【爬虫+数据分析+数据可视化】python数据分析全流程《2021胡润百富榜》榜单数据!
一、爬虫
1.1 爬取目标
本次爬取的目标是,2021年胡润百富榜的榜单数据:胡润百富 - 榜单
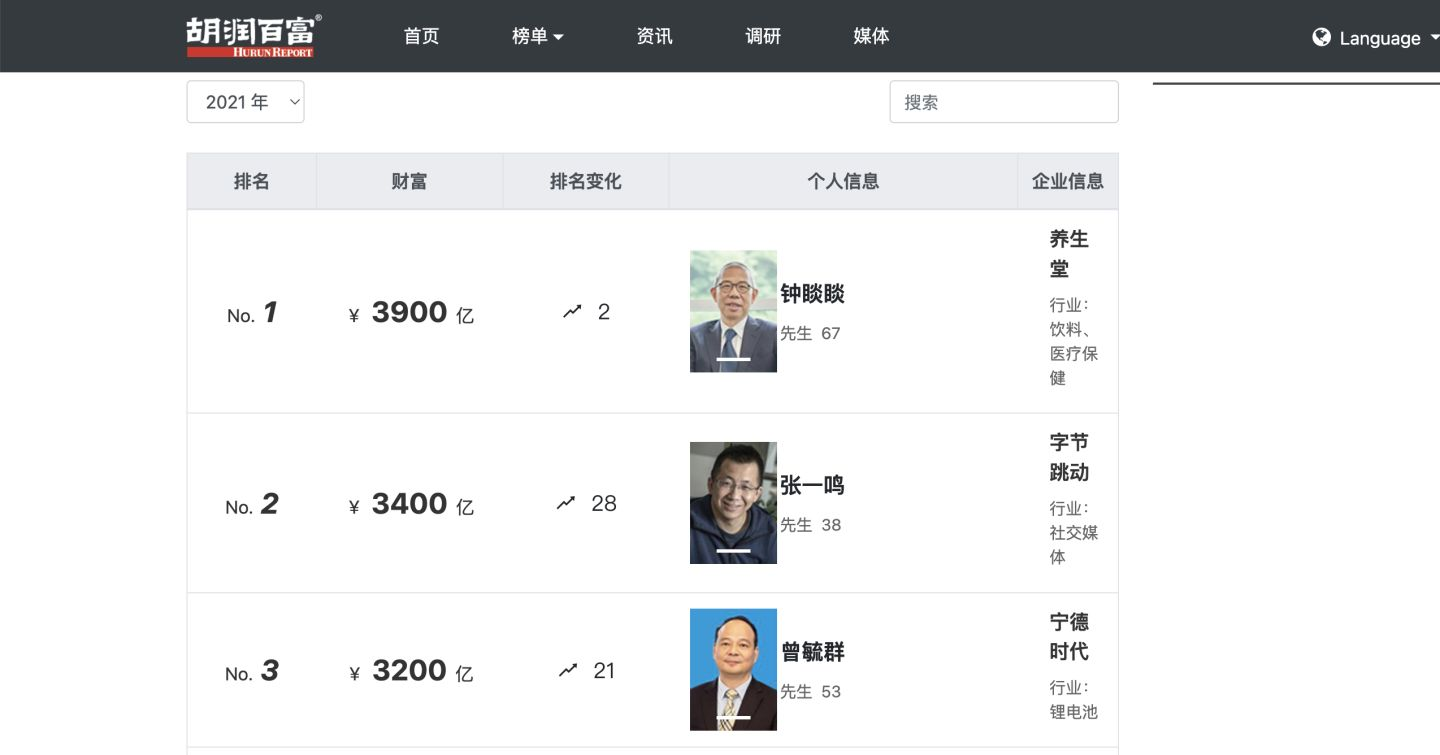
页面上能看到的信息有:
排名、财富值、排名变化、个人信息(姓名、性别、年龄)、企业信息(企业名称、所属行业)
页面结构很整齐,数据也很完整,非常适合爬虫和数据分析使用。
1.2 分析页面
老规矩,打开Chrome浏览器,按F12进入开发者模式,依次点击Network->Fetch/XHR,准备好捕获ajax请求。
重新刷新一下页面,发现一条请求:

在预览界面,看到一共20条(0~19)返回数据,正好对应页面上的20个富豪信息。
所以,后面编写爬虫代码,针对这个地址发送请求就可以了。
另外,关于翻页,我的个人习惯是,选择每页显示最多的数据量,这样能保证少翻页几次,少发送几次请求,防止被对端服务器反爬。
所以,每页选择200条数据:

再刷新一下页面,进行几次翻页,观察请求地址的变化规律:
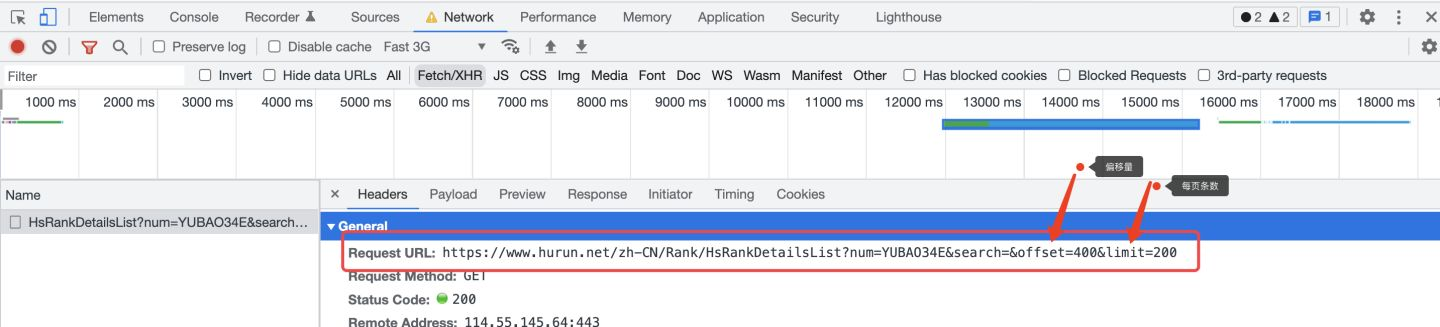
以翻到第3页为例,url中的offset(偏移量)为400,limit(每页的条数)为200,所以,可得出规律:
offset = (page - 1) * 200
limit = 200
下面开始编写爬虫代码。
1.3 爬虫代码
首先,导入需要用到的库:
import requests # 发送请求
import pandas as pd # 存入excel数据
from time import sleep # 等待间隔,防止反爬
import random # 随机等待
根据1.2章节分析得出的结论,编写逻辑代码,向页面发送请求:
# 循环请求1-15页
for page in range(1, 16):
# 胡润百富榜地址
sleep_seconds = random.uniform(1, 2)
print('开始等待{}秒'.format(sleep_seconds))
sleep(sleep_seconds)
print('开始爬取第{}页'.format(page))
offset = (page - 1) * 200
url = 'https://www.hurun.net/zh-CN/Rank/HsRankDetailsList?num=YUBAO34E&search=&offset={}&limit=200'.format(offset)
# 构造请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'accept-encoding': 'gzip, deflate, br',
'content-type': 'application/json',
'referer': 'https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=rich'
}
# 发送请求
r = requests.get(url, headers=headers)
用json格式解析返回的请求数据:(一行代码即可完成接收)
json_data = r.json()
由于解析的字段较多,这里不再赘述详细过程,字段信息包含:
Fullname_Cn_list = [] # 全名_中文
Fullname_En_list = [] # 全名_英文
Age_list = [] # 年龄
BirthPlace_Cn_list = [] # 出生地_中文
BirthPlace_En_list = [] # 出生地_英文
Gender_list = [] # 性别
Photo_list = [] # 照片
ComName_Cn_list = [] # 公司名称_中文
ComName_En_list = [] # 公司名称_英文
ComHeadquarters_Cn_list = [] # 公司总部地_中文
ComHeadquarters_En_list = [] # 公司总部地_英文
Industry_Cn_list = [] # 所在行业_中文
Industry_En_list = [] # 所在行业_英文
Ranking_list = [] # 排名
Ranking_Change_list = [] # 排名变化
Relations_list = [] # 组织结构
Wealth_list = [] # 财富值_人民币_亿
Wealth_Change_list = [] # 财富值变化
Wealth_USD_list = [] # 财富值_美元
Year_list = [] # 年份
最后,依然采用我最习惯的保存数据的方法,先拼装DataFrame数据:
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'排名': Ranking_list,
'排名变化': Ranking_Change_list,
'全名_中文': Fullname_Cn_list,
'全名_英文': Fullname_En_list,
'年龄': Age_list,
'出生地_中文': BirthPlace_Cn_list,
'出生地_英文': BirthPlace_En_list,
'性别': Gender_list,
'照片': Photo_list,
'公司名称_中文': ComName_Cn_list,
'公司名称_英文': ComName_En_list,
'公司总部地_中文': ComHeadquarters_Cn_list,
'公司总部地_英文': ComHeadquarters_En_list,
'所在行业_中文': Industry_Cn_list,
'所在行业_英文': Industry_En_list,
'组织结构': Relations_list,
'财富值_人民币_亿': Wealth_list,
'财富值变化': Wealth_Change_list,
'财富值_美元': Wealth_USD_list,
'年份': Year_list
}
)
再用pandas的to_csv方法保存:
# 保存结果数据
df.to_csv('2021胡润百富榜.csv', mode='a+', index=False, header=header, encoding='utf_8_sig')
注意,加上这个编码格式选项(utf_8_sig),否则产生乱码哦。
爬虫开发完成,下面展示结果数据。
1.4 结果数据
看一下榜单上TOP20的数据吧:
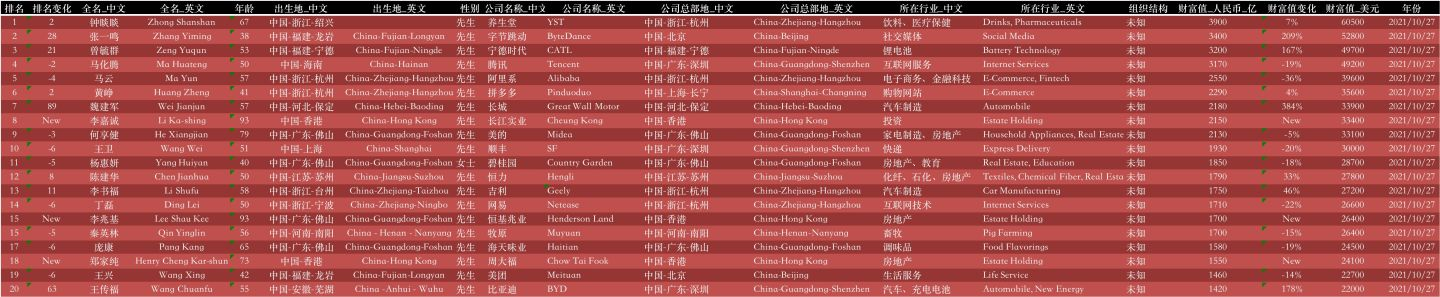
数据一共2916条,19个字段信息,含:
排名、排名变化、全名_中文、全名_英文、年龄、出生地_中文、出生地_英文、性别、公司名称_中文、公司名称_英文、公司总部地_中文、公司总部地_英文、所在行业_中文、所在行业_英文、组织结构、财富值_人民币_亿、财富值变化、 财富值_美元、年份。
数据信息还是很丰富的,希望能够挖掘出一些有价值的结论!
二、数据分析
2.1 导入库
首先,导入用于数据分析的库:
import pandas as pd # 读取csv文件
import matplotlib.pyplot as plt # 画图
from wordcloud import WordCloud # 词云图
增加一个配置项,用于解决matplotlib中文乱码的问题:
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
读取csv数据:
# 读取csv数据
df = pd.read_csv('2021胡润百富榜.csv')
2.2 数据概况
查看数据形状:

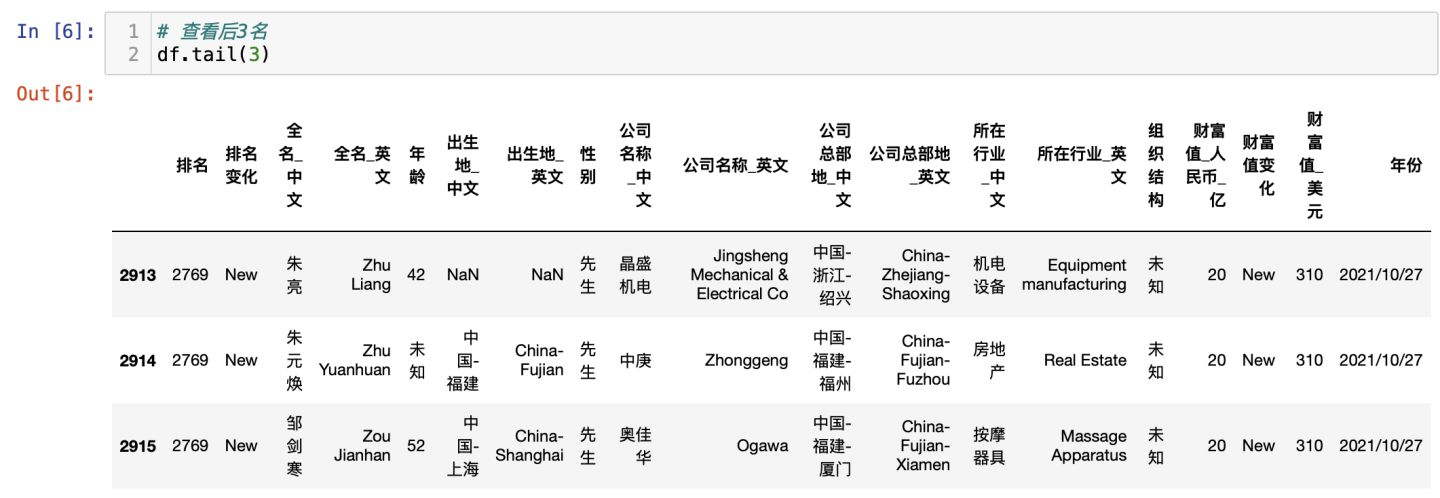
查看前3名富豪:

查看最后3名富豪:
描述性统计:

从描述性统计,可以得出结论:
从最大值3900亿、最小值20亿、方差242来看,分布很零散,各位富豪掌握的财富差距很大,马太效应明显。
2.3 可视化分析
2.3.1 财富分布
代码:
df_Wealth = df['财富值_人民币_亿']
# 绘图
df_Wealth.plot.hist(figsize=(18, 6), grid=True, title='财富分布-直方图')
# 保存图片
plt.savefig('财富分布-直方图.png')
可视化图:

结论:大部分的富豪的财富集中在20亿~400亿之间,个别顶级富豪的财富在3000亿以上。
2.3.2 年龄分布
代码:
# 剔除未知
df_Age = df[df.年龄 != '未知']
# 数据切割,8个分段
df_Age_cut = pd.cut(df_Age.年龄.astype(float), bins=[20, 30, 40, 50, 60, 70, 80, 90, 100])
# 画柱形图
df_Age_cut.value_counts().plot.bar(figsize=(16, 6), title='年龄分布-柱形图')
# 保存图片
plt.savefig('年龄分布-柱形图.png')
可视化图:
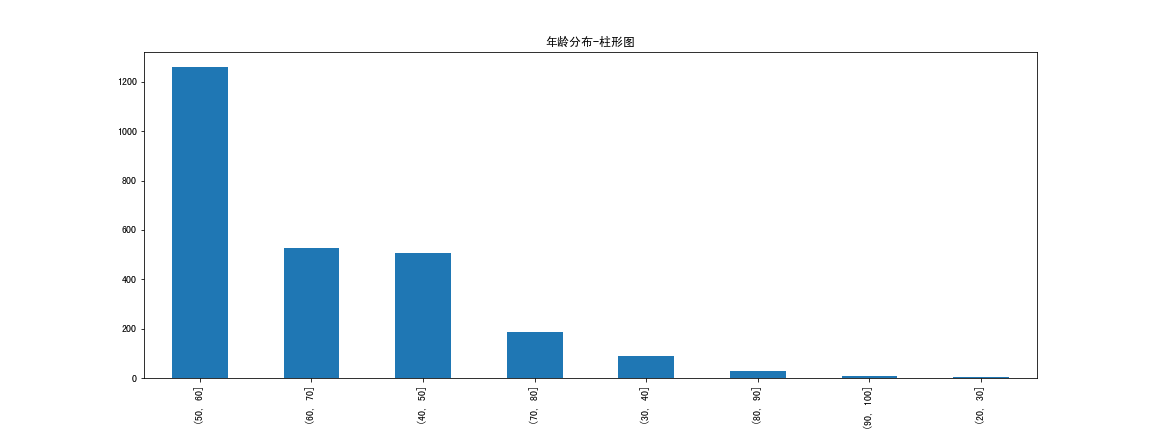
结论:大部分富豪的年龄在50-60岁,其次是60-70和40-50岁。极少数富豪在20-30岁(年轻有为)
2.3.3 公司总部分布
代码:
df_ComHeadquarters = df['公司总部地_中文'].value_counts()
# 绘图
df_ComHeadquarters.nlargest(n=30).plot.bar(
figsize=(16, 6), # 图片大小
grid=False, # 显示网格
title='公司总部分布TOP30-柱形图' # 图片标题
)
# 保存图片
plt.savefig('公司总部分布TOP30-柱形图.png')
可视化图:

结论:公司分布城市,大多集中在北上广深等一线城市,另外杭州、香港、苏州也位列前茅。
2.3.4 性别分布
代码:
df_Gender = df['性别'].value_counts()
# 绘图
df_Gender.plot.pie(
figsize=(8, 8), # 图片大小
legend=True, # 显示图例
autopct='%1.2f%%', # 百分比格式
title='性别占比分布-饼图', # 图片标题
)
# 保存图片
plt.savefig('性别占比分布-饼图.png')
可视化图:
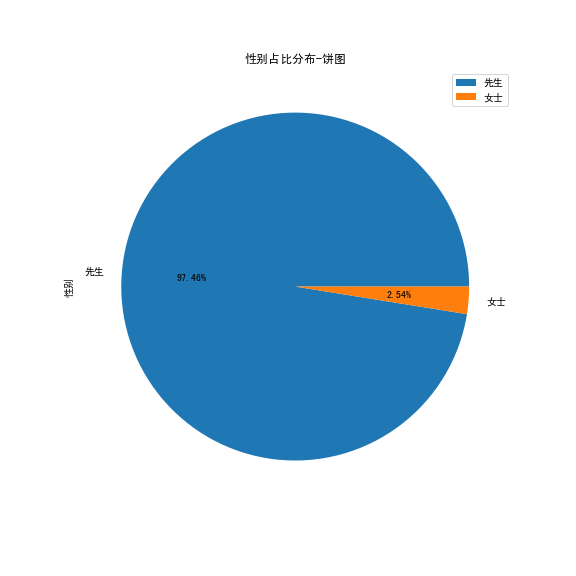
结论:男性富豪占据绝大多数,个别女性在列(巾帼不让须眉)
2.3.5 行业分布
代码:
df_Industry = df['所在行业_中文'].value_counts()
df_Industry.nlargest(n=20).plot.bar(
figsize=(18, 6), # 图片大小
grid=False, # 显示网格
title='行业分布TOP20-柱形图' # 图片标题
)
# 保存图片
plt.savefig('行业分布TOP20-柱形图.png')
可视化图:

结论:百富榜中占比最多的行业分别是:房地产、医药、投资、化工等。
2.3.6 组织结构分布
代码:
df_Relations = df['组织结构'].value_counts()
# 绘图
df_Relations.plot.pie(
figsize=(8, 8), # 图片大小
legend=True, # 显示图例
autopct='%1.2f%%', # 百分比格式
title='组织结构分布-饼图', # 图片标题
)
# 保存图片
plt.savefig('组织结构分布-饼图.png')
可视化图:

结论:半数以上是未知,企业未对外开放,或榜单没有统计到;家族和夫妇占据前两类。
2.3.7 公司名称词云图
代码:
ComName_list = df['公司名称_中文'].values.tolist()
ComName_str = ' '.join(ComName_list)
stopwords = [] # 停用词
# backgroud_Image = np.array(Image.open('幻灯片2.png')) # 读取背景图片
wc = WordCloud(
scale=3, # 清晰度
background_color="white", # 背景颜色
max_words=1000,#最大字符数
width=800, # 图宽
height=500, # 图高
font_path='/System/Library/Fonts/SimHei.ttf', # 字体文件路径,根据实际情况替换
stopwords=stopwords, # 停用词
# mask=backgroud_Image, # 背景图片
)
wc.generate_from_text(ComName_str) # 生成词云图
wc.to_file('2021胡润百富榜_公司名称_词云图.png') # 保存图片
wc.to_image() # 显示图片
可视化图:

结论:阿里系公司占据榜首,其次是海天味业等。
三、整体结论
综上所述,针对2021年胡润百富榜的榜单数据,得出如下结论:
财富分布:大部分的富豪的财富集中在20亿~400亿之间,个别顶级富豪的财富在3000亿以上。
年龄分布:大部分富豪的年龄在50-60岁,其次是60-70和40-50岁。极少数富豪在20-30岁(年轻有为)
城市分布:公司分布城市,大多集中在北上广深等一线城市,另外杭州、香港、苏州也位列前茅
性别分布:男性富豪占据绝大多数,个别女性在列(巾帼不让须眉)
行业分布:百富榜中占比最多的行业分别是:房地产、医药、投资、化工等
组织结构分布:半数以上是未知,企业未对外开放,或榜单没有统计到;家族和夫妇占据前两类。
公司名称分布:阿里系公司占据榜首,其次是海天味业等。
四、同步视频讲解
4.1 上集(爬虫讲解)
爬虫讲解视频:
https://www.zhihu.com/zvideo/1492523459087896577
4.2 下集(数据分析讲解)
可视化讲解视频:
https://www.zhihu.com/zvideo/1492525821340729344
五、附完整源码
完整源码:【爬虫+数据分析+数据可视化】python数据分析全流程《2021胡润百富榜》榜单数据!
【爬虫+数据分析+数据可视化】python数据分析全流程《2021胡润百富榜》榜单数据!的更多相关文章
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
- 从python爬虫以及数据可视化的角度来为大家呈现“227事件”后,肖战粉丝的数据图
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取t.cn ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- 【Python数据分析案例】python数据分析老番茄B站数据(pandas常用基础数据分析代码)
一.爬取老番茄B站数据 前几天开发了一个python爬虫脚本,成功爬取了B站李子柒的视频数据,共142个视频,17个字段,含: 视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕 ...
- python 爬虫与数据可视化--matplotlib模块应用
一.数据分析的目的(利用大数据量数据分析,帮助人们做出战略决策) 二.什么是matplotlib? matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB ...
- 数据分析 | 数据可视化图表,BI工具构建逻辑
本文源码:GitHub·点这里 || GitEE·点这里 一.数据可视化 1.基础概念 数据可视化,是关于数据视觉表现形式的科学技术研究.其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽取出 ...
- 数据可视化 -- Python
前提条件: 熟悉认知新的编程工具(jupyter notebook) 1.安装:采用pip的方式来安装Jupyter.输入安装命令pip install jupyter即可: 2.启动:安装完成后,我 ...
- python 爬虫与数据可视化--数据提取与存储
一.爬虫的定义.爬虫的分类(通用爬虫.聚焦爬虫).爬虫应用场景.爬虫工作原理(最后会发一个完整爬虫代码) 二.http.https的介绍.url的形式.请求方法.响应状态码 url的形式: 请求头: ...
- python 爬虫与数据可视化--爬虫基础知识
一.python中的模块 模块的安装:pip install 模块名 导入模块与函数:import requests . from pymongo import MongoClient json模块的 ...
- [Java]数据分析--数据可视化
时间序列 需求:将一组字符顺序添加到时间序列中 实现:定义时间序列类TimeSeries,包含静态类Entry表示序列类中的各项,以及add,get,iterator,entry方法 TimeSeri ...
随机推荐
- 2022-08-11-emo了
layout: post cid: 7 title: emo了 slug: 7 date: 2022/08/11 10:14:00 updated: 2022/08/11 10:15:40 statu ...
- 后端框架的学习----mybatis框架(7、使用注解开发)
7.使用注解开发 1.注解在接口上实现 /** * 查询用户 */ @Select("select * from user") public List<User> ge ...
- DQL语句
DQL语句 DQL(Data QueryLanguage )数据查询语言,基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块. 一.DQL概述 1.1.什么是DQL DQL:数据查 ...
- 【日志系统】Loki日志监控 - 入门初体验
使用Grafana+Loki+Promtail入门级部署分布式日志系统(windows环境) 生命不息,写作不止 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放 ...
- go基础语法50问,来看看你的go基础合格了吗?
目录 1.使用值为 nil 的 slice.map会发生啥 2.访问 map 中的 key,需要注意啥 3.string 类型的值可以修改吗 4.switch 中如何强制执行下一个 case 代码块 ...
- Python基础之函数:3、多层语法糖、装饰器和装饰器修复技术及递归函数
目录 一.多层语法糖 1.什么是多层语法糖: 2.多层语法糖用法: 二.有参装饰器 1.什么是有参装饰器: 2.有参装饰器的作用: 三.装饰器修复技术 1.什么是装饰器修复技术: 四.递归函数 1.什 ...
- 洛谷P4135 Ynoi2016 掉进兔子洞 (带权bitset?/bitset优化莫队 模板) 题解
题面. 看到这道题,我第一反应就是莫队. 我甚至也猜出了把所有询问的三个区间压到一起处理然后分别计算对应询问答案. 但是,这么复杂的贡献用什么东西存?难道要开一个数组 query_appear_tim ...
- Vue3 —— 组件练习题(附源码)
一.定义一个vue分页组件,实现客户端分页功能 1.1.子组件A(页数按钮) <!-- 本组件用于遍历分页的页数按钮 --> <template lang=""& ...
- 【云原生 · Kubernetes】部署zookeeper
个人名片: 因为云计算成为了监控工程师 个人博客:念舒_C.ying CSDN主页️:念舒_C.ying 部署zookeeper 1.1 zookeeper概述 1.2 ZooKeeper服务中操作 ...
- Codeforces Round #833 (Div. 2)补题
Codeforces Round #833 (Div. 2) D. ConstructOR 知识点:高位和对低位无影响 一开始以为和广州的M一样,是数位dp,后来发现只要找到一个就行 果然无论什么时候 ...