记一次grpc server内存/吞吐量优化
背景
最近,上线的采集器忽然时有OOM。采集器本质上是一个grpc服务,网络设备通过grpc协议将数据上报后,采集器进行格式等整理后,发往下一个系统(比如分析,存储)。
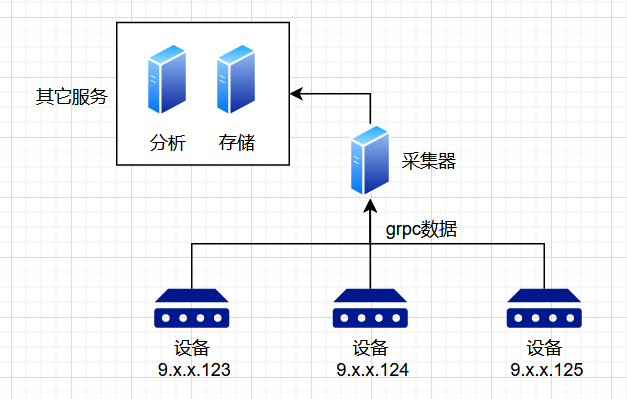
打开运行环境,发现特性如下:
- 每个采集器实例,会有数千个设备相连。并且会建立一个双向 grpc stream,用以上报数据。
- cpu的负载并不高,但内存居高不下。
初步猜想,内存和stream的数量相关,下面来验证一下。
优化内存
这次,很有先见之明的在上线就部署了pprof。这成为了线上debug的关键所在。
import _ "net/http/pprof"
go func() {
logrus.Errorln(http.ListenAndServe(":6060", nil))
}()
先看协程
一般内存问题会和协程泄露有关,所以先抓一下协程:
go tool pprof http://localhost:6060/debug/pprof/goroutine
得到了抓包的文件 /root/pprof/pprof.grpc_proxy.goroutine.001.pb.gz,为了方便看,scp到本机。
在本地执行:
go tool pprof -http=0.0.0.0:8080 ./pprof.grpc_proxy.goroutine.001.pb.gz
如果报错没有graphviz,安装之:
yum install graphviz
此时进入浏览器输入http://127.0.0.1:8080/ui/,会有一个很好看的页面。
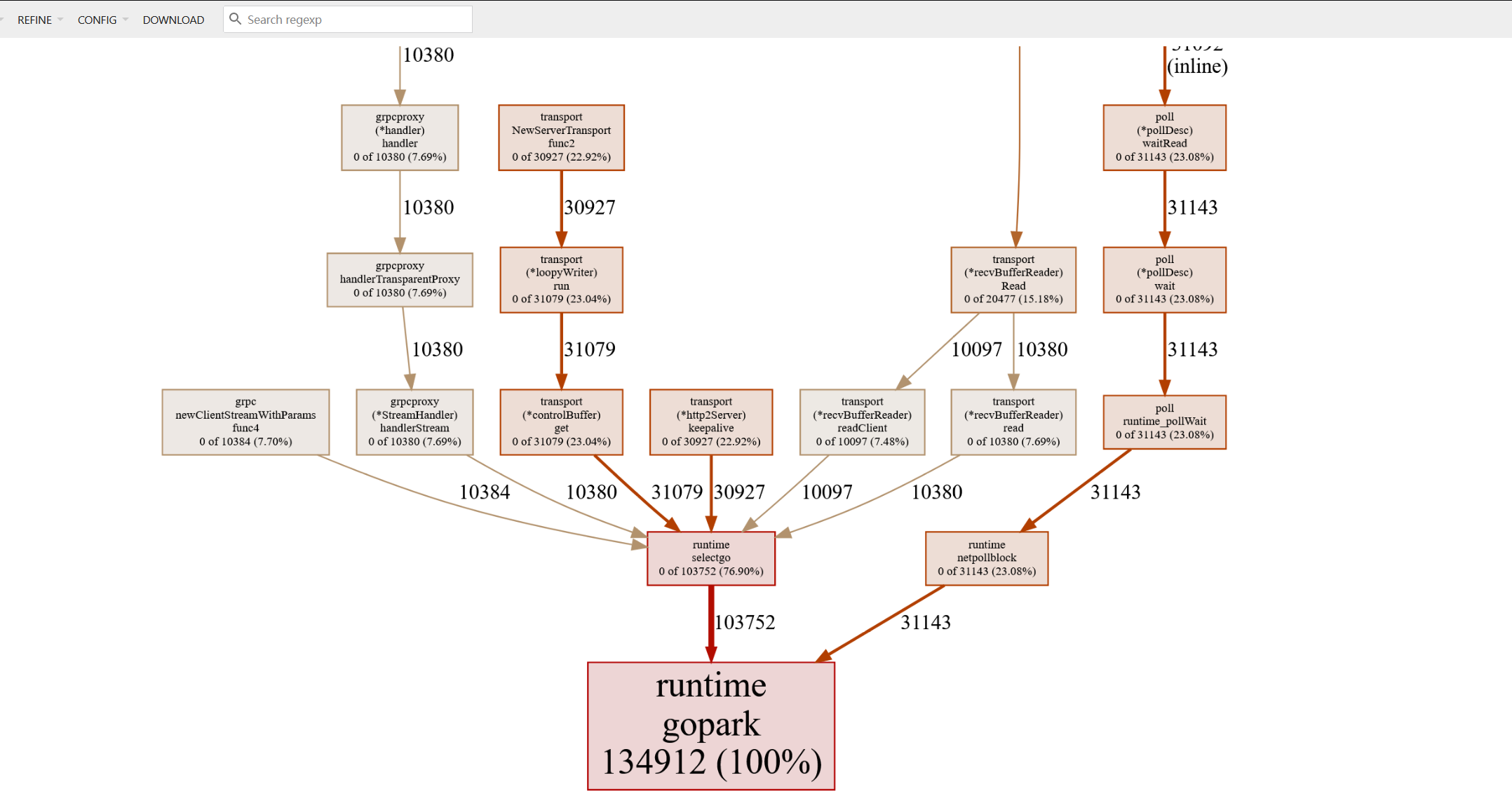
在这里,会发现有13W个协程。有点多,但考虑到连接了10000多个设备。
- 这些协程,有keepalive, 有收发包等协程。都挺正常,其实问题不大。
- 几乎所有的协程都gopark了。在等待。这也解释了为什么cpu其实不高,因为设备连上了但是不上报数据。占着资源不XX。
再看内存
协程虽然多,但没看出什么有价值的东西。那么再看看内存的占用。这次换个命令:
go tool pprof -inuse_space http://127.0.0.1:6060/debug/pprof/heap
-inuse_space 代表观察使用中的内存
继续得到数据文件,然后scp到本机执行:
go tool pprof -http=0.0.0.0:8080 ./pprof.grpc_proxy.alloc_objects.alloc_space.inuse_objects.inuse_space.003.pb.gz
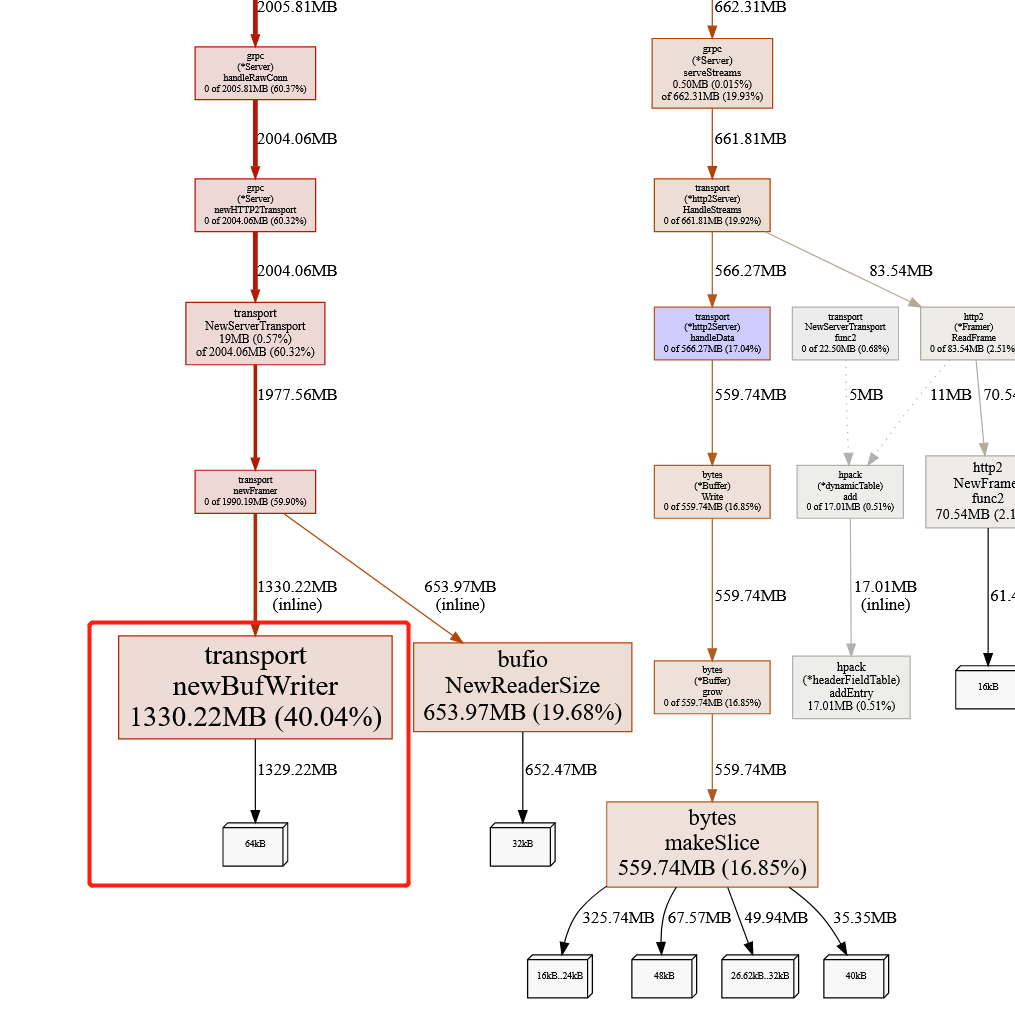
发现grpc.Serve.func3 ->...-> newBufWriter占用了大量内存。
问题很明显,是buf的配置不太合适。
这里多提一句,grpc服务端内存暴涨一般有这几个原因:
- 没有设置keepalive,使得连接泄露
- 服务端处理能力不足,流程阻塞,这个一般是下一跳IO引起。
- buffer使用了默认配置。
ReadBufferSize和WriteBufferSize默认为每个stream配置了32KB的大小。如果连接了很多设备,但其实cpu开销并不大,可以考虑减少这个值。
修改后代码添加grpc.ReadBufferSize(1024*8)/grpc.WriteBufferSize(1024*8)配置
var keepAliveArgs = keepalive.ServerParameters{
Time: 10 * time.Second,
Timeout: 15 * time.Second,
MaxConnectionIdle: 3 * time.Minute,
}
s := grpc.NewServer(
.......
grpc.KeepaliveParams(keepAliveArgs),
grpc.MaxSendMsgSize(1024*1024*8), // 最大消息8M
grpc.MaxRecvMsgSize(1024*1024*8),
grpc.ReadBufferSize(1024*8), // 就是这两个参数
grpc.WriteBufferSize(1024*8),
)
if err := s.Serve(lis); err != nil {
logger.Errorf("failed to serve: %v", err)
return
}
重新发布程序,发现内存占用变成了原来的一半。内存占用大的问题基本解决。
注意:减少buffer代表存取数据的频次会增加。理论上会带来更大的cpu开销。这也符合优化之道在于,CPU占用大就(增加buffer)用内存换,内存占用大就(减少buffer)用cpu换。水多了加面,面多了加水。如果cpu和内存都占用大,那就到了买新机器的时候了。
优化吞吐
在优化内存的时候,顺便看了一眼之前不怎么关注的缓冲队列监控。惊掉下巴。居然有1/4的数据使用到了缓冲队列来发送。这势必大量的使用了低速的磁盘。
这里简单提一下架构。
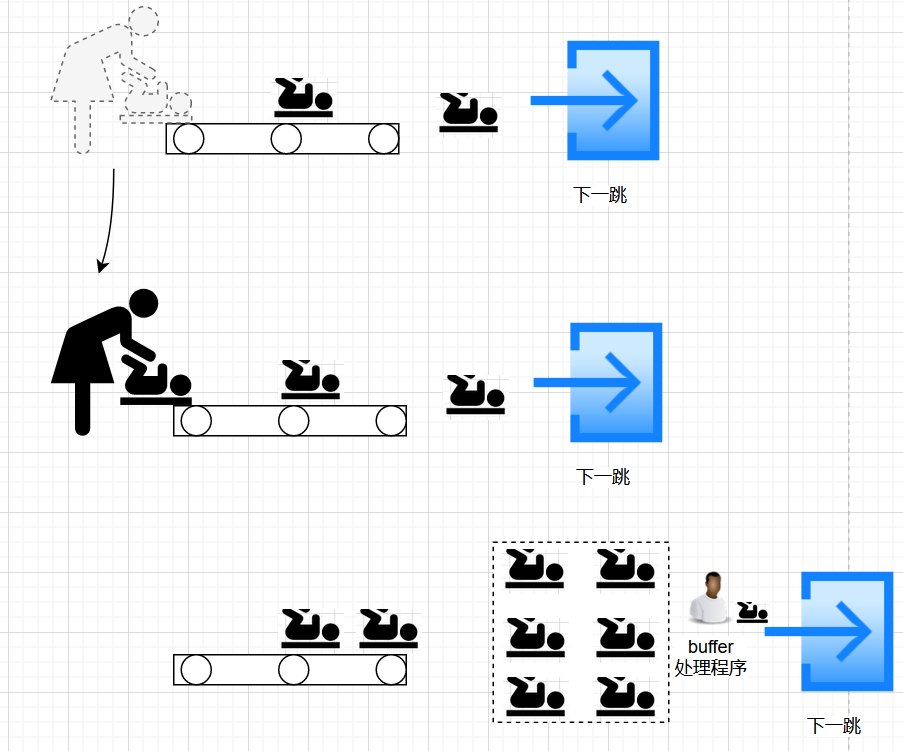
- 服务在收到数据之后并处理后,有多个下一跳(ai分析,存储等微服务)等着发送数据。
- 服务使用roundrobin的方式进行下一跳的选取
- 当下一跳繁忙的时候,则将数据写入到buffer中,buffer是一个磁盘队列。并且有另一个线程负责消费buffer中的数据。
简单用代码来表示就是:
func SendData(data *Data){
i+=1
targetStream:= streams[i%len(streams)]
select{
case targetStream.c<- data:
//写入成功
case <-time.After(time.Millisecond*50):
bufferStream.c<-data // 超时,写入失败,写到磁盘缓存队列中,等待容错程序处理
}
}
这种比较通用的玩法有几个硬伤
- 当某个下一跳stream的延时比较高的时候,就会引发大量的阻塞。从而使得大量的数据用到缓存。
time.After里的超时时间设成什么,很让人头痛。如果设得太大,虽然减少了缓冲的使用率,但增加了数据的延时。
思考了一下,能不能利用go的机制,从之前的轮循发送,换成哪个stream快就往谁发。
于是,我把代码写成了这样,调用Send的时候,将数据发到baseCh,同时,将baseCh让后台所有的stream同时读取数据,这样哪个stream空闲都会立刻从baseCh取数据发往下一跳:
// 引入baseCh,所有的数据先发到这
baseCh:= make(chan *Data)
// 为每个下一跳的stream建立一个协程,用来发送数据
for _,stream := range streams{
stream:=stream
// 在stream实现中使用一个独立的协程管理本stream的发送,所有的stream都共用这一个入口
// 同时从这一个入口ch取数据
stream.SendCh = bashCh
}
func Send(data *Data){
select{
case bashCh<-data:
case <-time.After(time.Millisecond*50):
buffer.Send(data)
}
}
同时,stream的实现如下:
func (s *MyStream) newGrpcStream(methodName string, addr string) error {
// 创建客户端,把本地消息发到后端上
// ......
stream, err := grpc.NewClientStream(s.ctx,
clientStreamDescForProxying,
conn, methodName)
if err != nil {
logrus.Errorf("create stream addr:%v failed, %v", addr, err)
return err
}
// ......
go func() {
// 后端唯一的closeSend,都收到这里
defer stream.CloseSend()
for {
select {
// 关键所在,所有的stream共用同一个SendCh,这就是上一级的baseCh
case msg := <-s.SendCh:
f := msg.Msg
// 源源不断把数据从客户端发向后端
err := stream.SendMsg(f)
if err != nil {
logrus.Errorf("stream will resend msg and close, addr:%v, err:%v", addr, err)
// 如果这条消息发送失败,就调用失败回调
msg.ErrCallBack(msg.Msg, msg.Ttime)
return
}
case <-s.ctx.Done():
return
}
}
}()
return nil
}
这相当于引入一个baseCh,把Send函数改造成了一进多出的模式。从而不会让一个stream的阻塞频繁的卡住所有数据的发送。让所有的数据发送被归集到baseCh,而不是每次发送都等待超时。
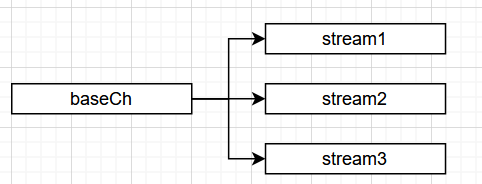
在做这一个改动时,有一点顾虑:
chan本质上是一个有锁队列,频繁的加锁会不会反而影响吞吐?
这里需要指出,bashCh使用的是无缓冲channel。理论上,无缓冲channel的性能会优于有缓冲的channel,因为不需要管理内置的队列。这在一些测评中有所体现。
实践是检验真理的唯一标准,立马上线灰度,发现多虑了。10000个写入端频繁调用Send函数时,系统资源并没有太大的波动。反而磁盘缓冲的使用大大减少了。数据的超时数维持在原有水平(因为卡的stream还是会卡),但它不会再影响都其它的数据,使之写入缓存。
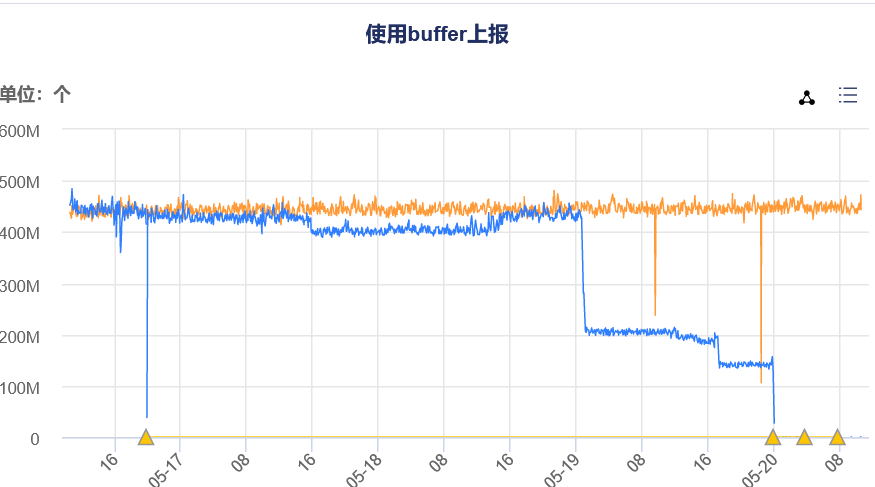
分批灰度变更,使得磁盘缓冲现在的使用几乎归零。
当看到监控图后,我激动的哇的一声哭出来,心里比吃了蜜还甜,感到自己的技术又精甚了不少。胸口的红领巾更红了。
记一次grpc server内存/吞吐量优化的更多相关文章
- 使用SQL Server内存优化表 In-Memory OLTP
如果你的系统有高并发的要求,可以尝试使用SQL Server内存优化表来提升你的系统性能.你甚至可以把它当作Redis来使用. 要使用内存优化表,首先要在现在数据库中添加一个支持内存优化的文件组. M ...
- SQL Server 内存中OLTP内部机制概述(三)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- mysql大内存高性能优化方案
mysql优化是一个相对来说比较重要的事情了,特别像对mysql读写比较多的网站就显得非常重要了,下面我们来介绍mysql大内存高性能优化方案 8G内存下MySQL的优化 按照下面的设置试试看:key ...
- (4.11)sql server内存使用
一些内存使用错误理解 开篇小感悟 在实际的场景中会遇到各种奇怪的问题,为什么会感觉到奇怪,因为没有理论支撑的东西才感觉到奇怪,SQL Server自己管理内存,我们可以干预的方式也很少,所以日常很 ...
- SQL Server内存理解的误区
SQL Server内存理解 内存的读写速度要远远大于磁盘,对于数据库而言,会充分利用内存的这种优势,将数据尽可能多地从磁盘缓存到内存中,从而使数据库可以直接从内存中读写数据,减少对机械磁盘的IO请求 ...
- SQL Server 内存中OLTP内部机制概述(四)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(一)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- android app性能优化大汇总(内存性能优化)
转载请注明本文出自大苞米的博客(http://blog.csdn.net/a396901990),谢谢支持! 写在最前: 本文的思路主要借鉴了2014年AnDevCon开发者大会的一个演讲PPT,加上 ...
随机推荐
- Linux磁盘之inode
什么是 inode ? 文件储存在硬盘上,硬盘的最小存储单位叫作"扇区"(Sector).每一个扇区储存512字节(至关于0.5KB).操作系统读取硬盘的时候,不会一个个扇区地读取 ...
- 4.Docker容器学习之Dockerfile入门到放弃
原文地址: 点击直达 0x01 Dockerfile 编写 描述:Dockerfile是一个文本格式的配置文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内 ...
- Go xmas2020 学习笔记 08、Functions, Parameters & Defer
08-Functions, Parameters. functions. first class. function signatures. parameter. pass by value. pas ...
- VulnHub-Earth 打靶记录
目录 VulnHub-Earth 打靶记录 知识点 目标探测 信息收集 Shell反弹&信息二次收集 提权 权限维持 VulnHub-Earth 打靶记录 搭建靶场的时候一定要使用NATser ...
- Day 005:PAT练习--1047. 编程团体赛(20)
编程团体赛的规则为:每个参赛队由若干队员组成:所有队员独立比赛:参赛队的成绩为所有队员的成绩和:成绩最高的队获胜.现给定所有队员的比赛成绩,请你编写程序找出冠军队. 输入格式: 输入第一行给出一个正整 ...
- 广度优先搜索 BFS 学习笔记
广度优先搜索 BFS 学习笔记 引入 广搜是图论中的基础算法之一,属于一种盲目搜寻方法. 广搜需要使用队列来实现,分以下几步: 将起点插入队尾: 取队首 \(u\),如果 $u\to v $ 有一条路 ...
- 如何在同一Linux服务器上创建多站点
在没有域名的情况下,怎样才能创建出多站点访问?这个问题困扰我许久,之后阅读了<http权威指南>,这本让我恍然大悟.这里说明了从浏览器如何解析域名,再请求服务器,服务器收到请求后是如何处理 ...
- Go 语言快速开发入门
目录 需求 开发的步骤 linux下如何开发Go程序 MAC下如何开发Go程序 Golang执行流程分析 编译和运行说明 Go程序开发的注意事项 Go语言的转义字符(escapechar) Golan ...
- JS 一些概念
JS 内存机制 基本类型: String | Boolean | Undefined | Number | Nll | Symbol 数据保存在"栈"--先进后出. 数据类型: A ...
- Spring 源码(13)Spring Bean 的创建过程(4)
Spring Bean的创建过程非常的复杂,上一篇重点介绍了Spring在创建Bean的过程中,使用InstantiationBeanPostProcessor进行提前创建Bean,我们可以通过CGL ...