kubernetes部署kafka集群
一.kafka介绍
kafka是一个分布式、多副本、多订阅者、分区的,基于zoopkeeper协调的分布式日志系统。其主要特点为:
1.以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上的数据也能保证常数时间的访问性能。
2.高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K消息的传输。
3.支持kafka server间的消息分区以及分布式消费,同时保证每个partition内的消息顺序和传输。
4.同时支持离线数据处理和实时数据处理。
二.应用场景
1.日志收集
2.数据推送
3.作为大缓冲区使用
4.服务中间件
三.应用架构
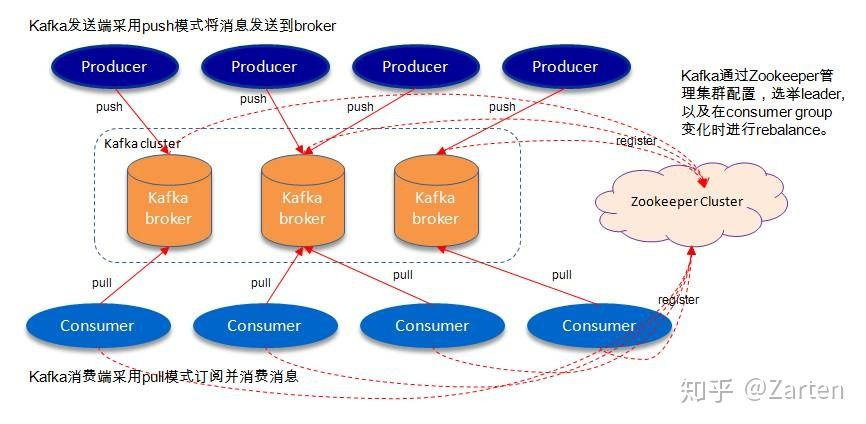
如上图所示,一个kafka集群包含若干个Producer(服务器日志、业务数据、Web前端产生的page view等),若干个Broker(kafka支持水平扩展,一般broker数量越多,集群的吞吐量越大),若干个consumer group,一个zookeeper集群(kafka通过zookeeper管理集群配置、选举leader、consumer group等发生变化时进行rebalance)。
3.1 名词解释
broker
消息中间件处理节点(服务器),一个节点就是一个broker,一个kafka集群由一个或多个broker组成Topic
kafka对消息进行归类,发送到集群的每一条消息都要指定一个topicPartition
物理上的概念,每个topic包含一个或多个partition,一个partition对应一个文件夹,这个文件夹下存储partition的数据和索引文件,每个partition内部是有序的。Producer
生产者,负责发布消息到brokerConsumer
消费者,从broker读取消息ConsumerGroup
每个consumer属于一个特定的consumer group,可为每个consumer指定group name,若不指定,则属于默认的group,一条消息可以发送到不同的consumer group,但一个consumer group中只能有一个consumer能消费这条消息。
四.kubernetes集群部署kafka
4.1 部署前准备
- 创建好的至少三个节点的kubernetes集群(这里我们使用的版本1.13.10)
- 创建好的存储类StorageClass(这里我们使用的是cephfs)
4.2 部署yaml文件
1.部署zookeeper的yaml文件
[root@k8s001 kafka]# cat zookeeper.yaml
apiVersion: v1
kind: Service
metadata:
name: zk-hs
namespace: kafka
labels:
app: zk
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: Service
metadata:
name: zk-cs
namespace: kafka
labels:
app: zk
spec:
ports:
- port: 2181
name: client
selector:
app: zk
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
namespace: kafka
spec:
selector:
matchLabels:
app: zk
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
namespace: kafka
spec:
selector:
matchLabels:
app: zk
serviceName: zk-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: Parallel
template:
metadata:
labels:
app: zk
spec:
nodeSelector:
travis.io/schedule-only: "kafka"
tolerations:
- key: "travis.io/schedule-only"
operator: "Equal"
value: "kafka"
effect: "NoSchedule"
- key: "travis.io/schedule-only"
operator: "Equal"
value: "kafka"
effect: "NoExecute"
tolerationSeconds: 3600
- key: "travis.io/schedule-only"
operator: "Equal"
value: "kafka"
effect: "PreferNoSchedule"
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
containers:
- name: kubernetes-zookeeper
imagePullPolicy: IfNotPresent
image: fastop/zookeeper:3.4.10
resources:
requests:
memory: "200Mi"
cpu: "0.1"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
# 这里我们需要将runAsuser和fsGroup用户调整为0,也就是管理员用户允许,否则会提示权限的报错
securityContext:
runAsUser: 0
fsGroup: 0
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: cephfs
resources:
requests:
storage: 20Gi
2.部署kafka的yaml文件
[root@k8s001 kafka]# cat kafka.yaml
---
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
namespace: kafka
labels:
app: kafka
spec:
ports:
- port: 9092
name: server
clusterIP: None
selector:
app: kafka
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: kafka-pdb
namespace: kafka
spec:
selector:
matchLabels:
app: kafka
minAvailable: 2
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
namespace: kafka
spec:
selector:
matchLabels:
app: kafka
serviceName: kafka-svc
replicas: 3
template:
metadata:
labels:
app: kafka
spec:
nodeSelector:
travis.io/schedule-only: "kafka"
tolerations:
- key: "travis.io/schedule-only"
operator: "Equal"
value: "kafka"
effect: "NoSchedule"
- key: "travis.io/schedule-only"
operator: "Equal"
value: "kafka"
effect: "NoExecute"
tolerationSeconds: 3600
- key: "travis.io/schedule-only"
operator: "Equal"
value: "kafka"
effect: "PreferNoSchedule"
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- kafka
topologyKey: "kubernetes.io/hostname"
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
terminationGracePeriodSeconds: 300
containers:
- name: k8s-kafka
imagePullPolicy: IfNotPresent
image: fastop/kafka:2.2.0
resources:
requests:
memory: "600Mi"
cpu: 500m
ports:
- containerPort: 9092
name: server
command:
- sh
- -c
- "exec kafka-server-start.sh /opt/kafka/config/server.properties --override broker.id=${HOSTNAME##*-} \
--override listeners=PLAINTEXT://:9092 \
--override zookeeper.connect=zk-0.zk-hs.kafka.svc.cluster.local:2181,zk-1.zk-hs.kafka.svc.cluster.local:2181,zk-2.zk-hs.kafka.svc.cluster.local:2181 \
--override log.dir=/var/lib/kafka \
--override auto.create.topics.enable=true \
--override auto.leader.rebalance.enable=true \
--override background.threads=10 \
--override compression.type=producer \
--override delete.topic.enable=false \
--override leader.imbalance.check.interval.seconds=300 \
--override leader.imbalance.per.broker.percentage=10 \
--override log.flush.interval.messages=9223372036854775807 \
--override log.flush.offset.checkpoint.interval.ms=60000 \
--override log.flush.scheduler.interval.ms=9223372036854775807 \
--override log.retention.bytes=-1 \
--override log.retention.hours=168 \
--override log.roll.hours=168 \
--override log.roll.jitter.hours=0 \
--override log.segment.bytes=1073741824 \
--override log.segment.delete.delay.ms=60000 \
--override message.max.bytes=1000012 \
--override min.insync.replicas=1 \
--override num.io.threads=8 \
--override num.network.threads=3 \
--override num.recovery.threads.per.data.dir=1 \
--override num.replica.fetchers=1 \
--override offset.metadata.max.bytes=4096 \
--override offsets.commit.required.acks=-1 \
--override offsets.commit.timeout.ms=5000 \
--override offsets.load.buffer.size=5242880 \
--override offsets.retention.check.interval.ms=600000 \
--override offsets.retention.minutes=1440 \
--override offsets.topic.compression.codec=0 \
--override offsets.topic.num.partitions=50 \
--override offsets.topic.replication.factor=3 \
--override offsets.topic.segment.bytes=104857600 \
--override queued.max.requests=500 \
--override quota.consumer.default=9223372036854775807 \
--override quota.producer.default=9223372036854775807 \
--override replica.fetch.min.bytes=1 \
--override replica.fetch.wait.max.ms=500 \
--override replica.high.watermark.checkpoint.interval.ms=5000 \
--override replica.lag.time.max.ms=10000 \
--override replica.socket.receive.buffer.bytes=65536 \
--override replica.socket.timeout.ms=30000 \
--override request.timeout.ms=30000 \
--override socket.receive.buffer.bytes=102400 \
--override socket.request.max.bytes=104857600 \
--override socket.send.buffer.bytes=102400 \
--override unclean.leader.election.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false \
--override broker.id.generation.enable=true \
--override connections.max.idle.ms=600000 \
--override controlled.shutdown.enable=true \
--override controlled.shutdown.max.retries=3 \
--override controlled.shutdown.retry.backoff.ms=5000 \
--override controller.socket.timeout.ms=30000 \
--override default.replication.factor=1 \
--override fetch.purgatory.purge.interval.requests=1000 \
--override group.max.session.timeout.ms=300000 \
--override group.min.session.timeout.ms=6000 \
--override inter.broker.protocol.version=2.2.0 \
--override log.cleaner.backoff.ms=15000 \
--override log.cleaner.dedupe.buffer.size=134217728 \
--override log.cleaner.delete.retention.ms=86400000 \
--override log.cleaner.enable=true \
--override log.cleaner.io.buffer.load.factor=0.9 \
--override log.cleaner.io.buffer.size=524288 \
--override log.cleaner.io.max.bytes.per.second=1.7976931348623157E308 \
--override log.cleaner.min.cleanable.ratio=0.5 \
--override log.cleaner.min.compaction.lag.ms=0 \
--override log.cleaner.threads=1 \
--override log.cleanup.policy=delete \
--override log.index.interval.bytes=4096 \
--override log.index.size.max.bytes=10485760 \
--override log.message.timestamp.difference.max.ms=9223372036854775807 \
--override log.message.timestamp.type=CreateTime \
--override log.preallocate=false \
--override log.retention.check.interval.ms=300000 \
--override max.connections.per.ip=2147483647 \
--override num.partitions=4 \
--override producer.purgatory.purge.interval.requests=1000 \
--override replica.fetch.backoff.ms=1000 \
--override replica.fetch.max.bytes=1048576 \
--override replica.fetch.response.max.bytes=10485760 \
--override reserved.broker.max.id=1000 "
env:
- name: KAFKA_HEAP_OPTS
value : "-Xmx512M -Xms512M"
- name: KAFKA_OPTS
value: "-Dlogging.level=INFO"
volumeMounts:
- name: datadir
mountPath: /var/lib/kafka
readinessProbe:
tcpSocket:
port: 9092
timeoutSeconds: 1
initialDelaySeconds: 5
securityContext:
runAsUser: 1000
fsGroup: 1000
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: cephfs
resources:
requests:
storage: 20Gi
4.3 部署
这里zookeeper和kafka都是有状态的服务,不能使用deployment和rc这种控制器来部署,这里我们使用statefulset来部署zookeeper和kafka服务。
4.3.1 给节点打标签
这里我们想在哪几台机器上来运行kafka,需要对节点进行打标签。
kubectl label node [node-name] travis.io/schedule-only=kafka
当然,如果我们如果不想在哪些节点运行kafka,可以通过配置污点来进行。
kubectl taint node [node-name] travis.io/schedule-only=kafka:NoSchedule
4.3.2 创建命名空间
[root@k8s001 kafka]# kubectl create ns kafka
4.3.3 创建zookeeper服务
# 创建zookeeper服务
[root@k8s001 kafka]# kubectl apply -f zookeeper.yaml
# 查看zookeeper服务运行状态
[root@k8s001 kafka]# kubectl get pod -n kafka
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 0 7m8s
zk-1 1/1 Running 0 7m8s
zk-2 1/1 Running 0 7m8s
4.3.4 创建kafka服务
[root@k8s001 kafka]# kubectl apply -f kafka.yaml
[root@k8s001 kafka]# kubectl get pod -n kafka
NAME READY STATUS RESTARTS AGE
kafka-0 1/1 Running 0 11m
kafka-1 1/1 Running 0 11m
kafka-2 1/1 Running 0 10m
zk-0 1/1 Running 0 6m44s
zk-1 1/1 Running 0 6m44s
zk-2 1/1 Running 0 6m44s
4.3.5 测试
测试zookeeper:
kubectl exec -it zk-0 -n kafka -- zkServer.sh status
kubectl exec -it zk-0 -n kafka -- zkCli.sh create /hello world
kubectl delete -f zookeeper.yaml
kubectl apply -f zookeeper.yaml
kubectl exec -it zk-0 -n kafka -- zkCli.sh get /hello
测试kafka:
kubectl exec -it kafka-0 -n kafka -- bash
>kafka-topics.sh --create \
--topic test \
--zookeeper zk-0.zk-hs.kafka.svc.cluster.local:2181,zk-1.zk-hs.kafka.svc.cluster.local:2181,zk-2.zk-hs.kafka.svc.cluster.local:2181 \
--partitions 3 \
--replication-factor 2
kafka-topics.sh --list --zookeeper zk-0.zk-hs.kafka.svc.cluster.local:2181,zk-1.zk-hs.kafka.svc.cluster.local:2181,zk-2.zk-hs.kafka.svc.cluster.local:2181
kafka-console-consumer.sh --topic test --bootstrap-server localhost:9092
# 另起一个窗口,进入kafka-1容器
kubectl exec -it kafka-1 -n kafka -- bash
>kafka-console-producer.sh --topic test --broker-list localhost:9092
随便输入内容,观察kafka-0启动的kafka-console-consumer.sh的输出。
kubernetes部署kafka集群的更多相关文章
- docker部署kafka集群
利用docker可以很方便的在一台机子上搭建kafka集群并进行测试.为了简化配置流程,采用docker-compose进行进行搭建. kafka搭建过程如下: 编写docker-compose.ym ...
- Kafka实战(七) - 优雅地部署 Kafka 集群
既然是集群,必然有多个Kafka节点,只有单节点构成的Kafka伪集群只能用于日常测试,不可能满足线上生产需求. 真正的线上环境需要考量各种因素,结合自身的业务需求而制定.看一些考虑因素(以下顺序,可 ...
- 使用docker-compose部署Kafka集群
之前写过Kafka集群的部署,不过那是基于宿主机的,地址:Kafka基础教程(二):Kafka安装 和Zookeeper一样,有时想简单的连接Kafka用一下,那就需要开好几台虚拟机,如果Zookee ...
- 【kafka】安装部署kafka集群(kafka版本:kafka_2.12-2.3.0)
3.2.1 下载kafka并安装kafka_2.12-2.3.0.tgz tar -zxvf kafka_2.12-2.3.0.tgz 3.2.2 配置kafka集群 在config/server.p ...
- 利用zookeeper部署kafka集群
1.准备工作: iptables -F #关闭防火墙 systemctl stop firewalld.service #关闭防火墙 准备三台虚拟机并放入/etc/hosts下 192.16 ...
- docker下部署kafka集群(多个broker+多个zookeeper)
网上关于kafka集群的搭建,基本是单个broker和单个zookeeper,测试研究的意义不大.于是折腾了下,终于把正宗的Kafka集群搭建出来了,在折腾中遇到了很多坑,后续有时间再专门整理份搭建问 ...
- 安装部署Kafka集群
kafka是一个开源的分布式消息订阅系统(消息中间件) 安装过程 1.下载kafka_2.11-0.10.1.0.gz(ps:千万不要下错了,博主就是下到了src文件上去了,kafka中的zookee ...
- kubernetes部署 etcd 集群
本文档介绍部署一个三节点高可用 etcd 集群的步骤: etcd 集群各节点的名称和 IP 如下: kube-node0:192.168.111.10kube-node1:192.168.111.11 ...
- k8s部署kafka集群
一.概述 在k8s里面部署kafka.zookeeper这种有状态的服务,不能使用deployment和RC,k8s提供了一种专门用来部署这种有状态的服务的API--statefulset,有状态简单 ...
- 在kubernetes上部署zookeeper,kafka集群
本文采用网上镜像:mirrorgooglecontainers/kubernetes-zookeeper:1.0-3.4.10 准备共享存储:nfs,glusterfs,seaweed或其他,并在no ...
随机推荐
- OpenGL与GLSL各版本对应说明
OpenGL 4.6 (API Core Profile) (API Compatibility Profile) OpenGL Shading Language 4.60 Specification ...
- [源码系列:手写spring] IOC第三节:Bean实例化策略InstantiationStrategy
主要内容 在第二节中AbstractAutowireCapableBeanFactory类中使用class.newInstance()的方式创建实例,仅适用于无参构造器. 大家可以测试一下,将第二节 ...
- linux中安装firebird
本在树莓派上安装sqlite,因为sqlite的多用户需要自己控制读写.最终选择稳定够用的fb2.5. 嵌入式无论哪一种fb都差不多. 1.安装 sudo apt-get install firebi ...
- SMU Autumn 2024 Trial 1
A. Load Balancing 很明显题意要的就是让我们把每个数往平均值靠,这样就保证最大值-最小值最小 但是当sum%n !=0的时候就说明无法每个数都等于sum/n,所以处理的方法就是,先计算 ...
- ubuntu 安装挂载mysql, redis和mongodb服务
因为有两台电脑,所以准备把ubuntu电脑作成对外服务提供,各种数据库,中间件都使用docker安装管理,然后挂载配置和日志到本地,提供给另一台电脑的对外服务. 1. 安装docker sudo ap ...
- lua三色标记的读写屏障理解
起因是已经被标记为黑色的对象无法进行再次遍历,然而黑色对象发生了引用变化:断开了引用或者引用了别的对象,会导致多标(不再被黑色对象引用的对象未能回收),漏标(黑色对象的新引用未能遍历标记)
- Spring Cloud Gateway网关
一.Spring Cloud Gateway组件的核心是一系列的过滤器,通过这些过滤器可以将客户端发送的请求由(路由)转发到对应的微服务 网关的执行过程:当一个请求到达网关,网关利用断言,查看该请求是 ...
- 看了他,妈妈再也不用担心我被问到Mybatis缓存了
Mybatis缓存 一.一级缓存 1. 概念 sqlsession级别的缓存,即缓存的是SQL语句 同一个sqlsession中执行多次查询条件相同的SQL,mybatis会提供一级缓存进行优化 2. ...
- 搭建zookeeper集群常见的报错原因(总结)
N.1 报错:Connection broken for id 2, my id = 3, error = java.io.IOException: Channel eof ... 原因:server ...
- 银河麒麟v10 sysctl内核参数加载顺序的思考
背景 最近很多伙伴想使用银河麒麟高级服务器系统v10来部署最新版本的k8s集群,可能遇到了各式各样的问题,于是准备使用kylinOS v10重温一遍kubeadm部署最新版本k8s的流程,也是替大家踩 ...