称为“困难负面特征”。这项工作的关键发展是不断地在训练过程中注入人工的困难负面特征,因为原本的困难负面特征正在被推开,变得“更容易”。
MixCSE的基本介绍?
该方法在训练过程中不断地注入人工困难负特征,从而在整个训练过程中保持强梯度信号。
对于锚特征\(h_{i}\),通过混合正特征\(h_{i}^{'}\)和随机负特征\(h_{j}^{'}\)构建负特征:
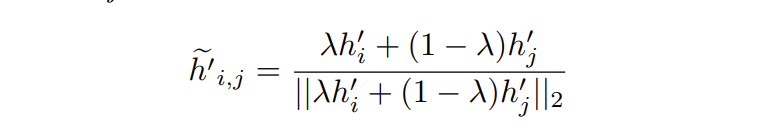
\(\lambda\)是一个超参数,用于控制混合的程度。包含这些混合负特征后,对比损失变为:
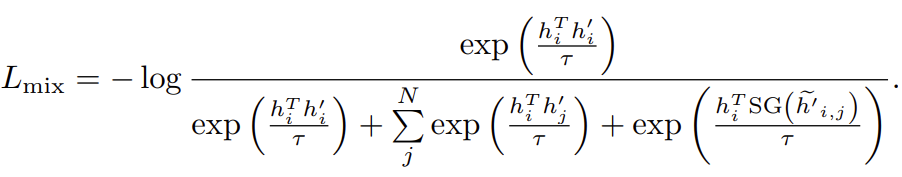
\(SG(.)\)定义为梯度停止,确保在反向传播时不会经过混合负样本。
接着,我们注意到锚和混合负样本的内积:
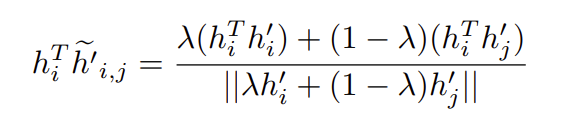
在某些阶段,\(h_{i}^{T}\widetilde{h}_{i,j}^{'}\approx0\)。另外,在实现对齐时,\(h_{i}^{T}h_{i}^{'}\approx1\)。则有:
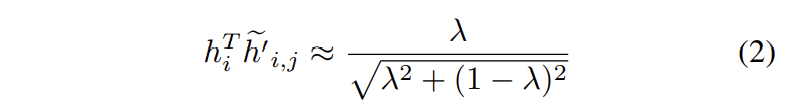
不像标准的负特征\(h_{j}^{i}\)有\(h_{i}^{T}h_{j}^{'}\approx0\)的风险。混合负特征确保内积值始终高于零。这样的负特征则有助于保持更强的梯度信号。
怎么选择\(\lambda\)?
假设有两个正样本特征\(h_{i}^{'}\)和\(h_{i}^{''}\),角度分别为\(0\)和\(\gamma\)。
锚和混合负样本间的角度计算为:
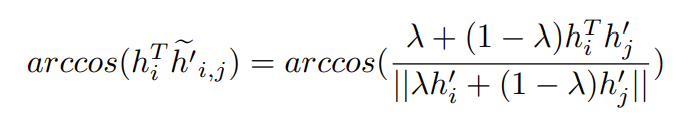
我们既要让混合负样本更接近锚,同时也要让正样本和锚之间比正样本和混合负样本之间更接近,因此\(\lambda\)有一个上界:
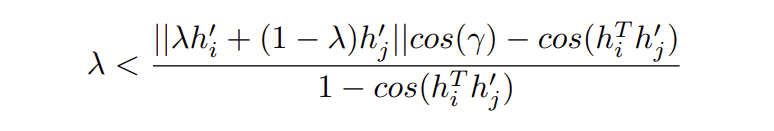
但是我们并不知道\(\gamma\)的值,因此设置较小的\(\lambda\)以避免获得错误的困难样本。
为什么不让混合负样本参与反向传播?
如果参与,计算梯度如下:

我们看到会有一项:
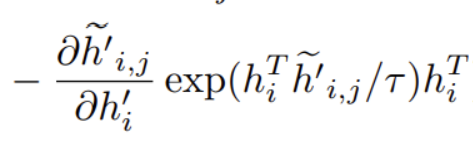
它会使得正样本\(h_{i}^{i}\)逐渐远离\(h_{i}\)。
实验结果?
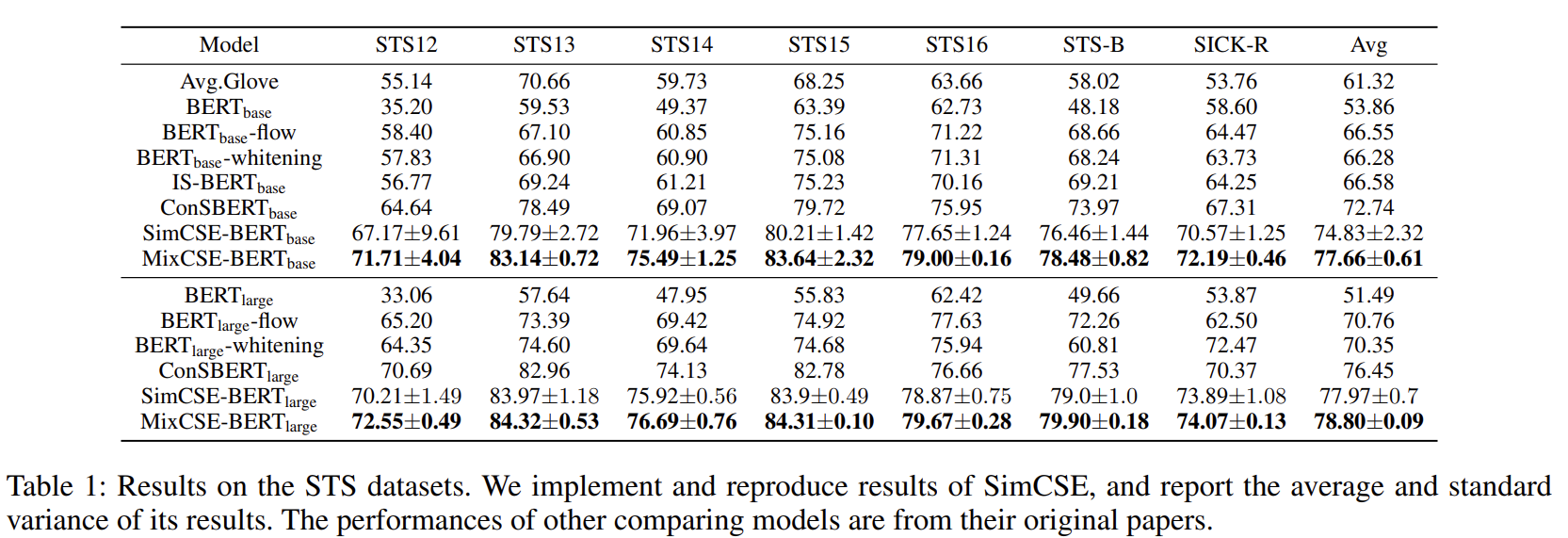
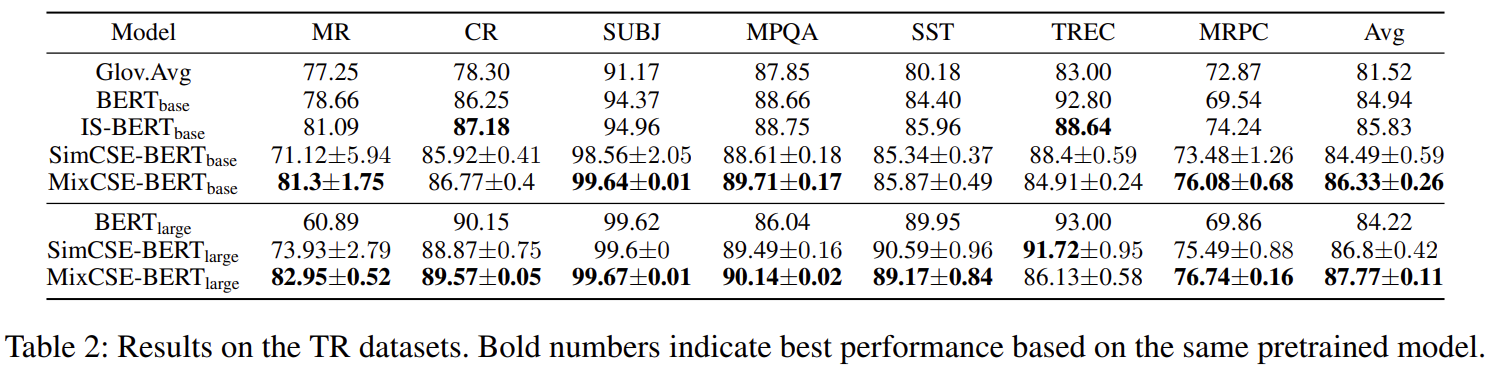
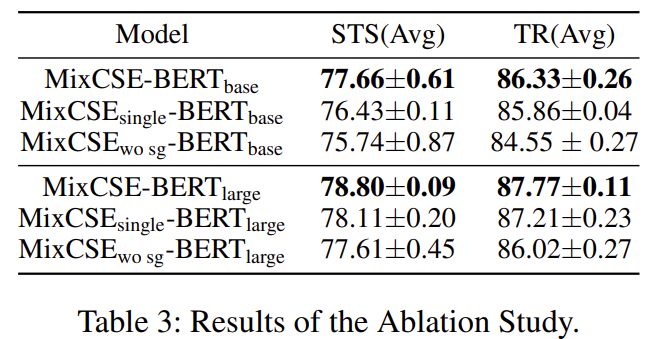
MixCSE:困难样本在句子表示中的使用的更多相关文章
- 孪生网络(Siamese Network)在句子语义相似度计算中的应用
1,概述 在NLP中孪生网络基本是用来计算句子间的语义相似度的.其结构如下 在计算句子语义相似度的时候,都是以句子对的形式输入到网络中,孪生网络就是定义两个网络结构分别来表征句子对中的句子,然后通过曼 ...
- pytorch中网络特征图(feture map)、卷积核权重、卷积核最匹配样本、类别激活图(Class Activation Map/CAM)、网络结构的可视化方法
目录 0,可视化的重要性: 1,特征图(feture map) 2,卷积核权重 3,卷积核最匹配样本 4,类别激活图(Class Activation Map/CAM) 5,网络结构的可视化 0,可视 ...
- Libliner 中的-s 参数选择:primal 和dual
Libliner 中的-s 参数选择:primal 和dual LIBLINEAR的优化算法主要分为两大类,即求解原问题(primal problem)和对偶问题(dual problem).求解原问 ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 论文学习笔记--无缺陷样本产品表面缺陷检测 A Surface Defect Detection Method Based on Positive Samples
文章下载地址:A Surface Defect Detection Method Based on Positive Samples 第一部分 论文中文翻译 摘要:基于机器视觉的表面缺陷检测和分类可 ...
- 基于N-Gram判断句子是否通顺
完整代码实现及训练与测试数据:click me 一.任务描述 自然语言通顺与否的判定,即给定一个句子,要求判定所给的句子是否通顺. 二.问题探索与分析 拿到这个问题便开 ...
- (转载)人脸识别中Softmax-based Loss的演化史
人脸识别中Softmax-based Loss的演化史 旷视科技 近期,人脸识别研究领域的主要进展之一集中在了 Softmax Loss 的改进之上:在本文中,旷视研究院(上海)(MEGVII Re ...
- 使用BERT模型生成句子序列向量
之前我写过一篇文章,利用bert来生成token级向量(对于中文语料来说就是字级别向量),参考我的文章:<使用BERT模型生成token级向量>.但是这样做有一个致命的缺点就是字符序列长度 ...
- 图像分割中的loss--处理数据极度不均衡的状况
序言: 对于小目标图像分割任务,一副图画中往往只有一两个目标,这样会加大网络训练难度,一般有三种方法解决: 1.选择合适的loss,对网络进行合理优化,关注较小的目标. 2.改变网络结构,使用atte ...
随机推荐
- 前端ES6 特性兼容查询
ES6 http://kangax.github.io/compat-table/es6/ ES5 http://kangax.github.io/compat-table/es5/ ES 2016+ ...
- [自制操作系统] 第02回 初识MBR
目录 一.前景回顾 二.写一个粗略的MBR 三.运行测试 一.前景回顾 上回说到,开机的启动过程就是当时Intel和BIOS等硬件厂商所制定的规则,现在我们来回顾一下有如下三点: 1.按下开机键后,C ...
- ssh打通
打通ssh https://www.cnblogs.com/yolanda-lee/p/4975453.html
- 数据库 OLAP、OLTP是什么?相同和不同?适用场景
一.OLTP和OLAP是什么,二者比较 人类世界遵从基本的物理规律,数据世界里,关于数据的操作处理,也大体分为OLTP和OLAP两类. OLTP on-line transaction process ...
- C#生成putty格式的ppk文件(支持passphrase)
背景 2022国家级护网行动即将开启,根据阿里云给出的安全建议,需要将登陆Linux的方式改为密钥对方式.我这里使用的远程工具是自己开发的,能够同时管理Windows和Linux,但是以前不支持密钥对 ...
- 快速入门python看过的一些资料
我快速入门python看过的一些资料 B站的视频 10天自学Python,轻松掌握Python基础[千锋] 廖雪峰 - Python教程 https://www.liaoxuefeng.com/wik ...
- ELK 日志分析系统的部署
一.ELK简介 ElasticSearch介绍Elasticsearch是一个基于Lucene的搜索服务器. 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口. Elasti ...
- RK3568开发笔记(四):在虚拟机上使用SDK编译制作uboot、kernel和buildroot镜像
前言 上一篇搭建好了ubuntu宿主机开发环境,本篇的目标系统主要是开发linux+qt,所以需要刷上billdroot+Qt创建的系统,为了更好的熟悉原理和整个开发过程,选择从零开始搭建rk35 ...
- scala WordCount案例
数据样例: java,spark,hadoop,python,datax java,spark,hadoop,spark,python,datax java,spark,hadoop,python,d ...
- ROS机械臂 Movelt 学习笔记1 | 基础准备
环境:Ubuntu18.04 + ROS Melodic 1. 安装ROS 官网下载安装步骤:http://wiki.ros.org/melodic/Installation/Ubuntu 一键安装的 ...