w3cschool-OpenResty 最佳实践Library
https://www.w3cschool.cn/openresty1/
OpenResty LRR 访问有授权验证的 Redis
2、不重启Redis设置密码:
在配置文件中配置requirepass的密码(当redis重启时密码依然有效)。
redis 127.0.0.1:6379> config set requirepass test123
查询密码:
redis 127.0.0.1:6379> config get requirepass
(error) ERR operation not permitted
密码验证:
redis 127.0.0.1:6379> auth test123
OK
再次查询:
redis 127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "test123"
PS:如果配置文件中没添加密码 那么redis重启后,密码失效;
对于有授权验证的 Redis,正确的认证方法,请参考下面例子:
server {
location /test {
content_by_lua_block {
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 sec
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return
end
-- 请注意这里 auth 的调用过程
local count
count, err = red:get_reused_times()
if 0 == count then
ok, err = red:auth("password")
if not ok then
ngx.say("failed to auth: ", err)
return
end
elseif err then
ngx.say("failed to get reused times: ", err)
return
end
ok, err = red:set("dog", "an animal")
if not ok then
ngx.say("failed to set dog: ", err)
return
end
ngx.say("set result: ", ok)
-- 连接池大小是100个,并且设置最大的空闲时间是 10 秒
local ok, err = red:set_keepalive(10000, 100)
if not ok then
ngx.say("failed to set keepalive: ", err)
return
end
}
}
}
这里解释一下 tcpsock:getreusedtimes() 方法,如果当前连接不是从内建连接池中获取的,该方法总是返回 0 ,也就是说,该连接还没有被使用过。如果连接来自连接池,那么返回值永远都是非零。所以这个方法可以用来确认当前连接是否来自池子。
对于 Redis 授权,实际上只需要建立连接后,首次认证一下,后面只需直接使用即可。换句话说,从连接池中获取的连接都是经过授权认证的,只有新创建的连接才需要进行授权认证。所以大家就看到了 count, err = red:get_reused_times() 这段代码,并有了下面 if 0 == count then 的判断逻辑。
OpenResty Redis 接口的二次封装
先看一下官方的调用示例代码:
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 sec
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return
end
ok, err = red:set("dog", "an animal")
if not ok then
ngx.say("failed to set dog: ", err)
return
end
ngx.say("set result: ", ok)
-- put it into the connection pool of size 100,
-- with 10 seconds max idle time
local ok, err = red:set_keepalive(10000, 100)
if not ok then
ngx.say("failed to set keepalive: ", err)
return
end
这是一个标准的 Redis 接口调用,如果你的代码中 Redis 被调用频率不高,那么这段代码不会有任何问题。但如果你的项目重度依赖 Redis,工程中有大量的代码在重复创建连接-->数据操作-->关闭连接(或放到连接池)这个完整的链路调用完毕,甚至还要考虑不同的 return 情况做不同处理,就很快发现代码中有大量的重复。
Lua 是不支持面向对象的。很多人用尽各种招术利用元表来模拟。可是,Lua 的发明者似乎不想看到这样的情形,因为他们把取长度的 __len 方法以及析构函数 __gc 留给了 C API,纯 Lua 只能望洋兴叹。
我们期望的代码应该是这样的:
local red = redis:new()
local ok, err = red:set("dog", "an animal")
if not ok then
ngx.say("failed to set dog: ", err)
return
end
ngx.say("set result: ", ok)
local res, err = red:get("dog")
if not res then
ngx.say("failed to get dog: ", err)
return
end
if res == ngx.null then
ngx.say("dog not found.")
return
end
ngx.say("dog: ", res)
期望它自身具备以下几个特征:
- new、connect 函数合体,使用时只负责申请,尽量少关心什么时候具体连接、释放;
- 默认 Redis 数据库连接地址,但是允许自定义;
- 每次 Redis 使用完毕,自动释放 Redis 连接到连接池供其他请求复用;
- 要支持 Redis 的重要优化手段 pipeline;
不卖关子,只要干货,我们最后是这样干的,可以这里看到 gist代码
-- file name: resty/redis_iresty.lua
local redis_c = require "resty.redis"
local ok, new_tab = pcall(require, "table.new")
if not ok or type(new_tab) ~= "function" then
new_tab = function (narr, nrec) return {} end
end
local _M = new_tab(0, 155)
_M._VERSION = '0.01'
local commands = {
"append", "auth", "bgrewriteaof",
"bgsave", "bitcount", "bitop",
"blpop", "brpop",
"brpoplpush", "client", "config",
"dbsize",
"debug", "decr", "decrby",
"del", "discard", "dump",
"echo",
"eval", "exec", "exists",
"expire", "expireat", "flushall",
"flushdb", "get", "getbit",
"getrange", "getset", "hdel",
"hexists", "hget", "hgetall",
"hincrby", "hincrbyfloat", "hkeys",
"hlen",
"hmget", "hmset", "hscan",
"hset",
"hsetnx", "hvals", "incr",
"incrby", "incrbyfloat", "info",
"keys",
"lastsave", "lindex", "linsert",
"llen", "lpop", "lpush",
"lpushx", "lrange", "lrem",
"lset", "ltrim", "mget",
"migrate",
"monitor", "move", "mset",
"msetnx", "multi", "object",
"persist", "pexpire", "pexpireat",
"ping", "psetex", "psubscribe",
"pttl",
"publish", --[[ "punsubscribe", ]] "pubsub",
"quit",
"randomkey", "rename", "renamenx",
"restore",
"rpop", "rpoplpush", "rpush",
"rpushx", "sadd", "save",
"scan", "scard", "script",
"sdiff", "sdiffstore",
"select", "set", "setbit",
"setex", "setnx", "setrange",
"shutdown", "sinter", "sinterstore",
"sismember", "slaveof", "slowlog",
"smembers", "smove", "sort",
"spop", "srandmember", "srem",
"sscan",
"strlen", --[[ "subscribe", ]] "sunion",
"sunionstore", "sync", "time",
"ttl",
"type", --[[ "unsubscribe", ]] "unwatch",
"watch", "zadd", "zcard",
"zcount", "zincrby", "zinterstore",
"zrange", "zrangebyscore", "zrank",
"zrem", "zremrangebyrank", "zremrangebyscore",
"zrevrange", "zrevrangebyscore", "zrevrank",
"zscan",
"zscore", "zunionstore", "evalsha"
}
local mt = { __index = _M }
local function is_redis_null( res )
if type(res) == "table" then
for k,v in pairs(res) do
if v ~= ngx.null then
return false
end
end
return true
elseif res == ngx.null then
return true
elseif res == nil then
return true
end
return false
end
-- change connect address as you need
function _M.connect_mod( self, redis )
redis:set_timeout(self.timeout)
return redis:connect("127.0.0.1", 6379)
end
function _M.set_keepalive_mod( redis )
-- put it into the connection pool of size 100, with 60 seconds max idle time
return redis:set_keepalive(60000, 1000)
end
function _M.init_pipeline( self )
self._reqs = {}
end
function _M.commit_pipeline( self )
local reqs = self._reqs
if nil == reqs or 0 == #reqs then
return {}, "no pipeline"
else
self._reqs = nil
end
local redis, err = redis_c:new()
if not redis then
return nil, err
end
local ok, err = self:connect_mod(redis)
if not ok then
return {}, err
end
redis:init_pipeline()
for _, vals in ipairs(reqs) do
local fun = redis[vals[1]]
table.remove(vals , 1)
fun(redis, unpack(vals))
end
local results, err = redis:commit_pipeline()
if not results or err then
return {}, err
end
if is_redis_null(results) then
results = {}
ngx.log(ngx.WARN, "is null")
end
-- table.remove (results , 1)
self.set_keepalive_mod(redis)
for i,value in ipairs(results) do
if is_redis_null(value) then
results[i] = nil
end
end
return results, err
end
function _M.subscribe( self, channel )
local redis, err = redis_c:new()
if not redis then
return nil, err
end
local ok, err = self:connect_mod(redis)
if not ok or err then
return nil, err
end
local res, err = redis:subscribe(channel)
if not res then
return nil, err
end
res, err = redis:read_reply()
if not res then
return nil, err
end
redis:unsubscribe(channel)
self.set_keepalive_mod(redis)
return res, err
end
local function do_command(self, cmd, ... )
if self._reqs then
table.insert(self._reqs, {cmd, ...})
return
end
local redis, err = redis_c:new()
if not redis then
return nil, err
end
local ok, err = self:connect_mod(redis)
if not ok or err then
return nil, err
end
local fun = redis[cmd]
local result, err = fun(redis, ...)
if not result or err then
-- ngx.log(ngx.ERR, "pipeline result:", result, " err:", err)
return nil, err
end
if is_redis_null(result) then
result = nil
end
self.set_keepalive_mod(redis)
return result, err
end
for i = 1, #commands do
local cmd = commands[i]
_M[cmd] =
function (self, ...)
return do_command(self, cmd, ...)
end
end
function _M.new(self, opts)
opts = opts or {}
local timeout = (opts.timeout and opts.timeout * 1000) or 1000
local db_index= opts.db_index or 0
return setmetatable({
timeout = timeout,
db_index = db_index,
_reqs = nil }, mt)
end
return _M
调用示例代码:
local redis = require "resty.redis_iresty"
local red = redis:new()
local ok, err = red:set("dog", "an animal")
if not ok then
ngx.say("failed to set dog: ", err)
return
end
ngx.say("set result: ", ok)
在最终的示例代码中看到,所有的连接创建、销毁连接、连接池部分,都被完美隐藏了,我们只需要业务就可以了。妈妈再也不用担心我把 Redis 搞垮了。
OpenResty LRR Redis 接口的二次封装(发布订阅)
其实这一小节完全可以放到上一个小节,只是这里用了完全不同的玩法,所以我还是决定单拿出来分享一下这方面的小细节。
上一小节有关订阅部分的代码,请看:
function _M.subscribe( self, channel )
local redis, err = redis_c:new()
if not redis then
return nil, err
end
local ok, err = self:connect_mod(redis)
if not ok or err then
return nil, err
end
local res, err = redis:subscribe(channel)
if not res then
return nil, err
end
res, err = redis:read_reply()
if not res then
return nil, err
end
redis:unsubscribe(channel)
self.set_keepalive_mod(redis)
return res, err
end
其实这里的实现是有问题的,各位看官,你能发现这段代码的问题么?给个提示,在高并发订阅场景下,极有可能存在漏掉部分订阅信息。原因在于每次订阅到内容后,都会把 Redis 对象进行释放,处理完订阅信息后再次去连接 Redis,在这个时间差里面,很可能有消息已经漏掉了。
通过下面的代码可以解决这个问题:
function _M.subscribe( self, channel )
local redis, err = redis_c:new()
if not redis then
return nil, err
end
local ok, err = self:connect_mod(redis)
if not ok or err then
return nil, err
end
local res, err = redis:subscribe(channel)
if not res then
return nil, err
end
local function do_read_func ( do_read )
if do_read == nil or do_read == true then
res, err = redis:read_reply()
if not res then
return nil, err
end
return res
end
redis:unsubscribe(channel)
self.set_keepalive_mod(redis)
return
end
return do_read_func
end
调用示例代码:
local red = redis:new({timeout=1000})
local func = red:subscribe( "channel" )
if not func then
return nil
end
while true do
local res, err = func()
if err then
func(false)
end
... ...
end
return cbfunc
另一个潜在的问题是,调用了 unsubscribe 之后,Redis 对象里面有可能还遗留没被读取的数据。在这种情况下,无法直接通过 set_keepalive_mod 复用连接。什么时候会发生这样的情况呢?
当 Redis 对象处于 subscribe 状态时,Redis 会给它推送订阅的消息,然后我们通过 read_reply 把消息读出来。调用 unsubscribe 的时候,只是退订了对应的频道,并不会把当前接收到的数据清空。如果要想复用该连接,我们就需要保证清空当前读取到的数据,保证它是干净的。就像这样:
local res, err = red:unsubscribe("ch")
if not res then
ngx.log(ngx.ERR, err)
return
else
-- redis 推送的消息格式,可能是
-- {"message", ...} 或
-- {"unsubscribe", $channel_name, $remain_channel_num}
-- 如果返回的是前者,说明我们还在读取 Redis 推送过的数据
if res[1] ~= "unsubscribe" then
repeat
-- 需要抽空已经接收到的消息
res, err = red:read_reply()
if not res then
ngx.log(ngx.ERR, err)
return
end
until res[1] == "unsubscribe"
end
-- 现在再复用连接,就足够安全了
self.set_keepalive_mod(redis)
endOpenResty pipeline 压缩请求数量
如果我们确定开启了长连接,发现这时候 Redis 的 CPU 的占用率还是不高,在这种情况下,就要从 Redis 的使用方法上进行优化。
如果我们可以把所有单次请求,压缩到一起,如下图:

很庆幸 Redis 早就为我们准备好了这道菜,就等着我们吃了,这道菜就叫 pipeline。pipeline 机制将多个命令汇聚到一个请求中,可以有效减少请求数量,减少网络延时。下面是对比使用 pipeline 的一个例子:
# you do not need the following line if you are using
# the ngx_openresty bundle:
lua_package_path "/path/to/lua-resty-redis/lib/?.lua;;";
server {
location /withoutpipeline {
content_by_lua_block {
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 sec
-- or connect to a unix domain socket file listened
-- by a redis server:
-- local ok, err = red:connect("unix:/path/to/redis.sock")
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return
end
local ok, err = red:set("cat", "Marry")
ngx.say("set result: ", ok)
local res, err = red:get("cat")
ngx.say("cat: ", res)
ok, err = red:set("horse", "Bob")
ngx.say("set result: ", ok)
res, err = red:get("horse")
ngx.say("horse: ", res)
-- put it into the connection pool of size 100,
-- with 10 seconds max idle time
local ok, err = red:set_keepalive(10000, 100)
if not ok then
ngx.say("failed to set keepalive: ", err)
return
end
}
}
location /withpipeline {
content_by_lua_block {
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 sec
-- or connect to a unix domain socket file listened
-- by a redis server:
-- local ok, err = red:connect("unix:/path/to/redis.sock")
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return
end
red:init_pipeline()
red:set("cat", "Marry")
red:set("horse", "Bob")
red:get("cat")
red:get("horse")
local results, err = red:commit_pipeline()
if not results then
ngx.say("failed to commit the pipelined requests: ", err)
return
end
for i, res in ipairs(results) do
if type(res) == "table" then
if not res[1] then
ngx.say("failed to run command ", i, ": ", res[2])
else
-- process the table value
end
else
-- process the scalar value
end
end
-- put it into the connection pool of size 100,
-- with 10 seconds max idle time
local ok, err = red:set_keepalive(10000, 100)
if not ok then
ngx.say("failed to set keepalive: ", err)
return
end
}
}
}
在我们实际应用场景中,正确使用 pipeline 对性能的提升十分明显。我们曾经某个后台应用,逐个处理大约 100 万条记录需要几十分钟,经过 pileline 压缩请求数量后,最后时间缩小到 20 秒左右。做之前能预计提升性能,但是没想到提升如此巨大。
OpenResty LRR script 压缩复杂请求
从pipeline章节,我们知道对于多个简单的 Redis 命令可以汇聚到一个请求中,提升服务端的并发能力。然而,在有些场景下,我们每次命令的输入需要引用上个命令的输出,甚至可能还要对第一个命令的输出做一些加工,再把加工结果当成第二个命令的输入。pipeline 难以处理这样的场景。庆幸的是,我们可以用 Redis 里的 script 来压缩这些复杂命令。
script 的核心思想是在 Redis 命令里嵌入 Lua 脚本,来实现一些复杂操作。Redis 中和脚本相关的命令有:
- EVAL
- EVALSHA
- SCRIPT EXISTS
- SCRIPT FLUSH
- SCRIPT KILL
- SCRIPT LOADOpenResty json 解析的异常捕获
首先来看最最普通的一个 json 解析的例子(被解析的 json 字符串是错误的,缺少一个双引号):
-- http://www.kyne.com.au/~mark/software/lua-cjson.php
-- version: 2.1 devel
local json = require("cjson")
local str = [[ {"key:"value"} ]]
local t = json.decode(str)
ngx.say(" --> ", type(t))
-- ... do the other things
ngx.say("all fine")
代码执行错误日志如下:
2015/06/27 00:01:42 [error] 2714#0: *25 lua entry thread aborted: runtime error: ...ork/git/github.com/lua-resty-memcached-server/t/test.lua:8: Expected colon but found invalid token at character 9
stack traceback:
coroutine 0:
[C]: in function 'decode'
...ork/git/github.com/lua-resty-memcached-server/t/test.lua:8: in function <...ork/git/github.com/lua-resty-memcached-server/t/test.lua:1>, client: 127.0.0.1, server: localhost, request: "GET /test HTTP/1.1", host: "127.0.0.1:8001"
这可不是期望结果:decode 失败,500 错误直接退了。改良了一下代码:
local decode = require("cjson").decode
function json_decode( str )
local ok, t = pcall(decode, str)
if not ok then
return nil
end
return t
end
如果需要在 Lua 中处理错误,必须使用函数 pcall(protected call)来包装需要执行的代码。 pcall 接收一个函数和要传递给后者的参数,并执行,执行结果:有错误、无错误;返回值 true 或者 false, errorinfo。pcall 以一种“保护模式”来调用第一个参数,因此 pcall 可以捕获函数执行中的任何错误。有兴趣的同学,请更多了解下 Lua 中的异常处理。
另外,可以使用 CJSON 2.1.0,该版本新增一个 cjson.safe 模块接口,该接口兼容 cjson 模块,并且在解析错误时不抛出异常,而是返回 nil。
local json = require("cjson.safe")
local str = [[ {"key:"value"} ]]
local t = json.decode(str)
if t then
ngx.say(" --> ", type(t))
endOpenResty 模块的调用方式
ngx_postgres 模块使用方法
location /postgres {
internal;
default_type text/html;
set_by_lua_block $query_sql {return ngx.unescape_uri(ngx.var.arg_sql)}
postgres_pass pg_server;
rds_json on;
rds_json_buffer_size 16k;
postgres_query $query_sql;
postgres_connect_timeout 1s;
postgres_result_timeout 2s;
}
这里有很多指令要素:
- internal 这个指令指定所在的 location 只允许使用于处理内部请求,否则返回 404。
- set_by_lua 这一段内嵌的 Lua 代码用于计算出 $query_sql 变量的值,即后续通过指令 postgres_query 发送给 PostgreSQL 处理的 SQL 语句。这里使用了 GET 请求的 query 参数作为 SQL 语句输入。
- postgres_pass 这个指令可以指定一组提供后台服务的 PostgreSQL 数据库的 upstream 块。
- rds_json 这个指令是 ngx_rds_json 提供的,用于指定 ngx_rds_json 的 output 过滤器的开关状态,其模块作用就是一个用于把 rds 格式数据转换成 json 格式的 output filter。这个指令在这里出现意思是让 ngx_rds_json 模块帮助 ngx_postgres 模块把模块输出数据转换成 json 格式的数据。
- rds_json_buffer_size 这个指令指定 ngx_rds_json 用于每个连接的数据转换的内存大小. 默认是 4/8k,适当加大此参数,有利于减少 CPU 消耗。
- postgres_query 指定 SQL 查询语句,查询语句将会直接发送给 PostgreSQL 数据库。
- postgres_connect_timeout 设置连接超时时间。
- postgres_result_timeout 设置结果返回超时时间。
这样的配置就完成了初步的可以提供其他 location 调用的 location 了。但这里还差一个配置没说明白,就是这一行:
postgres_pass pg_server;
其实这一行引入了 名叫 pg_server 的 upstream 块,其定义应该像如下:
upstream pg_server {
postgres_server 192.168.1.2:5432 dbname=pg_database
user=postgres password=postgres;
postgres_keepalive max=800 mode=single overflow=reject;
}
这里有一些指令要素:
- postgres_server 这个指令是必须带的,但可以配置多个,用于配置服务器连接参数,可以分解成若干参数:直接跟在后面的应该是服务器的 IP:Portdbname 是服务器要连接的 PostgreSQL 的数据库名称。user 是用于连接 PostgreSQL 服务器的账号名称。password 是账号名称对应的密码。
- postgres_keepalive 这个指令用于配置长连接连接池参数,长连接连接池有利于提高通讯效率,可以分解为若干参数:max 是工作进程可以维护的连接池最大长连接数量。mode 是后端匹配模式,在postgres_server 配置了多个的时候发挥作用,有 single 和 multi 两种值,一般使用 single 即可。overflow 是当长连接数量到达 max 之后的处理方案,有 ignore 和 reject 两种值。ignore 允许创建新的连接与数据库通信,但完成通信后马上关闭此连接。reject 拒绝访问并返回 503 Service Unavailable
这样就构成了我们 PostgreSQL 后端通讯的通用 location,在使用 Lua 业务编码的过程中可以直接使用如下代码连接数据库(折腾了这么老半天):
local json = require "cjson"
function test()
local res = ngx.location.capture('/postgres',
{ args = {sql = "SELECT * FROM test" } }
)
local status = res.status
local body = json.decode(res.body)
if status == 200 then
status = true
else
status = false
end
return status, body
end
与 resty-mysql 调用方式的不同
先来看一下 lua-resty-mysql 模块的调用示例代码。
# you do not need the following line if you are using
# the ngx_openresty bundle:
lua_package_path "/path/to/lua-resty-mysql/lib/?.lua;;";
server {
location /test {
content_by_lua_block {
local mysql = require "resty.mysql"
local db, err = mysql:new()
if not db then
ngx.say("failed to instantiate mysql: ", err)
return
end
db:set_timeout(1000) -- 1 sec
local ok, err, errno, sqlstate = db:connect{
host = "127.0.0.1",
port = 3306,
database = "ngx_test",
user = "ngx_test",
password = "ngx_test",
max_packet_size = 1024 * 1024 }
if not ok then
ngx.say("failed to connect: ", err, ": ", errno, " ", sqlstate)
return
end
ngx.say("connected to mysql.")
-- run a select query, expected about 10 rows in
-- the result set:
res, err, errno, sqlstate =
db:query("select * from cats order by id asc", 10)
if not res then
ngx.say("bad result: ", err, ": ", errno, ": ", sqlstate, ".")
return
end
local cjson = require "cjson"
ngx.say("result: ", cjson.encode(res))
-- put it into the connection pool of size 100,
-- with 10 seconds max idle timeout
local ok, err = db:set_keepalive(10000, 100)
if not ok then
ngx.say("failed to set keepalive: ", err)
return
end
}
}
}
看过这段代码,大家肯定会说:这才是我熟悉的,我想要的。为什么刚刚 ngx_postgres 模块的调用这么诡异,配置那么复杂,其实这是发展历史造成的。ngx_postgres 起步比较早,当时 OpenResty 也还没开始流行,所以更多的 Nginx 数据库都是以 ngx_c_module 方式存在。有了 OpenResty,才让我们具有了使用完整的语言来描述我们业务能力。
后面我们会单独说一说使用 ngx_c_module 的各种不方便,也就是我们所踩过的坑。希望能给大家一个警示,能转到 lua-resty-*** 这个方向的,就千万不要和 ngx_c_module 玩,ngx_c_module 的扩展性、可维护性、升级等各方面都没有 lua-resty-*** 好。
OpenResty 不支持事务
OpenResty 超时
当我们所有数据库的 SQL 语句是通过子查询方式完成,对于超时的控制往往很容易被大家忽略。因为大家在代码里看不到任何调用 set_timeout 的地方。实际上 PostgreSQL 已经为我们预留好了两个设置。
请参考下面这段配置:
location /postgres {
internal;
default_type text/html;
set_by_lua_block $query_sql {return ngx.unescape_uri(ngx.var.arg_sql)}
postgres_pass pg_server;
rds_json on;
rds_json_buffer_size 16k;
postgres_query $query_sql;
postgres_connect_timeout 1s;
postgres_result_timeout 2s;
}
生产中使用这段配置,遇到了一个不大不小的坑。在我们的开发机、测试环境上都没有任何问题的安装包,到了用户那边出现所有数据库操作异常,而且是数据库连接失败,但手工连接本地数据库,发现没有任何问题。同样的执行程序再次 copy 回来后,公司内环境不能复现问题。考虑到我们当次升级刚好修改了 postgres_connect_timeout 和 postgres_result_timeout 的默认值,所以我们尝试去掉了这两行个性设置,重启服务后一切都好了。
起初我们也很怀疑出了什么诡异问题,要知道我们的 nginx 和 PostgreSQL 可是安装在本机,都是使用 127.0.0.1 这样的 IP 来完成通信的,难道客户的机器在这个时间内还不能完成连接建立?
经过后期排插问题,发现是客户的机器上安装了一些趋势科技的杀毒客户端,而趋势科技为了防止无效连接,对所有连接的建立均阻塞了一秒钟。就是这一秒钟,让我们的服务彻底歇菜。
本以为是一次比较好的优化,没想到因为这个原因没能保留下来,反而给大家带来麻烦。只能说企业版环境复杂,边界比较多。但也好在我们一直使用最常见的技术、最常见的配置解决各种问题,让我们的经验可以复用到其他公司里。
OpenResty 执行阶段概念
OpenResty 处理一个请求,它的处理流程请参考下图(从 Request start 开始):
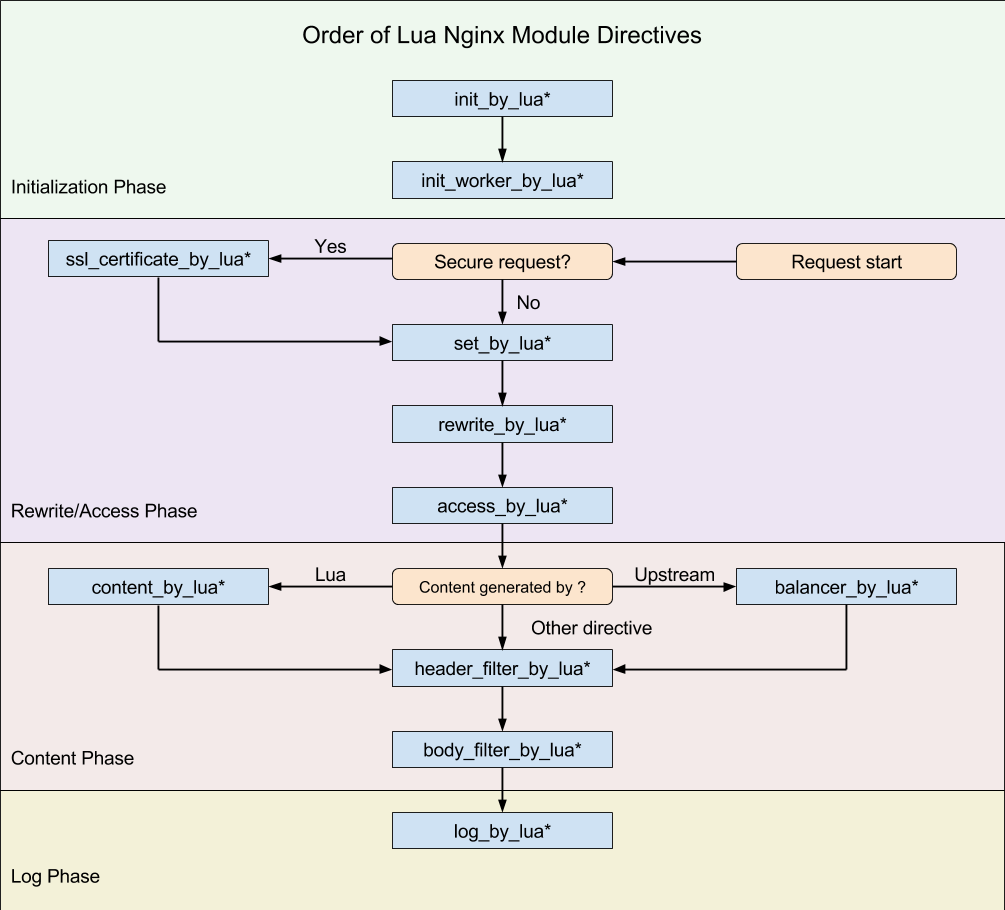
我们在这里做个测试,示例代码如下:
location /mixed {
set_by_lua_block $a {
ngx.log(ngx.ERR, "set_by_lua*")
}
rewrite_by_lua_block {
ngx.log(ngx.ERR, "rewrite_by_lua*")
}
access_by_lua_block {
ngx.log(ngx.ERR, "access_by_lua*")
}
content_by_lua_block {
ngx.log(ngx.ERR, "content_by_lua*")
}
header_filter_by_lua_block {
ngx.log(ngx.ERR, "header_filter_by_lua*")
}
body_filter_by_lua_block {
ngx.log(ngx.ERR, "body_filter_by_lua*")
}
log_by_lua_block {
ngx.log(ngx.ERR, "log_by_lua*")
}
}
执行结果日志(截取了一下):
set_by_lua*
rewrite_by_lua*
access_by_lua*
content_by_lua*
header_filter_by_lua*
body_filter_by_lua*
log_by_lua*
这几个阶段的存在,应该是 OpenResty 不同于其他多数 Web 平台编程的最明显特征了。由于 Nginx 把一个请求分成了很多阶段,这样第三方模块就可以根据自己行为,挂载到不同阶段进行处理达到目的。OpenResty 也应用了同样的特性。所不同的是,OpenResty 挂载的是我们编写的 Lua 代码。
这样我们就可以根据我们的需要,在不同的阶段直接完成大部分典型处理了。
-
set_by_lua*: 流程分支处理判断变量初始化 -
rewrite_by_lua*: 转发、重定向、缓存等功能(例如特定请求代理到外网) -
access_by_lua*: IP 准入、接口权限等情况集中处理(例如配合 iptable 完成简单防火墙) -
content_by_lua*: 内容生成 -
header_filter_by_lua*: 响应头部过滤处理(例如添加头部信息) -
body_filter_by_lua*: 响应体过滤处理(例如完成应答内容统一成大写) -
log_by_lua*: 会话完成后本地异步完成日志记录(日志可以记录在本地,还可以同步到其他机器)
实际上我们只使用其中一个阶段 content_by_lua*,也可以完成所有的处理。但这样做,会让我们的代码比较臃肿,越到后期越发难以维护。把我们的逻辑放在不同阶段,分工明确,代码独立,后期发力可以有很多有意思的玩法。
举一个例子,如果在最开始的开发中,请求体和响应体都是通过 HTTP 明文传输,后面需要使用 aes 加密,利用不同的执行阶段,我们可以非常简单的实现:
# 明文协议版本
location /mixed {
content_by_lua_file ...; # 请求处理
}
# 加密协议版本
location /mixed {
access_by_lua_file ...; # 请求加密解码
content_by_lua_file ...; # 请求处理,不需要关心通信协议
body_filter_by_lua_file ...; # 应答加密编码
}
内容处理部分都是在 content_by_lua* 阶段完成,第一版本 API 接口开发都是基于明文。为了传输体积、安全等要求,我们设计了支持压缩、加密的密文协议(上下行),痛点就来了,我们要更改所有 API 的入口、出口么?
最后我们是在 access_by_lua* 完成密文协议解码,body_filter_by_lua* 完成应答加密编码。如此一来世界都宁静了,我们没有更改已实现功能的一行代码,只是利用 OpenResty 的阶段处理特性,非常优雅的解决了这个问题。
不同的阶段,有不同的处理行为,这是 OpenResty 的一大特色。学会它,适应它,会给你打开新的一扇门。这些东西不是 OpenResty 自身所创,而是 Nginx module 对外开放的处理阶段。理解了他,也能更好的理解 Nginx 的设计思维。
OpenResty 热装载代码
在 OpenResty 中,提及热加载代码,估计大家的第一反应是 lua_code_cache 这个开关。 但 lua_code_cache off 的工作原理,是给每个请求创建一个独立的 Lua VM。即使抛去性能因素不谈,考虑到程序的正确性,也不应该在生产环境中关闭 lua_code_cache。
那么我们是否可以在生产环境中完成热加载呢?
- 代码有变动时,自动加载最新 Lua 代码,但是 Nginx 本身,不做任何 reload。
- 自动加载后的代码,享用
lua_code_cache on 带来的高效特性。
- 使用 HUP reload 或者 binary upgrade 方式动态加载 Nginx 配置或重启 Nginx。这不会导致中间有请求被 drop 掉。
- 当
content_by_lua_file里使用 Nginx 变量时,是可以动态加载新的 Lua 脚本的,不过要记得对 Nginx 变量的值进行基本的合法性验证,以免被注入攻击。
location ~ '^/lua/(\w+(?:\/\w+)*)$' {
content_by_lua_file $1;
}
- 自己从外部数据源(包括文件系统)加载 Lua 源码或字节码,然后使用
loadstring() "eval" 进 Lua VM. 可以通过 package.loaded 自己来做缓存,毕竟频繁地加载源码和调用 loadstring(),以及频繁地 JIT 编译还是很昂贵的。比如 CloudFlare 公司采用的方法是从 modsecurity 规则编译出来的 Lua 代码就是通过 KyotoTycoon 动态分发到全球网络中的每一个 Nginx 服务器的。无需 reload 或者 binary upgrade.
自定义 module 的动态装载
对于已经装载的 module,我们可以通过 package.loaded.* = nil 的方式卸载(注意:如果对应模块是通过本地文件 require 加载的,该方式失效,ngx_lua_module 里面对以文件加载模块的方式做了特殊处理)。
OpenResty 阻塞操作
OpenResty 的诞生,一直对外宣传是同步非阻塞(100% non-blocking)的。基于事件通知的 Nginx 给我们带来了足够强悍的高并发支持,但是也对我们的编码有特殊要求。这个特殊要求就是我们的代码,也必须是非阻塞的。如果你的服务端编程生涯一开始就是从异步框架开始的,恭喜你了。但如果你的编程生涯是从同步框架过来的,而且又是刚刚开始深入了解异步框架,那你就要小心了。
Nginx 为了减少系统上下文切换,它的 worker 是用单进程单线程设计的,事实证明这种做法运行效率很高。Nginx 要么是在等待网络讯号,要么就是在处理业务(请求数据解析、过滤、内容应答等),没有任何额外资源消耗。
常见语言代表异步框架
- Golang:使用协程技术实现
- Python:gevent 基于协程的 Python 网络库
- Rust:用的少,只知道语言完备支持异步框架
- OpenResty:基于 Nginx,使用事件通知机制
- Java:Netty,使用网络事件通知机制
异步编程的噩梦
异步编程,如果从零开始,难度是非常大的。一个完整的请求,由于网络传输的非连续性,这个请求要被多次挂起、恢复、运行,一旦网络有新数据到达,都需要立刻唤醒恢复原始请求处于运行状态。开发人员不仅仅要考虑异步 API 接口本身的使用规范,还要考虑业务请求的完整处理,稍有不慎,全盘皆输。
最最重要的噩梦是,我们好不容易搞定异步框架和业务请求完整性,但是却在我们的业务请求上使用了阻塞函数。一开始没有任何感知,只有做压力测试的时候才发现我们的并发量上不去,各种卡顿,甚至开始怀疑人生:异步世界也就这样。
OpenResty 中的阻塞函数
官方有明确说明,OpenResty 的官方 API 绝对 100% non-blocking,所以我们只能在她的外面寻找了。我这里大致归纳总结了一下,包含下面几种情况:
- 高 CPU 的调用(压缩、解压缩、加解密等)
- 高磁盘的调用(所有文件操作)
- 非 OpenResty 提供的网络操作(luasocket 等)
- 系统命令行调用(os.execute 等)
这些都应该是我们尽量要避免的。理想丰满,现实骨感,谁能保证我们的应用中不使用这些类型的 API?没人保证,我们能做的就是把他们的调用数量、频率降低再降低,如果还是不能满足我们需要,那么就考虑把他们封装成独立服务,对外提供 TCP/HTTP 级别的接口调用,这样我们的 OpenResty 就可以同时享受异步编程的好处又能达到我们的目的。
OpenResty 缓存
缓存的原则
缓存是一个大型系统中非常重要的一个组成部分。在硬件层面,大部分的计算机硬件都会用缓存来提高速度,比如 CPU 会有多级缓存、RAID 卡也有读写缓存。在软件层面,我们用的数据库就是一个缓存设计非常好的例子,在 SQL 语句的优化、索引设计、磁盘读写的各个地方,都有缓存,建议大家在设计自己的缓存之前,先去了解下 MySQL 里面的各种缓存机制,感兴趣的可以去看下High Performance MySQL这本非常有价值的书。
一个生产环境的缓存系统,需要根据自己的业务场景和系统瓶颈,来找出最好的方案,这是一门平衡的艺术。
一般来说,缓存有两个原则。一是越靠近用户的请求越好,比如能用本地缓存的就不要发送 HTTP 请求,能用 CDN 缓存的就不要打到 Web 服务器,能用 Nginx 缓存的就不要用数据库的缓存;二是尽量使用本进程和本机的缓存解决,因为跨了进程和机器甚至机房,缓存的网络开销就会非常大,在高并发的时候会非常明显。
OpenResty 的缓存
我们介绍下在 OpenResty 里面,有哪些缓存的方法。
使用 Lua shared dict
我们看下面这段代码:
function get_from_cache(key)
local cache_ngx = ngx.shared.my_cache
local value = cache_ngx:get(key)
return value
end
function set_to_cache(key, value, exptime)
if not exptime then
exptime = 0
end
local cache_ngx = ngx.shared.my_cache
local succ, err, forcible = cache_ngx:set(key, value, exptime)
return succ
end
这里面用的就是 ngx shared dict cache。你可能会奇怪,ngx.shared.my_cache 是从哪里冒出来的?没错,少贴了 nginx.conf 里面的修改:
lua_shared_dict my_cache 128m;
如同它的名字一样,这个 cache 是 Nginx 所有 worker 之间共享的,内部使用的 LRU 算法(最近最少使用)来判断缓存是否在内存占满时被清除。
使用Lua LRU cache
直接复制下春哥的示例代码:
local _M = {}
-- alternatively: local lrucache = require "resty.lrucache.pureffi"
local lrucache = require "resty.lrucache"
-- we need to initialize the cache on the Lua module level so that
-- it can be shared by all the requests served by each nginx worker process:
local c = lrucache.new(200) -- allow up to 200 items in the cache
if not c then
return error("failed to create the cache: " .. (err or "unknown"))
end
function _M.go()
c:set("dog", 32)
c:set("cat", 56)
ngx.say("dog: ", c:get("dog"))
ngx.say("cat: ", c:get("cat"))
c:set("dog", { age = 10 }, 0.1) -- expire in 0.1 sec
c:delete("dog")
end
return _M
可以看出来,这个 cache 是 worker 级别的,不会在 Nginx wokers 之间共享。并且,它是预先分配好 key 的数量,而 shared dict 需要自己用 key 和 value 的大小和数量,来估算需要把内存设置为多少。
如何选择?
shared.dict 使用的是共享内存,每次操作都是全局锁,如果高并发环境,不同 worker 之间容易引起竞争。所以单个 shared.dict 的体积不能过大。lrucache 是 worker 内使用的,由于 Nginx 是单进程方式存在,所以永远不会触发锁,效率上有优势,并且没有 shared.dict 的体积限制,内存上也更弹性,但不同 worker 之间数据不同享,同一缓存数据可能被冗余存储。
你需要考虑的,一个是 Lua lru cache 提供的 API 比较少,现在只有 get、set 和 delete,而 ngx shared dict 还可以 add、replace、incr、get_stale(在 key 过期时也可以返回之前的值)、get_keys(获取所有 key,虽然不推荐,但说不定你的业务需要呢);第二个是内存的占用,由于 ngx shared dict 是 workers 之间共享的,所以在多 worker 的情况下,内存占用比较少。
OpenResty 定时任务
我们介绍了一种实现的方法,这里我们 介绍一种更优雅更通用的方法:ngx.timer.at()。 ngx.timer.at 会创建一个 Nginx timer。在事件循环中,Nginx 会找出到期的 timer,并在一个独立的协程中执行对应的 Lua 回调函数。 有了这种机制,ngx_lua 的功能得到了非常大的扩展,我们有机会做一些更有想象力的功能出来。比如 批量提交和 cron 任务。随便一提,官方的 resty-cli 工具,也是基于 ngx.timer.at 来运行指定的代码块。
比较典型的用法,如下示例:
local delay = 5
local handler
-- do some routine job in Lua just like a cron job
handler = function (premature)
if premature then
return
end
local ok, err = ngx.timer.at(delay, handler)
if not ok then
ngx.log(ngx.ERR, "failed to create the timer: ", err)
return
end
end
local ok, err = ngx.timer.at(delay, handler)
if not ok then
ngx.log(ngx.ERR, "failed to create the timer: ", err)
return
end
从示例代码中我们可以看到,ngx.timer.at 创建的回调是一次性的。如果要实现“定期”运行,需要在回调函数中重新创建 timer 才行。不过当前主线上的 OpenResty 已经引入了新的 ngx.timer.every 接口,允许直接创建定期执行的 timer。
ngx.timer.at 的 delay 参数,指定的是以秒为单位的延迟触发时间。跟 OpenResty 的其他函数一样,指定的时间最多精确到毫秒。如果你想要的是一个当前阶段结束后立刻执行的回调,可以直接设置 delay 为 0。 handler 回调第一个参数 premature,则是用于标识触发该回调的原因是否由于 timer 的到期。Nginx worker 的退出,也会触发当前所有有效的 timer。这时候 premature 会被设置为 true。回调函数需要正确处理这一参数(通常直接返回即可)。
需要特别注意的是:有一些 ngx_lua 的 API 不能在这里调用,比如子请求、ngx.req.*和向下游输出的 API(ngx.print、ngx.flush 之类),原因是这些调用需要依赖具体的请求。但是 ngx.timer.at 自身的运行,与当前的请求并没有关系的。
再说一遍,ngx.timer.at 的执行是在独立的协程里完成的。千万不能忽略这一点。有人可能会犯这样的错误:
local tcpsock = create_tcp_client() -- 创建一个 cosocket 连接
local ok, err = ngx.timer.at(delay, function()
tcpsock:send() -- bad request!
end)
cosocket 跟某个特定的 ngx_http_request_t* 绑定在一起的。虽然由于闭包,在回调函数中我们依旧可以访问 tcpsock,但整个上下文已经不一样了。
OpenResty 禁止某些终端访问
不同的业务应用场景,会有完全不同的非法终端控制策略,常见的限制策略有终端 IP 、访问域名端口,这些可以通过防火墙等很多成熟手段完成。可也有一些特定限制策略,例如特定 cookie、url、location,甚至请求 body 包含有特殊内容,这种情况下普通防火墙就比较难限制。
Nginx 是 HTTP 7 层协议的实现者,相对普通防火墙从通讯协议有自己的弱势,同等的配置下的性能表现绝对远不如防火墙,但它的优势胜在价格便宜、调整方便,还可以完成 HTTP 协议上一些更具体的控制策略,与 iptable 的联合使用,让 Nginx 玩出更多花样。
列举几个限制策略来源
- IP 地址
- 域名、端口
- Cookie 特定标识
- location
- body 中特定标识
示例配置(allow、deny)
location / {
deny 192.168.1.1;
allow 192.168.1.0/24;
allow 10.1.1.0/16;
allow 2001:0db8::/32;
deny all;
}
这些规则都是按照顺序解析执行直到某一条匹配成功。在这里示例中,10.1.1.0/16 and 192.168.1.0/24 都是用来限制 IPv4 的,2001:0db8::/32 的配置是用来限制 IPv6。具体有关 allow、deny 配置,请参考这里。
示例配置(geo)
Example:
geo $country {
default ZZ;
proxy 192.168.100.0/24;
127.0.0.0/24 US;
127.0.0.1/32 RU;
10.1.0.0/16 RU;
192.168.1.0/24 UK;
}
if ($country == ZZ){
return 403;
}
使用 geo,让我们有更多的分支条件。注意:在 Nginx 的配置中,尽量少用或者不用 if ,因为 "if is evil"。点击查看
目前为止所有的控制,都是用 Nginx 模块完成,执行效率、配置明确是它的优点。缺点也比较明显,修改配置代价比较高(reload 服务)。并且无法完成与第三方服务的对接功能交互(例如调用 iptable)。
在 OpenResty 里面,这些问题就都容易解决,还记得 access_by_lua* 么?推荐一个第三方库lua-resty-iputils。
示例代码:
init_by_lua_block {
local iputils = require("resty.iputils")
iputils.enable_lrucache()
local whitelist_ips = {
"127.0.0.1",
"10.10.10.0/24",
"192.168.0.0/16",
}
-- WARNING: Global variable, recommend this is cached at the module level
-- https://github.com/openresty/lua-nginx-module#data-sharing-within-an-nginx-worker
whitelist = iputils.parse_cidrs(whitelist_ips)
}
access_by_lua_block {
local iputils = require("resty.iputils")
if not iputils.ip_in_cidrs(ngx.var.remote_addr, whitelist) then
return ngx.exit(ngx.HTTP_FORBIDDEN)
end
}
以次类推,我们想要完成域名、Cookie、location、特定 body 的准入控制,甚至可以做到与本地 iptable 防火墙联动。 我们可以把 IP 规则存到数据库中,这样我们就再也不用 reload Nginx,在有规则变动的时候,刷新下 Nginx 的缓存就行了。
OpenResty 变量的共享范围
OpenResty 中 Lua 变量的范围
全局变量
在 OpenResty 里面,只有在 init_by_lua* 和 init_worker_by_lua* 阶段才能定义真正的全局变量。 这是因为其他阶段里面,OpenResty 会设置一个隔离的全局变量表,以免在处理过程污染了其他请求。 即使在上述两个可以定义全局变量的阶段,也尽量避免这么做。全局变量能解决的问题,用模块变量也能解决, 而且会更清晰、更干净。
模块变量
这里把定义在模块里面的变量称为模块变量。无论定义变量时有没有加 local,有没有通过 _M 把变量引用起来, 定义在模块里面的变量都是模块变量。
由于 Lua VM 会把 require 进来的模块缓存到 package.loaded 表里,除非设置了 lua_code_cache off, 模块里定义的变量都会被缓存起来。而且重要的是,模块变量在每个请求中是共享的。 模块变量的跨请求特性,可以有很多用途。比如在变量间共享值,或者在 init_worker_by_lua* 中初始化全局用到的数值。 作为硬币的反面,无视这一特性也会带来许多问题。下面让我们看看一个例子。
OpenResty 动态限速
在应用开发中,经常会有对请求进行限速的需求。
通常意义上的限速,其实可以分为以下三种:
- limit_rate 限制响应速度
- limit_conn 限制连接数
- limit_req 限制请求数
接下来让我们看看,这三种限速在 OpenResty 中分别怎么实现。
限制响应速度
Nginx 有一个 $limit_rate,这个变量反映的是当前请求每秒能响应的字节数。该字节数默认为配置文件中 limit_rate 指令的设值。 一如既往,通过 OpenResty,我们可以直接在 Lua 代码中动态设置它。
access_by_lua_block {
-- 设定当前请求的响应上限是 每秒 300K 字节
ngx.var.limit_rate = "300K"
}
限制连接数和请求数
对于连接数和请求数的限制,我们可以求助于 OpenResty 官方的 lua-resty-limit-traffic 需要注意的是,lua-resty-limit-traffic 要求 OpenResty 版本在 1.11.2.2 以上(对应的 lua-nginx-module 版本是 0.10.6)。 如果要配套更低版本的 OpenResty 使用,需要修改源码。比如把代码中涉及 incr(key, value, init) 方法,改成 incr(key, value) 和 set(key, init) 两步操作。这么改会增大有潜在 race condition 的区间。
lua-resty-limit-traffic 这个库是作用于所有 Nginx worker 的。 由于数据同步上的局限,在限制请求数的过程中 lua-resty-limit-traffic 有一个 race condition 的区间,可能多放过几个请求。误差大小取决于 Nginx worker 数量。 如果要求“宁可拖慢一千,不可放过一个”的精确度,恐怕就不能用这个库了。你可能需要使用 lua-resty-lock 或外部的锁服务,只是性能上的代价会更高。
lua-resty-limit-traffic 的限速实现基于漏桶原理。 通俗地说,就是小学数学中,蓄水池一边注水一边放水的问题。 这里注水的速度是新增请求/连接的速度,而放水的速度则是配置的限制速度。 当注水速度快于放水速度(表现为池中出现蓄水),则返回一个数值 delay。调用者通过 ngx.sleep(delay) 来减慢注水的速度。 当蓄水池满时(表现为当前请求/连接数超过设置的 burst 值),则返回错误信息 rejected。调用者需要丢掉溢出来的这部份。
下面是限制连接数的示例:
# nginx.conf
lua_code_cache on;
# 注意 limit_conn_store 的大小需要足够放置限流所需的键值。
# 每个 $binary_remote_addr 大小不会超过 16 字节(IPv6 情况下),算上 lua_shared_dict 的节点大小,总共不到 64 字节。
# 100M 可以放 1.6M 个键值对
lua_shared_dict limit_conn_store 100M;
server {
listen 8080;
location / {
access_by_lua_file src/access.lua;
content_by_lua_file src/content.lua;
log_by_lua_file src/log.lua;
}
}
-- utils/limit_conn.lua
local limit_conn = require "resty.limit.conn"
-- new 的第四个参数用于估算每个请求会维持多长时间,以便于应用漏桶算法
local limit, limit_err = limit_conn.new("limit_conn_store", 10, 2, 0.05)
if not limit then
error("failed to instantiate a resty.limit.conn object: ", limit_err)
end
local _M = {}
function _M.incoming()
local key = ngx.var.binary_remote_addr
local delay, err = limit:incoming(key, true)
if not delay then
if err == "rejected" then
return ngx.exit(503)
end
ngx.log(ngx.ERR, "failed to limit req: ", err)
return ngx.exit(500)
end
if limit:is_committed() then
local ctx = ngx.ctx
ctx.limit_conn_key = key
ctx.limit_conn_delay = delay
end
if delay >= 0.001 then
ngx.log(ngx.WARN, "delaying conn, excess ", delay,
"s per binary_remote_addr by limit_conn_store")
ngx.sleep(delay)
end
end
function _M.leaving()
local ctx = ngx.ctx
local key = ctx.limit_conn_key
if key then
local latency = tonumber(ngx.var.request_time) - ctx.limit_conn_delay
local conn, err = limit:leaving(key, latency)
if not conn then
ngx.log(ngx.ERR,
"failed to record the connection leaving ",
"request: ", err)
end
end
end
return _M
-- src/access.lua
local limit_conn = require "utils.limit_conn"
-- 对于内部重定向或子请求,不进行限制。因为这些并不是真正对外的请求。
if ngx.req.is_internal() then
return
end
limit_conn.incoming()
-- src/log.lua
local limit_conn = require "utils.limit_conn"
limit_conn.leaving()
注意在限制连接的代码里面,我们用 ngx.ctx 来存储 limit_conn_key。这里有一个坑。内部重定向(比如调用了 ngx.exec)会销毁 ngx.ctx,导致 limit_conn:leaving() 无法正确调用。 如果需要限连业务里有用到 ngx.exec,可以考虑改用 ngx.var 而不是 ngx.ctx,或者另外设计一套存储方式。只要能保证请求结束时能及时调用 limit:leaving() 即可。
限制请求数的实现差不多,这里就不赘述了。
OpenResty 如何引用第三方 resty 库
OpenResty 引用第三方 resty 库非常简单,只需要将相应的文件拷贝到 resty 目录下即可。
我们以 resty.http ( pintsized/lua-resty-http) 库为例。
只要将 lua-resty-http/lib/resty/ 目录下的 http.lua 和 http_headers.lua 两个文件拷贝到 /usr/local/openresty/lualib/resty 目录下即可(假设你的 OpenResty 安装目录为 /usr/local/openresty)。
验证代码如下:
server {
listen 8080 default_server;
server_name _;
resolver 8.8.8.8;
location /baidu {
content_by_lua_block {
local http = require "resty.http"
local httpc = http.new()
local res, err = httpc:request_uri("http://www.baidu.com")
if res.status == ngx.HTTP_OK then
ngx.say(res.body)
else
ngx.exit(res.status)
end
}
}
}
访问 http://127.0.0.1:8080/baidu , 如果出现的是百度的首页,说明你配置成功了。
当然这里也可以自定义 lua_package_path 指定 Lua 的查找路径,这样就可以把第三方代码放到相应的位置下,这么做更加方便归类文件,明确什么类型的文件放到什么地方(比如:公共文件、业务文件)。
OpenResty 怎样理解 cosocket
笔者认为,cosocket 是 OpenResty 世界中技术、实用价值最高部分。让我们可以用非常低廉的成本,优雅的姿势,比传统 socket 编程效率高好几倍的方式进行网络编程。无论资源占用、执行效率、并发能力都非常出色。
鲁迅有句名言“其实世界上本没有路,走的人多了便有了路”,其实对于 cosocket 的中文翻译貌似我也碰到了类似的问题。当我想给大家一个正面解释,爬过了官方 wiki 发现,原来作者本人(章亦春)也没有先给出 cosocket 定义。
看来只能通过一些侧面信息,从而让这条路逐渐的清晰起来。
cosocket = coroutine + socketcoroutine:协同程序(后面简称:协程) socket:网络套接字
OpenResty 中的 cosocket 不仅需要协程特性支撑,它还需 Nginx 非常最重要的“事件循环回调机制”,两部分结合在一起最终达到了 cosocket 效果,外加 Nginx 自身对各种资源的“小气”,LuaJIT 的执行效率,最终加分不少。在 Lua 世界中调用任何一个有关 cosocket 网络函数内部关键调用如图所示:
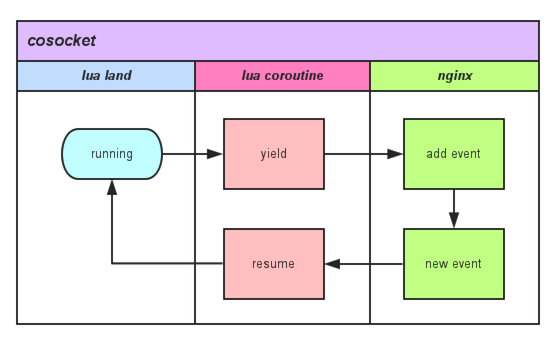
从该图中我们可以看到,用户的 Lua 脚本每触发一个网络操作,都会有协程的 yield 以及 resume,因为请求的 Lua 脚本实际上都运行在独享协程之上,可以在任何需要的时候暂停自己(yield),也可以在任何需要的时候被唤醒(resume)。
暂停自己,把网络事件注册到 Nginx 监听列表中,并把运行权限交给 Nginx。当有 Nginx 注册网络事件达到触发条件时,唤醒对应的协程继续处理。
以此为蓝图,封装实现 connect、read、receive 等操作,形成了大家目前所看到的 cosocket API。
可以看到,cosocket 是依赖 Lua 协程 + Nginx 事件通知两个重要特性拼的。
从 0.9.9 版本开始,cosocket 对象是全双工的,也就是说,一个专门读取的 "light thread",一个专门写入的 "light thread",它们可以同时对同一个 cosocket 对象进行操作(两个 "light threads" 必须运行在同一个 Lua 环境中,原因见上)。但是你不能让两个 "light threads" 对同一个 cosocket 对象都进行读(或者写入、或者连接)操作,否则当调用 cosocket 对象时,你将得到一个类似 "socket busy reading" 的错误。
所以东西总结下来,到底什么是 cosocket,中文应该怎么翻译,笔者本人都开始纠结了。我们不妨从另外一个角度来审视它,它到底给我们带来了什么。
- 它是同步的;
- 它是非阻塞的;
- 它是全双工的;
同步与异步解释: 同步:做完一件事再去做另一件; 异步:同时做多件事情,某个事情有结果了再去处理。阻塞与非阻塞解释: 阻塞:不等到想要的结果我就不走了; 非阻塞:有结果我就带走,没结果我就空手而回,总之一句话:爷等不起。
异步/同步是做事派发方式,阻塞/非阻塞是如何处理事情,两组概念不在同一个层面。
无论 ngx.socket.tcp()、ngx.socket.udp()、ngx.socket.stream()、ngx.req.socket(),它们基本流程都是一样的,只是一些细节参数上有区别(比如 TCP 和 UDP 的区别)。下面这些函数,都是用来辅助完成更高级的 socket 行为控制:
- connect
- sslhandshake
- send
- receive
- close
- settimeout
- setoption
- receiveuntil
- setkeepalive
- getreusedtimes
它们不仅完整兼容 LuaSocket 库的 TCP API,而且还是 100% 非阻塞的。
这里给大家 show 一个例子,对 cosocket 使用有一个整体认识。
location /test {
resolver 114.114.114.114;
content_by_lua_block {
local sock = ngx.socket.tcp()
local ok, err = sock:connect("www.baidu.com", 80)
if not ok then
ngx.say("failed to connect to baidu: ", err)
return
end
local req_data = "GET / HTTP/1.1\r\nHost: www.baidu.com\r\n\r\n"
local bytes, err = sock:send(req_data)
if err then
ngx.say("failed to send to baidu: ", err)
return
end
local data, err, partial = sock:receive()
if err then
ngx.say("failed to receive from baidu: ", err)
return
end
sock:close()
ngx.say("successfully talk to baidu! response first line: ", data)
}
}
可以看到,这里的 socket 操作都是同步非阻塞的,完全不像 node.js 那样充满各种回调,整体看上去非常简洁优雅,效率还非常棒。
对 cosocket 做了这么多铺垫,到底他有多么重要呢?直接看一下官方默认绑定包有多少是基于 cosocket 的:
- ngx_stream_lua_module Nginx "stream" 子系统的官方模块版本(通用的下游 TCP 对话)。
- lua-resty-memcached 基于 ngx_lua cosocket 的库。
- lua-resty-redis 基于 ngx_lua cosocket 的库。
- lua-resty-mysql 基于 ngx_lua cosocket 的库。
- lua-resty-upload 基于 ngx_lua cosocket 的库。
- lua-resty-dns 基于 ngx_lua cosocket 的库。
- lua-resty-websocket 提供 WebSocket 的客户端、服务端,基于 ngx_lua cosocket 的库。
效仿这些基础库的实现方法,可以完成不同系统或组件的对接,例如 syslog、beanstalkd、mongodb 等,直接 copy 这些组件的通讯协议即可。
OpenResty 如何只启动一个 timer 工作?
整个 OpenResty 启动后,我们有时候需要后台处理某些动作,比如数据定期清理、同步数据等。而这个后台任务实例我们期望是唯一并且安全,这里的安全指的是所有 Nginx worker 任意 crash 任何一个,有机制合理保证后续 timer 依然可以正常工作。
这里需要给大家介绍一个重要 API ngx.worker.id()。
语法: seq_id = ngx.worker.id()
返回当前 Nginx 工作进程的一个顺序数字(从 0 开始)。
所以,如果工作进程总数是 N,那么该方法将返回 0 和 N - 1 (包含)的一个数字。
该方法只对 Nginx 1.9.1+ 版本返回有意义的值。更早版本的 nginx,将总是返回 nil 。
解决办法
通过 API 描述可以看到,我们可以用它来确定这个 worker 的内部身份,并且这个身份是相对稳定的。即使当前 Nginx 进程因为某些原因 crash 了,新 fork 出来的 Nginx worker 是会继承这个 worker id 的。
剩下的问题就比较简单了,完全可以把我们的 timer 绑定到某个特定的 worker 上即可。 下面的例子,演示如何只在 worker.id 为 0 的进程上运行后台 timer。
init_worker_by_lua_block {
local delay = 3 -- in seconds
local new_timer = ngx.timer.at
local log = ngx.log
local ERR = ngx.ERR
local check
check = function(premature)
if not premature then
-- do the health check or other routine work
local ok, err = new_timer(delay, check)
if not ok then
log(ERR, "failed to create timer: ", err)
return
end
end
end
if 0 == ngx.worker.id() then
local ok, err = new_timer(delay, check)
if not ok then
log(ERR, "failed to create timer: ", err)
return
end
end
}OpenResty 使用动态 DNS 来完成 HTTP 请求
其实针对大多应用场景,DNS 是不会频繁变更的,使用 Nginx 默认的 resolver 配置方式就能解决。
对于部分应用场景,可能需要支持的系统众多:win、centos、ubuntu 等,不同的操作系统获取 DNS 的方法都不太一样。再加上我们使用 Docker,导致我们在容器内部获取 DNS 变得更加难以准确。
如何能够让 Nginx 使用随时可以变化的 DNS 源,成为我们急待解决的问题。
当我们需要在某一个请求内部发起这样一个 http 查询,采用 proxy_pass 是不行的(依赖 resolver 的 DNS,如果 DNS 有变化,必须要重新加载配置),并且由于 proxy_pass 不能直接设置 keepalive,导致每次请求都是短链接,性能损失严重。
使用 resty.http,目前这个库只支持 ip :port 的方式定义 url,其内部实现并没有支持 domain 解析。resty.http 是支持 set_keepalive 完成长连接,这样我们只需要让他支持 DNS 解析就能有完美解决方案了。
local resolver = require "resty.dns.resolver"
local http = require "resty.http"
function get_domain_ip_by_dns( domain )
-- 这里写死了google的域名服务ip,要根据实际情况做调整(例如放到指定配置或数据库中)
local dns = "8.8.8.8"
local r, err = resolver:new{
nameservers = {dns, {dns, 53} },
retrans = 5, -- 5 retransmissions on receive timeout
timeout = 2000, -- 2 sec
}
if not r then
return nil, "failed to instantiate the resolver: " .. err
end
local answers, err = r:query(domain)
if not answers then
return nil, "failed to query the DNS server: " .. err
end
if answers.errcode then
return nil, "server returned error code: " .. answers.errcode .. ": " .. answers.errstr
end
for i, ans in ipairs(answers) do
if ans.address then
return ans.address
end
end
return nil, "not founded"
end
function http_request_with_dns( url, param )
-- get domain
local domain = ngx.re.match(url, [[//([\S]+?)/]])
domain = (domain and 1 == #domain and domain[1]) or nil
if not domain then
ngx.log(ngx.ERR, "get the domain fail from url:", url)
return {status=ngx.HTTP_BAD_REQUEST}
end
-- add param
if not param.headers then
param.headers = {}
end
param.headers.Host = domain
-- get domain's ip
local domain_ip, err = get_domain_ip_by_dns(domain)
if not domain_ip then
ngx.log(ngx.ERR, "get the domain[", domain ,"] ip by dns failed:", err)
return {status=ngx.HTTP_SERVICE_UNAVAILABLE}
end
-- http request
local httpc = http.new()
local temp_url = ngx.re.gsub(url, "//"..domain.."/", string.format("//%s/", domain_ip))
local res, err = httpc:request_uri(temp_url, param)
if err then
return {status=ngx.HTTP_SERVICE_UNAVAILABLE}
end
-- httpc:request_uri 内部已经调用了keepalive,默认支持长连接
-- httpc:set_keepalive(1000, 100)
return res
end
动态 DNS,域名访问,长连接,这些都具备了,貌似可以安稳一下。在压力测试中发现这里面有个机制不太好,就是对于指定域名解析,每次都要和 DNS 服务会话询问 IP 地址,实际上这是不需要的。普通的浏览器,都会对 DNS 的结果进行一定的缓存,那么这里也必须要使用了。
OpenResty LuaRestyLock
缓存失效风暴
看下这个段伪代码:
local value = get_from_cache(key)
if not value then
value = query_db(sql)
set_to_cache(value, timeout = 100)
end
return value
看上去没有问题,在单元测试情况下,也不会有异常。
但是,进行压力测试的时候,你会发现,每隔 100 秒,数据库的查询就会出现一次峰值。如果你的 cache 失效时间设置的比较长,那么这个问题被发现的机率就会降低。
为什么会出现峰值呢?想象一下,在 cache 失效的瞬间,如果并发请求有 1000 条同时到了 query_db(sql) 这个函数会怎样?没错,会有 1000 个请求打向数据库。这就是缓存失效瞬间引起的风暴。它有一个英文名,叫 "dog-pile effect"。
怎么解决?自然的想法是发现缓存失效后,加一把锁来控制数据库的请求。具体的细节,春哥在 lua-resty-lock 的文档里面做了详细的说明,我就不重复了,请看这里。多说一句,lua-resty-lock 库本身已经替你完成了 wait for lock 的过程,看代码的时候需要注意下这个细节。
OpenResty 动态加载证书和 OCSP stapling
一个标准的 Nginx ssl 配置必然包含这两行:
ssl_certificate example.com.crt;
ssl_certificate_key example.com.key;
Nginx 启动时会读取配置的证书内容,并经过一系列解析后,最终通过调用 OpenSSL 的 SSL_use_certificate 来设置证书。 对于匹配的私钥,Nginx 调用的是 SSL_use_PrivateKey。
于是有了个新的想法:既然 OpenSSL 允许我们动态地设置证书和私钥,也许我们可以在建立连接前才设置证书和私钥呢? 这样一来,我们可以结合 SNI,针对不同的请求域名动态设置不同的证书和私钥,而无需事先把可能用到的证书和私钥都准备好。
动态加载证书
借助 OpenResty,我们可以轻易地把这个想法变成现实。 所需的,是 ssl_certificate_by_lua* 指令和来自 lua-resty-core 的 ngx.ssl 模块。另外,编译 OpenResty 时指定的 OpenSSL 需要 1.0.2e 或以上的版本。
见下面的示例代码:
server {
listen 443 ssl;
server_name test.com;
# 用于满足 Nginx 配置的占位符
ssl_certificate fake.crt;
ssl_certificate_key fake.key;
ssl_certificate_by_lua_block {
local ssl = require "ngx.ssl"
-- 清除之前设置的证书和私钥
local ok, err = ssl.clear_certs()
if not ok then
ngx.log(ngx.ERR, "failed to clear existing (fallback) certificates")
return ngx.exit(ngx.ERROR)
end
-- 后续代码见下文
}
}
证书/私钥的格式分两种,一种是文本格式的 PEM,另一种是二进制格式的 DER。我们看到的证书一般是 PEM 格式的。 这两种不同的格式,处理代码有所不同。
OpenResty API 的设计
OpenResty,最擅长的应用场景之一就是 API Server。如果我们只有简单的几个 API 出口、入口,那么我们可以相对随意简单一些。
举例几个简单API接口输出:
server {
listen 80;
server_name localhost;
location /app/set {
content_by_lua_block {
ngx.say('set data')
}
}
location /app/get {
content_by_lua_block {
ngx.say('get data')
}
}
location /app/del {
content_by_lua_block {
ngx.say('del data')
}
}
}
当你的 API Server 接口服务比较多,那么上面的方法显然不适合我们(太啰嗦)。这里推荐一下 REST 风格。
什么是 REST
从资源的角度来观察整个网络,分布在各处的资源由 URI 确定,而客户端的应用通过 URI 来获取资源的表示方式。获得这些表徵致使这些应用程序转变了其状态。随着不断获取资源的表示方式,客户端应用不断地在转变着其状态,所谓表述性状态转移(Representational State Transfer)。
这一观点不是凭空臆造的,而是通过观察当前 Web 互联网的运作方式而抽象出来的。Roy Fielding 认为,
设计良好的网络应用表现为一系列的网页,这些网页可以看作的虚拟的状态机,用户选择这些链接
导致下一网页传输到用户端展现给使用的人,而这正代表了状态的转变。
REST是设计风格而不是标准。
REST 通常基于使用 HTTP,URI,和 XML 以及 HTML 这些现有的广泛流行的协议和标准。
- 资源是由 URI 来指定。
- 对资源的操作包括获取、创建、修改和删除资源,这些操作正好对应 HTTP 协议提供的 GET、POST、PUT 和 DELETE 方法。
- 通过操作资源的表现形式来操作资源。
- 资源的表现形式则是 XML 或者 HTML,取决于读者是机器还是人,是消费 Web 服务的客户软件还是 Web 浏览器。当然也可以是任何其他的格式。
REST的要求
- 客户端和服务器结构
- 连接协议具有无状态性
- 能够利用 Cache 机制增进性能
- 层次化的系统
REST 使用举例
按照 REST 的风格引导,我们有关数据的 API Server 就可以变成这样。
server {
listen 80;
server_name localhost;
location /app/task01 {
content_by_lua_block {
ngx.say(ngx.req.get_method() .. ' task01')
}
}
location /app/task02 {
content_by_lua_block {
ngx.say(ngx.req.get_method() .. ' task02')
}
}
location /app/task03 {
content_by_lua_block {
ngx.say(ngx.req.get_method() .. ' task03')
}
}
}
对于 /app/task01 接口,这时候我们可以用下面的方法,完成对应的方法调用。
# curl -X GET http://127.0.0.1/app/task01
# curl -X PUT http://127.0.0.1/app/task01
# curl -X DELETE http://127.0.0.1/app/task01
还有办法压缩不?
上一个章节,如果 task 类型非常多,那么后面这个配置依然会随着业务调整而调整。其实每个程序员都有一定的洁癖,是否可以以后直接写业务,而不用每次都修改主配置,万一改错了,服务就起不来了。
引用一下 HttpLuaModule 官方示例代码。
# use nginx var in code path
# WARNING: contents in nginx var must be carefully filtered,
# otherwise there'll be great security risk!
location ~ ^/app/([-_a-zA-Z0-9/]+) {
set $path $1;
content_by_lua_file /path/to/lua/app/root/$path.lua;
}
这下世界宁静了,每天写 Lua 代码的同学,再也不用去每次修改 Nginx 主配置了。有新业务,直接开工。顺路还强制了入口文件命名规则。对于后期检查维护更容易。
REST 风格的缺点
需要一定的学习成本,如果你的接口是暴露给运维、售后、测试等不同团队,那么他们经常不去确定当时的 method。当他们查看、模拟的时候,具有一定学习难度。
REST 推崇使用 HTTP 返回码来区分返回结果, 但最大的问题在于 HTTP 的错误返回码 (4xx 系列为主) 不够多,而且订得很随意。比如用 API 创建一个用户,那么错误可能有:
- 调用格式错误(一般返回 400, 405)
- 授权错误(一般返回 403)
- "运行期"错误用户名冲突用户名不合法email 冲突email 不合法
OpenResty 数据合法性检测
对用户输入的数据进行合法性检查,避免错误非法的数据进入服务,这是业务系统最常见的需求。很可惜 Lua 目前没有特别好的数据合法性检查库。
坦诚我们自己做的也不够好,这里只能抛砖引玉,看看大家是否有更好办法。
我们有这么几个主要的合法性检查场景:
- JSON 数据格式
- 关键字段编码为 HEX(0-9,a-f,A-F),长度不定
- TABLE 内部字段类型
JSON 数据格式
这里主要是 json decode 时,可能抛出异常的问题。我们已经在 json 解析的异常捕获 一章中详细说明了问题本身以及解决方法,这里就不再重复。
关键字段编码为 HEX,长度不定
HEX 编码,最常见的存在有 MD5 值等。他们是由 0-9,A-F(或 a-f)组成。笔者把使用过的代码版本逐一罗列,并进行性能测试。通过这个测试,我们不仅仅可以收获参数校验的正确写法,以及可以再次印证一下效率最高的匹配,应该注意什么。
require "resty.core.regex"
-- 纯 lua 版本,优点是兼容性好,可以适用任何 lua 语言环境
function check_hex_lua( str )
if "string" ~= type(str) then
return false
end
for i = 1, #str do
local ord = str:byte(i)
if not (
(48 <= ord and ord <= 57) or
(65 <= ord and ord <= 70) or
(97 <= ord and ord <= 102)
) then
return false
end
end
return true
end
-- 使用 ngx.re.* 完成,没有使用任何调优参数
function check_hex_default( str )
if "string" ~= type(str) then
return false
end
return ngx.re.find(str, "[^0-9a-fA-F]") == nil
end
-- 使用 ngx.re.* 完成,使用调优参数 "jo"
function check_hex_jo( str )
if "string" ~= type(str) then
return false
end
return ngx.re.find(str, "[^0-9a-fA-F]", "jo") == nil
end
-- 下面就是测试用例部分代码
function do_test( name, fun )
ngx.update_time()
local start = ngx.now()
local t = "012345678901234567890123456789abcdefABCDEF"
assert(fun(t))
for i=1,10000*300 do
fun(t)
end
ngx.update_time()
print(name, "\ttimes:", ngx.now() - start)
end
do_test("check_hex_lua", check_hex_lua)
do_test("check_hex_default", check_hex_default)
do_test("check_hex_jo", check_hex_jo)
把上面的源码在 OpenResty 环境中运行,输出结果如下:
➜ resty test.lua
check_hex_lua times:1.0390000343323
check_hex_default times:5.1929998397827
check_hex_jo times:0.4539999961853
不知道这个结果大家是否有些意外,check_hex_default 的运行效率居然比 check_hex_lua 要差。不过所幸的是我们对正则开启了 jo 参数优化后,速度上有明显提升。
引用一下 ngx.re.* 官方 wiki 的原文:在优化性能时,o 选项非常有用,因为正则表达式模板将仅仅被编译一次,之后缓存在 worker 级的缓存中,并被此 Nginx worker 处理的所有请求共享。缓存数量上限可以通过 lua_regex_cache_max_entries 指令调整。
课后小作业:为什么测试用例中要使用 ngx.update_time() 呢?好好想一想。 课后小作业:在测试用例里面加了一行 require "resty.core.regex"。试试去掉这一行,重新跑下程序。结果怎么样?
TABLE 内部字段类型
当我们接收客户端请求,除了指定字段的特殊校验外,我们最常见的需求就是对指定字段的类型做限制了。比如用户注册接口,我们就要求对方姓名、邮箱等是个字符串,手机号、电话号码等是个数字类型,详细信息可能是个图片又或者是个嵌套的 TABLE。
例如我们接受用户的注册请求,注册接口示例请求 body 如下:
{
"username":"myname",
"age":8,
"tel":88888888,
"mobile_no":13888888888,
"email":"***@**.com",
"love_things":["football", "music"]
}
这时候可以用一个简单的字段描述格式来表达限制关系,如下:
{
"username":"",
"age":0,
"tel":0,
"mobile_no":0,
"email":"",
"love_things":[]
}
对于有效字段描述格式,数据值是不敏感的,但是数据类型是敏感的,只要数据类型能匹配,就可以让我们轻松不少。
来看下面的参数校验代码以及基本的测试用例:
function check_args_template(args, template)
if type(args) ~= type(template) then
return false
elseif "table" ~= type(args) then
return true
end
for k,v in pairs(template) do
if type(v) ~= type(args[k]) then
return false
elseif "table" == type(v) then
if not check_args_template(args[k], v) then
return false
end
end
end
return true
end
local args = {name="myname", tel=888888, age=18,
mobile_no=13888888888, love_things = {"football", "music"}}
print("valid check: ", check_args_template(args, {name="", tel=0, love_things={}}))
print("unvalid check: ", check_args_template(args, {name="", tel=0, love_things={}, email=""}))
运行一下上面的代码,结果如下:
➜ resty test.lua
valid check: true
unvalid check: false
可以看到,当我们业务层面需要有 email 地址但是请求方没有上送,这时候就能检测出来了。大家看到这里也许会笑,尤其是从其他成熟 web 框架中过来的同学,我们这里的校验可以说是比较粗糙简陋的,很多开源框架中的参数限制,都可以做到更加精确的限制。
如果你有更好更优雅的解决办法,欢迎与我们联系。
w3cschool-OpenResty 最佳实践Library的更多相关文章
- OpenResty 最佳实践 lua与nginx的结合 --引用自https://moonbingbing.gitbooks.io/openresty-best-practices/content/
系统的说明了lua在nginx上的开发 请大家到源址查看 OpenResty最佳实践
- OpenResty 最佳实践 1
建议先搜索<OpenResty最佳实践.pdf> 到网上下载openresty-1.13.6.1-win32 考虑到操作方便性,建议建立个bin目录,放入系统目录中,生成 nginx-st ...
- OpenResty 最佳实践 (2)
此文已由作者汤晓静授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. lua 协程与 nginx 事件机制结合 文章前部分用大量篇幅阐述了 lua 和 nginx 的相关知识,包 ...
- OpenResty 最佳实践
OpenResty 最佳实践 https://moonbingbing.gitbooks.io/openresty-best-practices/content/index.html
- 《OpenResty 最佳实践》学习开篇
前言:对openresty学习中,收集了一些相关知识的参考网站,有兴趣的可以看看.另附网盘分享. lua菜鸟教程 openresty最佳实战 lua在线解析工具 Nginx Lua API Nginx ...
- 转:OpenResty最佳实践(推荐了解lua语法)
看点: 1. Lua 语法的说明, 排版清晰易懂. 转: https://moonbingbing.gitbooks.io/openresty-best-practices/content/lua/m ...
- OpenResty 最佳实践 (1)
此文已由作者汤晓静授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. OpenResty 发展起源 OpenResty(也称为 ngx_openresty)是一个全功能的 Web ...
- 转: OpenResty最佳实践
https://moonbingbing.gitbooks.io/openresty-best-practices/content/ centOS安装另加内容 ln -sf luajit-2.1.0- ...
- OpenResty最佳实践
https://moonbingbing.gitbooks.io/openresty-best-practices/content/
- Openresty最佳案例 | 汇总
转载请标明出处: http://blog.csdn.net/forezp/article/details/78616856 本文出自方志朋的博客 目录 Openresty最佳案例 | 第1篇:Ngin ...
随机推荐
- 佛祖保佑永无 BUG 代码注释
// // _oo0oo_ // o8888888o // 88" . "88 // (| -_- |) // 0\ = /0 // ___/`---'\___ // .' \\| ...
- 【一步步开发AI运动小程序】二十一、如果将AI运动项目配置持久化到后端?
说明:本文所涉及的AI运动识别.计时.计数能力,都是基于云智「Ai运动识别引擎」实现.云智「Ai运动识别」插件识别引擎,可以为您的小程序或Uni APP赋于原生.本地.广覆盖.高性能的人体识别.姿态识 ...
- 不错的PHP扩展
不错的PHP扩展 ext name ext description ds data structure 提供list hash queue等数据结构 igbinary 数据压缩(速度快 压缩后内容小) ...
- Ansible常用功能说明 [异步、并发、委托等]
文章目录 Ansible的同步模式与异步模式 Ansible的异步和轮询 [async.poll] Ansible的并发限制 [serial.max_fail_percentage] Ansible的 ...
- Linux之EOF
常见问题: 1.在EOF中存在特殊字符,例如$ 导致后面的无法识别, 因为默认会对变量自动替换 使用引号处理 cat >> a.sh << "EOF" ec ...
- CudaSPONGE高性能GPU分子模拟
技术背景 CudaSPONGE是基于CUDA C开发的一款纯GPU分子动力学模拟软件,具有模块化和高性能的特点.官方基本介绍内容如下: 分子动力学(Molecular Dynamics, MD)模拟是 ...
- JavaScript 绑定this
1.临时改变函数调用时this的指向 方法:call()与apply(),第一个参数为此次调用时的this指向,如果不传,则则等同于指定全局对象,后面的参数为函数原本的参数 区别:apply()方法传 ...
- 正也科技案例 | 药企使用S2P深入营销管理数据化建设
为了获取更*的市场空间,医药健康行业正迎来一波前所未有的产业升级.尽管不少企业取得了许多成绩,但仍面临诸多挑战. 浙江某知名医药公司,在泌尿系统.心脑血管系统及眼科用药领域均拥有强势品牌.其产品更是荣 ...
- nvm切换版本报exec: “cmd”: executable file not found in %PATH% 问题
由于也是第一次用,出了个这报错懵了 搜了下也没个准确的解决办法(也可能是问题太简单),有的说可能是cmd变量没配好,检查了一遍没问题 后来想到报的是cmd,而cmd存储位置在 C:\Windows\S ...
- 【原创】PREEMPT-RT中断线程化原理与中断线程优先级设置
PREEMPT-RT中断线程化与中断线程优先级设置 目录 PREEMPT-RT中断线程化与中断线程优先级设置 一.什么是中断线程化 1. 普通Linux中断处理 2. 实时性的不足 3. 中断线程化 ...