单链表上的一系列操作(基于c语言)
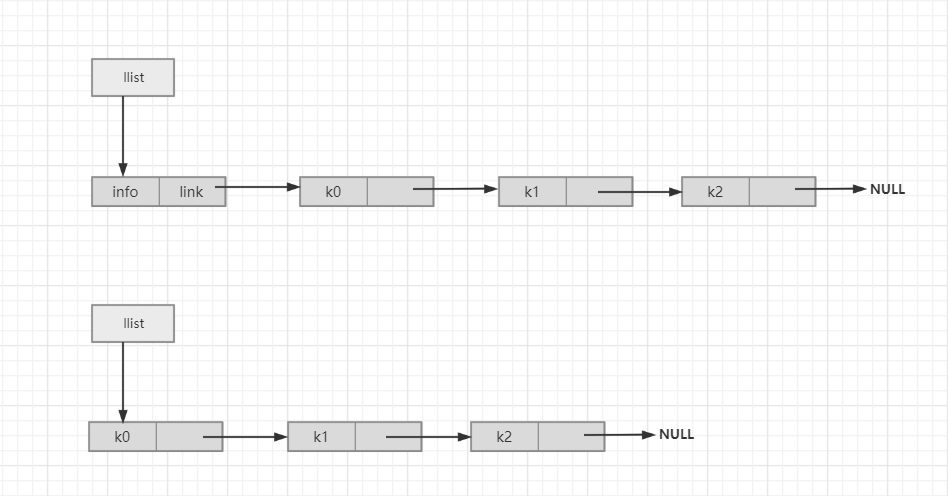
单链表的实现分为两种单链表(其实差别并不是很大):带头结点和不带头结点,分别对应下面图中的上下两种。
链表的每一个结点是由两个域组成:数据域和指针域,分别存放所含数据和下一个结点的地址(这都是很明白的东西)
图中的东西可以分为三种:头指针llist;头节点info;正常的节点ki
下面定义结点的类型和单链表的类型:
struct Node;
typedef struct Node * PNode;
struct Node{
DataType info;
PNode link;
};
typedef struct Node * LinkList;
//很明显我们定义的结点指针类型和单链表的类型实际上是一样的东西
//后续的代码暂时与书上的内容保持一致,均使用有头结点的链表
//总结过后再将不带头结点的单链表实现补上
创建一个空链表:
LinkList creatNullList_link(void){
LinkList llist = (LinkList)malloc(sizeof(struct Node)); //创建一个指向Node类型的指针llist
if(llist != NULL) llist->link = NULL; //将其指向为空,也就是链表末尾
else printf("OUTOFSPACE!");
return llist; //看上面的代码后可知,llist可能为空,所以后面其他的函数经常会先判断了llist的情况
}
是否是空链表:
int isNullList_link(LinkList llist){
return (llist->link == NULL);
}
//判断链表是否为空的代码比较简单
在链表中求第一个值为x的结点的存储位置:
PNode locate_link(LinkList llist,DataType x){
PNode p;
if (llist == NULL) return NULL;
p = llist->link;
while(p != NULL && p->info != x) p = p->link;
return p;
}
//为什么要判断llist是否为空而不是判断llist->link是否为空?
//如果llist为空,那使用llist->link不就是对一个空指针操作了吗,记得学指针的时候书上的一句话嘛,千万不要用没有初始化的指针,这里如果其指向为空,那llist->link也就不知道指向哪里
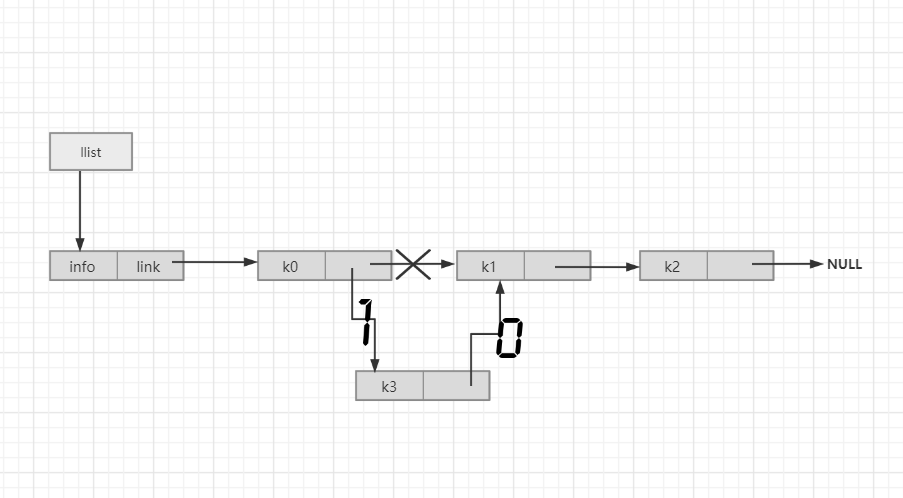
在p结点的后面插入一个值为x的新结点,返回是否插入成功的标志:
int insertPost_link(LinkList llist,PNode p,DataType x){
PNode q = (PNode)malloc(sizeof(struct Node));
if (q == NULL){
printf("OUTOFSPACE");
return 0;
}
q->info = x;
q->link = p->link;
p->link = q;
return 1;
}//下图为操作顺序,操作顺序不能反
//这一个方法是不需要用到llist
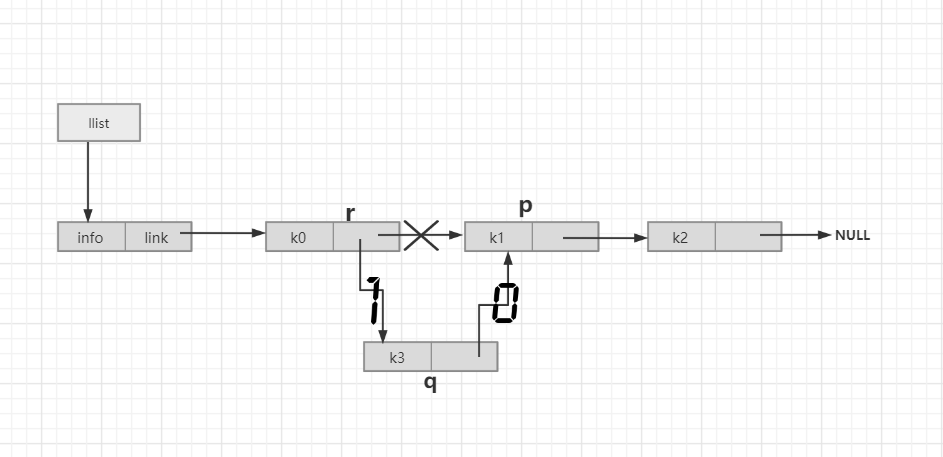
在p结点的前面插入值为x的新结点,返回插入成功与否的标志:
int insertPre_link(LinkList llist,PNode p,DataType x){
PNode r;
PNode q = (PNode)malloc(sizeof(struct Node));
if(q == NUll){
printf("OUTOFSPACE");
return 0;
}
r = locatePre_link(llist,p);
q->info = x;
q->link = r->link;
r->link = q;
reutrn 1;
}
//找p结点的前驱结点
PNode locatePre_link(LinkList llist,PNode p){
PNode p1;
if (llist == NULL) return NULL;
p1 = llist;
while(p1->link!=NULL && p1->link==p){
p1 = p1->link;
}
reutn p1;
}
//感觉这个难一点的就是前驱结点的查找,p1->link!=NULL && p1->link == p是这个找前驱结点的灵魂
删除第一个元素内容为x的结点,返回删除成功与否的标志:
int deleteV_link(LinkList llist,DataType x){
//不展示的方法:前面有一个定位方法,找到元素x的结点p,然后前面还有一个找前驱结点的方法,然后就可以执行删除操作了
//下面是书上的方法
PNode q,p;
p = llist;
if (p == NULL) return 0;
while(p->link!=NULL && p->link->info==x) p = p->link;
//p是要删除结点的前驱结点
if (p->link == NULL){
printf("NOT EXIST!");
return 0;
}
else{
q = p->link;
p->link = q->link;
//也可以是p->link = p->link->link
free(q);
return 1;
}
}
目前这基本上是书本上的代码示例了,后续会补充未给出的思考题,并且给出没有头结点时上述函数方法。
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
单链表上的一系列操作(基于c语言)的更多相关文章
- C++学习---单链表的构建及操作
#include <iostream> using namespace std; typedef struct LinkNode { int elem;//节点中的数据 struct Li ...
- C++单链表的创建与操作
链表是一种动态数据结构,他的特点是用一组任意的存储单元(可以是连续的,也可以是不连续的)存放数据元素.链表中每一个元素成为“结点”,每一个结点都是由数据域和指针域组成的,每个结点中的指针域指向下一个结 ...
- 单链表的插入删除操作(c++实现)
下列代码实现的是单链表的按序插入.链表元素的删除.链表的输出 // mylink.h 代码 #ifndef MYLINK_H #define MYLINK_H #include<iostream ...
- 循环单链表定义初始化及创建(C语言)
#include <stdio.h> #include <stdlib.h> /** * 含头节点循环单链表定义,初始化 及创建 */ #define OK 1; #defin ...
- c++学习之单链表以及常用的操作
新学数据结构,上我写的代码. #include <iostream> #include <cstdlib> using namespace std; typedef int E ...
- 单链表无head各种操作及操作实验
#encoding=utf-8 class ListNode: def __init__(self,x): self.val=x; self.next=None; #链表逆序 def revers ...
- C++ 单链表操作总结
第一.单链表的定义和操作 #include <iostream> using namespace std; template <typename T> struct Node ...
- 数据结构(一) 单链表的实现-JAVA
数据结构还是很重要的,就算不是那种很牛逼的,但起码得知道基础的东西,这一系列就算是复习一下以前学过的数据结构和填补自己在这一块的知识的空缺.加油.珍惜校园中自由学习的时光.按照链表.栈.队列.排序.数 ...
- C++ "链链"不忘@必有回响之单链表
1. 前言 数组和链表是数据结构的基石,是逻辑上可描述.物理结构真实存在的具体数据结构.其它的数据结构往往在此基础上赋予不同的数据操作语义,如栈先进后出,队列先进先出-- 数组中的所有数据存储在一片连 ...
随机推荐
- 搭建golang开发环境(1.14之后版本)
Go语言1.14版本之后推荐使用go modules管理依赖,也不再需要把代码写在GOPATH目录下. 下载地址 Go官网下载地址:https://golang.org/dl/ Go官方镜像站(推荐) ...
- Solution -「CF 1375G」Tree Modification
\(\mathcal{Description}\) Link. 给定一棵 \(n\) 个结点的树,每次操作选择三个结点 \(a,b,c\),满足 \((a,b),(b,c)\in E\),并令 ...
- 编译安装 tree 命令
文章目录 下载源码包 编译源码包 tree下载地址:http://mama.indstate.edu/users/ice/tree/ Centos发行版,可以直接使用命令 yum -y install ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第02章 - 部署etcd集群
文章目录 1.2.部署etcd集群 1.2.0.下载etcd二进制文件 1.2.1.创建etcd证书和私钥 1.2.2.生成etcd证书和私钥 1.2.3.配置etcd为systemctl管理 1.2 ...
- Java基于ClassLoder/ InputStream 配合读取配置文件
阅读java开源框架源码或者自己开发系统时配置文件是一个不能忽略的,在阅读开源代码的过程中尝尝困惑配置文件是如何被读取到内存中的.配置文件本身只是为系统运行提供参数的支持,个人阅读源码时重点不大可能放 ...
- dw中几个必须掌握的快捷键
相信很多初学者,在使用软件制作网页的时候需要去软件操作界面点击按钮来实现编辑,现在给大家分享几个最常用到的快捷方式!这样能让大家在使用中更为方便,节约时间提高工作效率 加粗 Ctrl + B斜体 Ct ...
- node + express 搭建服务器,修改为自动重启服务器
1.使用express搭建一个项目,步骤如下(安装node步骤已省略) a.全局安装express-generator和express npm i express-generator -g npm i ...
- 小牟有趣的PWN
咳咳,主要是记一下最近学二进制然后工作室里面一个一起学pwn,然后遇到的一个比较好玩的题目. 一共呢,是两个文件,这也是最近学习pwn第一次做到两个文件的题目, 如果想要源文件,这边可以加我们的工作室 ...
- Vulhub-漏洞环境的搭建(详细版)
安装Vulhub需要的基础环境 更新现有的软件 复制代码 1 2 sudo apt-get update sudo apt-get upgrade 安装Docker 复制代码 1 2 3 4 5 6 ...
- CVE-2017-0213漏洞复现
CVE-2017-0213漏洞形成的原因 类型混淆的漏洞通常可以通过内存损坏的方式来进行利用.然而漏洞发现者在利用时,并未采用内存损坏的方式来进行漏洞利用.按照漏洞发现者的说法,内存损坏的利用方式需要 ...