python基于正则爬虫-小笔记
一、re.match(),从字符串的起始位置开始匹配,比如hello,匹配模式第一个字符必须为 h
1、re.match(),模式'^hello.*Demo$',匹配字符串符合正则的所有内容
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello.*Demo$',content)
print(result.group())
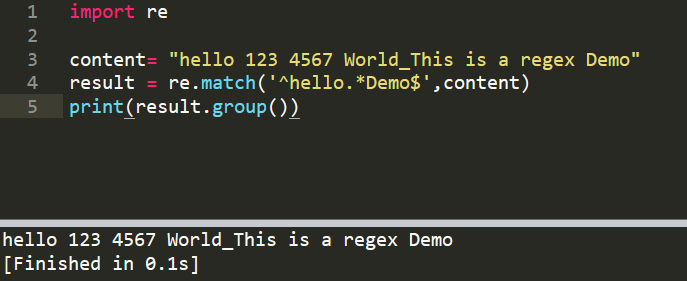
2、()、group(1),匹配字符串中的某个字符串,匹配数字 (\d+)
group()匹配全部,group(1)匹配第一个()
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello\s(\d+)\s(\d+)\sWorld.*Demo$',content)
print(result.group(2))
3、\s只能匹配一个空格,若有多个空格呢,hello 123,用 \s+ 即可
4、匹配空格、或任意字符串,.*,为贪婪模式,会影响后面的匹配,比如 .*(\d+),因此用 .*? 代替\s+
4.1 贪婪模式
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello.*(\d+)\s(\d+)\sWorld.*Demo$',content)
print(result.group(1))
输出 3
4.2 非贪婪模式
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello.*?(\d+).*?(\d+)\sWorld.*Demo$',content)
print(result.group(1))
输出123
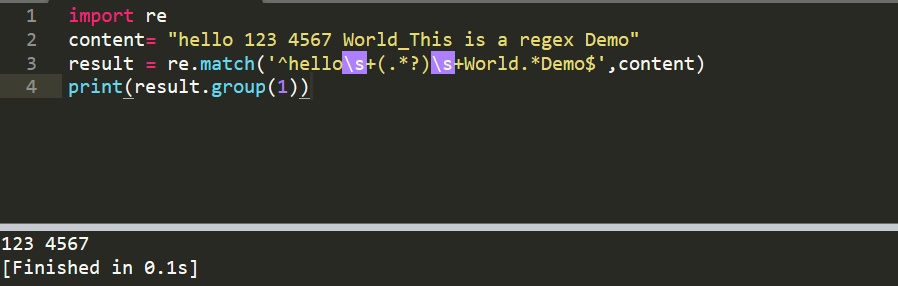
5、匹配 123 4567,(.*?)
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello\s+(.*?)\s+World.*Demo$',content)
print(result.group(1))
输出 123 4567
当匹配特殊字符时,用转义,$5.00,转为后 \$5\.00
二、re.search(),扫描整个字符串,比如hello,匹配模式第一个不一定必须为 h,可以是 e
网上其它文章写的比较混乱,没有写出re.match与re.search之间的区别,只是写了一个re.search使用案例,无法让新手朋友深入理解各个模式之间的区别
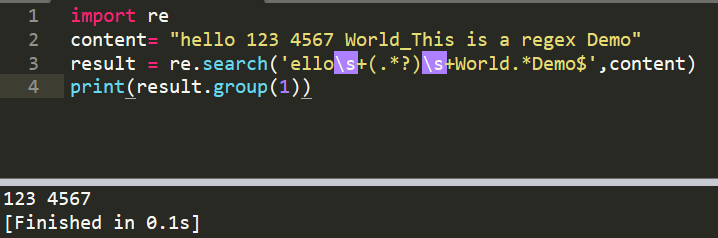
1、这里在用前面的案例,匹配 “123 4567”
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.search('ello\s+(.*?)\s+World.*Demo$',content) #从ello开始,re.match()必须从 h 开始
print(result.group(1))
输出 123 4567
2、匹配任意标签的内容,比如 <li data-view="4" class="active">,.*?active.*?xxxxx
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>',html,re.S) #当有多个 <li 时,唯有目标才有active,写入action即可指定此标签,.*?active.*?xxxxx
可以指定任意的标签,当active不同时,用正则re会比BeautifulSoup简单。
三、re.findall,列表语法来匹配字符串,不是 group(1)
以列表形式返回匹配的内容,语法与re.search一样
re.search:通过 group(1) 来匹配字符串
re.findall:通过列表语法来匹配字符串,不是 group(1)
re.findall('<li.*?active.*?singer="(.*?)">(.*?)</a>',html,re.S)
输出 [('齐秦', '往事随风')],列表内部是一个元组
print(result)
for x in result:
print(x[0]) #元组('齐秦', '往事随风'),对此元组的切片

四、re.compile
若多次复用某个写好的正则,用 re.compile("正则")
import re
content= """hello 12345 world_this
123 fan
"""
pattern =re.compile("hello.*fan",re.S)
result = re.match(pattern,content)
print(result)
print(result.group())
python基于正则爬虫-小笔记的更多相关文章
- Python 基于学习 网络小爬虫
<span style="font-size:18px;"># # 百度贴吧图片网络小爬虫 # import re import urllib def getHtml( ...
- 11.Python使用Scrapy爬虫小Demo(新手入门)
1.前提:已安装好scrapy,且已新建好项目,编写小Demo去获取美剧天堂的电影标题名 2.在项目中创建一个python文件 3.代码如下所示: import scrapy class movies ...
- Python 实现网络爬虫小程序
Python很简洁,也很强大,作为兴趣,值得一学! 下面这个程序实现的是从一个网站上下载图片,根据自己需要可以进行修改 import re import urllib def gethtml(ur ...
- python requests 正则爬虫
代码: import requests from multiprocessing import Pool from requests.exceptions import RequestExceptio ...
- 02 Python 函数的一些小笔记
函数的返回值 1.使用return可以返回多个值,如:return a,b 返回的数据类型是元组型2.接收返回的元组可以如:c,d=demo() (假设demo()返回a,b元组),需要注意的是,接收 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- 初探爬虫 ——《python 3 网络爬虫开发实践》读书笔记
零.背景 之前在 node.js 下写过一些爬虫,去做自己的私人网站和工具,但一直没有稍微深入的了解,借着此次公司的新项目,体系的学习下. 本文内容主要侧重介绍爬虫的概念.玩法.策略.不同工具的列举和 ...
- 基于python的pixiv爬虫
基于python的pixiv爬虫 1.目标 在和朋友吹逼过程中,聊到qq群机器人,突发奇想动手做一个p站每日推荐色图的色图机,遂学习爬虫. 目标: 批量下载首页推荐色图. 由于对qq机器人不熟,先利用 ...
- Python练习,网络小爬虫(初级)
最近还在看Python版的rcnn代码,附带练习Python编程写一个小的网络爬虫程序. 抓取网页的过程其实和读者平时使用IE浏览器浏览网页的道理是一样的.比如说你在浏览器的地址栏中输入 www ...
随机推荐
- FastAPI 核心机制:分页参数的实现与最佳实践
title: FastAPI 核心机制:分页参数的实现与最佳实践 date: 2025/3/13 updated: 2025/3/13 author: cmdragon excerpt: 在构建现代W ...
- 怎么给EXE文件加启动参数
第一步 首先右键单击 exe 文件文件,创建 exe 文件的快捷方式. 第二步 右键单击此快捷方式--属性. 在快捷方式属性界面,点击目标后面的链接. 先打一个空格然后输入参数,然后点击应用按钮.确定 ...
- Noise——随机之美
本篇博文介绍图形学中噪音生成的一般方法. Noise可以干什么? 不规则表面生成 有机体模拟 流体烟雾模拟 甚至是使用noise对灯光强度,位置做扰动: 只有我们想象不到的,没有noise不能涉猎的! ...
- spring 事务失效的 12 种场景
看这个:https://blog.csdn.net/hanjiaqian/article/details/120501741里面有12种失效场景以及如何解决. 在 spring 中为了支持编程式事务, ...
- Browser-use:基于 Python 的智能浏览器自动化 AI 工具调研与实战
Browser-use:基于 Python 的智能浏览器自动化 AI 工具调研与实战 一.概述 Browser-use 是一个旨在将 AI "智能体"(Agents)与真实浏览器进 ...
- configparser.ConfigParser
这是fens.conf里的初始内容: 下面是python3中configparser的处理原码:import configparsercf = configparser.ConfigParser()c ...
- 查看MySQL是否安装成功
1)安装了Windows Service:MySQL80,并且已经启动. 2)安装了MySQL软件.安装位置为:C:\Program Files\MySQL (默认路径) (MySQL文件下放的是软 ...
- 电商商品推荐系统实战:基于TensorFlow Recommenders构建智能推荐引擎
引言:推荐系统的商业价值与实现挑战 在电商领域,推荐系统承担着提升用户转化率和平台GMV的核心使命.根据麦肯锡研究,亚马逊35%的销售额来自推荐系统,Netflix用户75%的观看行为由推荐驱动.传统 ...
- 北京市第六届信息通信行业网络安全技能大赛(初赛)-CTF夺旗阶段 EZRSA writeup
题目EZRSA EZRSA.py from Crypto.Util.number import * import gmpy2 from flag import m p = getPrime(1024) ...
- Python3多线程
一.进程和线程 进程:是程序的一次执行,每个进程都有自己的地址空间.内存.数据栈及其他记录运行轨迹的辅助数据. 线程:所有的线程都运行在同一个进程当中,共享相同的运行环境.线程有开始.顺序执行和结束三 ...