【pytest官方文档】解读- 插件开发之hooks 函数(钩子)
上一节讲到如何安装和使用第三方插件,用法很简单。接下来解读下如何自己开发pytest插件。
但是,由于一个插件包含一个或多个钩子函数开发而来,所以在具体开发插件之前还需要先学习hooks函数。
一、什么是 hooks 函数
简单来说,在 pytest 的代码中,预留出了一些函数供我们修改,以便来改变pytest工作方式,这些函数就是hooks函数,我们可以直接重写函数里的内容。
比如,在 pytest代码路径\Lib\site-packages\_pytest\hookspec.py中,可以看到 pytest 定义好的 hook 规范,方便我们在开发插件的时候参考规范来调用对应的hooks函数。
二、hooks 函数的分类
从hooks函数的职责分类来看,大概如下几类:
- Bootstrapping hooks:引导类钩子,用来调用已经早就注册好的内部插件和第三方插件。
- Collection hooks:集合类钩子,pytest 调用集合钩子来收集文件和目录。
- Test running (runtest) hooks:测试运行相关的钩子,所有与测试运行相关的钩子都接收一个
pytest.Item对象。 - Reporting hooks:与Session 会话相关的钩子。
- Debugging/Interaction hooks:调试/交互钩子,少有的可以用于特殊的报告或与异常交互的钩子函数。
可供调用的钩子函数有很多,功能也是各式各样的,有兴趣的童鞋可以进一步细看官方文档里的介绍。我们就是要通过不同钩子函数具备的功能,来实现我们自定义的需求。
三、编写 hooks 函数开发本地插件
写一个插件示例。
比如我们平时执行case的时候,一通跑完可能会出现不少失败的case,那通常我可能就会翻控制台的输出来找出哪些case失败了。
但是控制台里输出的信息有很多,于是乎我想直接把测试失败的case信息存到一个本地文件里,我直接打开就可以看到所有失败的case。
先写一个case文件里的建议测试用例:
# content of mytest/tests.py
def test_failed():
assert False
def test_passed():
assert True
def test_failed2():
assert False
然后再同级目录下创建一个conftest文件,之前聊fixture时候就说过,conftest里的内容就是本地插件了。
先直接放上插件代码:
# content of mytest/conftest.py
import pytest
from pathlib import Path
from _pytest.main import Session
from _pytest.nodes import Item
from _pytest.runner import CallInfo
from _pytest.terminal import TerminalReporter
FAILURES_FILE = Path() / "failures.txt"
@pytest.hookimpl()
def pytest_sessionstart(session: Session):
print("Hello 把苹果咬哭")
if FAILURES_FILE.exists():
FAILURES_FILE.unlink()
FAILURES_FILE.touch()
@pytest.hookimpl(hookwrapper=True)
def pytest_runtest_makereport(item: Item, call: CallInfo):
outcome = yield
result = outcome.get_result()
if result.when == "call" and result.failed:
try:
with open(str(FAILURES_FILE), "a") as f:
f.write(result.nodeid + "\n")
except Exception as e:
print("ERROR", e)
pass
解析
1. 重写钩子函数
首先,关于pathlib模块就是用来做一些路径操作的库,因为我要在本地路径中进行文件相关操作。
def pytest_sessionstart()中做的事情就是先看下本地是否存在这个名字叫failures.txt的文件,有的话就删除,没有就新建。
为啥用pytest_sessionstart这个hook函数,因为通过查看官方API文档里的介绍,发现这个钩子函数是在创建Session对象之后,且在执行收集和进入运行测试循环之前调用,所以很适合用在这里。
所以直接重写这个hook函数来实现我们定义的功能。
2. hook函数中的 firstresult
示例中使用hook函数pytest_runtest_makereport,同样通过查看官方API介绍,它的作用是为测试用例的每个setup、运行和tearDown阶段创建TestReport。而插件要做的事情,就是要在
用例执行后获取到状态,若是失败就存放到本地txt文件。
当查看hook规范时候,发现一个装饰器参数firstresult=True。
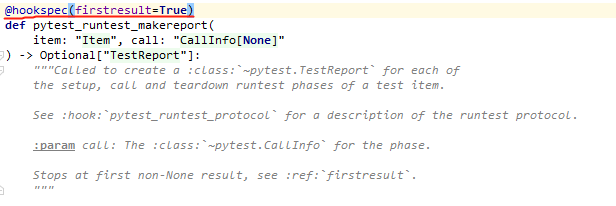
由于在大多数情况下,调用hook函数可能还会触发调用多个hook,所以最后的结果会是包含所调用钩子函数的非none结果。
当firstresult=True时,调用钩子函数时只要有第一个返回非none结果,就会将该结果作为整个钩子调用的结果。在这种情况下,将不会调用其余钩子函数。
3. hook函数中的 hookwrapper
回到插件代码本身,也用到了一个参数hookwrapper=True。

默认情况下,我们之间重写hook函数来彻底改变它要做的事情,就像插件代码里第一个hook函数pytest_sessionstart一样。
当hookwrapper=True时,等于是我们实现了一个hook函数的包装器。钩子包装器是一个生成器函数,它只产生一次。
当 pytest 调用钩子时,首先执行钩子包装器,并像常规钩子一样传递相同的参数。
yield关键字大家都熟悉了,当代码执行到这里的时候会暂停一下,继续执行下一个钩子,并且会把所有的结果或者异常封装成一个result对象返回到yield这里。
钩子包装器本身并不返回结果,只是在实际的钩子实现的外面做一些其他的事情。
我们的插件功能其实也并不是要修改这个钩子本身测试报告的内容,所以就直接通过hookwrapper=True将我们的pytest_runtest_makereport写成一个包装好的钩子。
接下来就是具体功能的代码,判断当用例测试结果是fail,就写到本地文件中。
运行
运行一下测试用例,看下我们插件的执行情况。
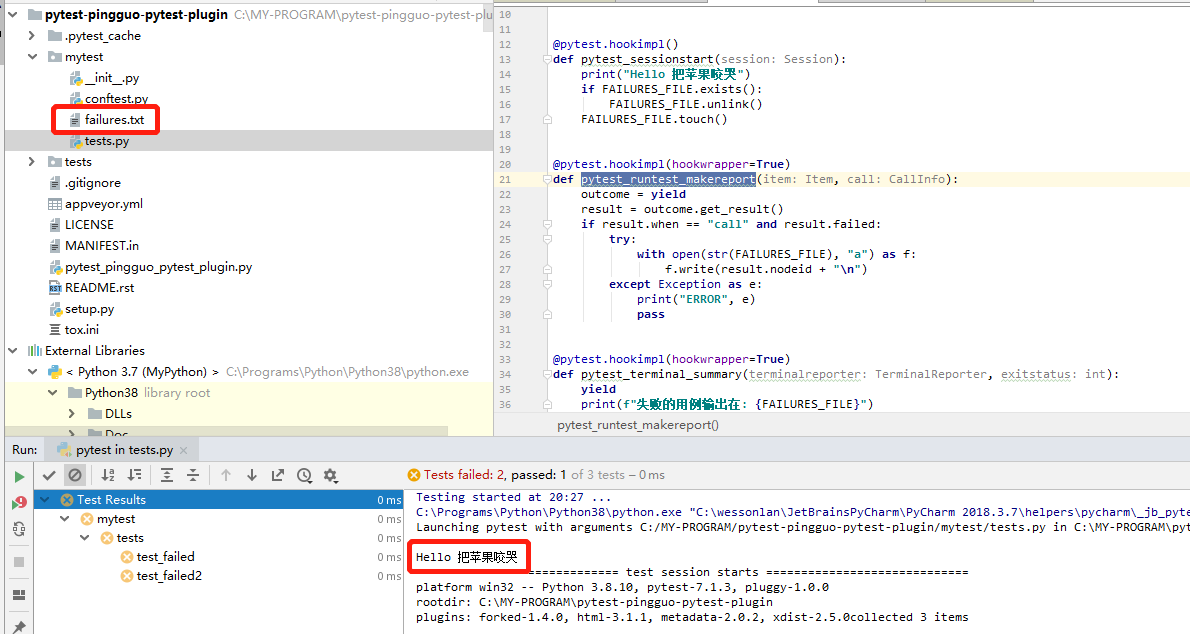
查看下failures.txt内容,结果正确。

四、钩子函数排序/调用示例
存在这样的情况,对于同一个钩子规范,可能会存在多个实现。这种情况下可以使用参数tryfirst和trylast来影响钩子的调用顺序。
# Plugin 1
@pytest.hookimpl(tryfirst=True)
def pytest_collection_modifyitems(items):
# 尽可能早的执行
...
# Plugin 2
@pytest.hookimpl(trylast=True)
def pytest_collection_modifyitems(items):
# 尽可能晚的执行
...
# Plugin 3
@pytest.hookimpl(hookwrapper=True)
def pytest_collection_modifyitems(items):
# 会在上面的 tryfirst 之前执行
outcome = yield
# 在执行所有非钩子包装器之后执行
具体执行顺序如下:
Plugin3的pytest_collection_modifyitems一直调用到yield,因为它是一个钩子包装器。Plugin1的pytest_collection_modifyitems被调用,因为它被标记为tryfirst=True。Plugin2的pytest_collection_modifyitems被调用,因为它被标记为trylast=True(但即使没有这个标记,它也会在Plugin1之后)。Plugin3的pytest_collection_modifyitems继续在yield执行代码,yield接收一个Result实例。
关于hook本篇先到此,剩下的内容另起篇幅了。
最后,闻道有先后,文章有遗漏,欢迎交流。
【pytest官方文档】解读- 插件开发之hooks 函数(钩子)的更多相关文章
- 【pytest官方文档】解读fixtures - 1.什么是fixtures
在深入了解fixture之前,让我们先看看什么是测试. 一.测试的构成 其实说白了,测试就是在特定的环境.特定的场景下.执行特定的行为,然后确认结果与期望的是否一致. 就拿最常见的登录来说,完成一次正 ...
- 【pytest官方文档】解读fixtures - 2. fixtures的调用方式
既然fixtures是给执行测试做准备工作的,那么pytest如何知道哪些测试函数 或者 fixtures要用到哪一个fixtures呢? 说白了,就是fixtures的调用. 一.测试函数声明传参请 ...
- 【pytest官方文档】解读fixtures - 3. fixtures调用别的fixtures、以及fixture的复用性
pytest最大的优点之一就是它非常灵活. 它可以将复杂的测试需求简化为更简单和有组织的函数,然后这些函数可以根据自身的需求去依赖别的函数. fixtures可以调用别的fixtures正是灵活性的体 ...
- Cuda 9.2 CuDnn7.0 官方文档解读
目录 Cuda 9.2 CuDnn7.0 官方文档解读 准备工作(下载) 显卡驱动重装 CUDA安装 系统要求 处理之前安装的cuda文件 下载的deb安装过程 下载的runfile的安装过程 安装完 ...
- 【pytest官方文档】解读- 开发可pip安装的第三方插件
在上一篇的 hooks 函数分享中,开发了一个本地插件示例,其实已经算是在编写插件了.今天继续跟着官方文档学习更多知识点. 一个插件包含一个或多个钩子函数,pytest 正是通过调用各种钩子组成的插件 ...
- 【pytest官方文档】解读fixtures - 8. yield和addfinalizer的区别(填坑)
在上一章中,文末留下了一个坑待填补,疑问是这样的: 目前从官方文档中看到的是 We have to be careful though, because pytest will run that fi ...
- 【pytest官方文档】解读fixtures - 7. Teardown处理,yield和addfinalizer
当我们运行测试函数时,我们希望确保测试函数在运行结束后,可以自己清理掉对环境的影响. 这样的话,它们就不会干扰任何其他的测试函数,更不会日积月累的留下越来越多的测试数据. 用过unittest的朋友相 ...
- 【pytest官方文档】解读fixtures - 10. fixture有效性、跨文件共享fixtures
一.fixture有效性 fixture有效性,说白了就是fixture函数只有在它定义的使用范围内,才可以被请求到.比如,在类里面定义了一个fixture, 那么就只能是这个类中的测试函数才可以请求 ...
- FluentValidation:C#后端输入验证框架的官方文档解读
参照 FluentValidation 的官方文档写的例子,方便日后查看和使用. 原文:https://github.com/JeremySkinner/FluentValidation/wiki H ...
随机推荐
- CSS3 基础学习
CSS基础学习 当前进度[P78] 参考资料 视频链接:https://www.bilibili.com/video/BV14J4114768 菜鸟教程:https://www.runoob.com/ ...
- 100行代码实现一个RISC-V架构下的多线程管理框架
1. 摘要 本文将基于RISC-V架构和qemu仿真器实现一个简单的多线程调度和管理框架, 旨在通过简单的代码阐明如何实现线程的上下文保存和切换, 线程的调度并非本文的重点, 故线程调度模块只是简单地 ...
- java-注释、API之字符串(String)
/** * 文档注释只定义在三个地方 : 类.常量.方法上 * 在类上定义文档注释用来说这个类设计及其解决问题等相关描述信息 * @author 作者 * @version 1.0 21/08/17 ...
- MybatisPlus核心功能——实现CRUD增删改查操作 (包含条件构造器)
CRUD 官方文档:https://baomidou.com/ (建议多看看官方文档,每种功能里面都有讲解)[本文章使用的mybatisplus版本为3.5.2] 条件构造器 一般都是用service ...
- [NOI P模拟赛] 传统艺能(子序列自动机、矩阵乘法,线段树)
(2:00)OID:"完了,蓝屏了!"(代码全消失) 众人欢呼 OID:开机,"原题测试--" (30min later)OID 开始传统艺能: " ...
- 牛客IOI周赛26-提高组 A. 逆序对
题面 逆序对 有一个长度为 N \tt N N 的排列 a a a,进行 M \tt M M 次操作,操作有 4 \tt 4 4 种: 1 l r :交换 a l \tt a_l al 和 a r ...
- 「题解报告」SP16185 Mining your own business
题解 SP16185 Mining your own business 原题传送门 题意 给你一个无向图,求至少安装多少个太平井,才能使不管那个点封闭,其他点都可以与有太平井的点联通. 题解 其他题解 ...
- Linux面试题 系统启动流程
BIOS:基本输入输出系统,帮助我们初始化硬件 硬盘分区有两类:MBR和GPT ; MBR单块硬盘不能大于2T,主分区的数量不能超过4个:MBR方案存储在第一个扇区的前446个字节(共512字节,后面 ...
- torch.sort 和 torch.argsort
定义 torch.sort(input,dim,descending) torch.argsort(input,dim,descending) 用法 torch.sort:对输入数据排序,返回两个值, ...
- Django 之视图层
JsonResponse 1 json格式的数据有什么用 前后端数据交互需要使用json作为过渡,实现跨语言传输数据 2 前后端方法对应 JSON.stringify() - json.dumps( ...