Java的"伪泛型"变"真泛型"后,会对性能有帮助吗?
泛型存在于Java源代码中,在编译为字节码文件之前都会进行泛型擦除(type erasure),因此,Java的泛型完全由Javac等编译器在编译期提供支持,可以理解为Java的一颗语法糖,这种方式实现的泛型有时也称为“伪泛型”。
泛型擦除本质上就是擦除与泛型相关的一切信息,例如参数化类型、类型变量等,Javac还将在需要时进行类型检查及强制类型转换,甚至在必要时会合成桥方法。
1、真假泛型
如果你是Java业务开发者,其实这种所谓的伪泛型已经达到了方便使用的目的,例如在容器的使用过程中,能够记住其类型,这样就不用在获取时专门做强制类型转换了,如下:
package cn.hotspotvm;
class Wrapper<T> {
public T data;
public void setData(T data) {
this.data = data;
}
public T getData(){
return data;
}
}
public class TestGeneric {
public static void main(String[] args) {
Wrapper<Integer> p = new Wrapper<>();
p.setData(new Integer(2));
// 在获取的时候不用进行强制类型转换,直接用
// Integer接收即可
Integer data = p.getData();
System.out.println(data);
}
}
泛型尤其在我们使用容器类,如ArrayList、 HashMap等时能提供便利。
假设Java不支持泛型,那么我们针对Integer类型进行封装的Wrapper代码应该是如下的样子:
class Wrapper{
public int data;
public void setData(int data) {
this.data = data;
}
public Object getData(){
return data;
}
}
public class TestGeneric {
public static void main(String[] args) {
Wrapper p = new Wrapper();
p.setData(2);
int data = p.getData();
System.out.println(data);
}
}
这个Wrapper明显是只能对int类型进行封装,不过其实现和之前比起来要简洁,不但实例字段内存占用减少,还没有了装箱和拆箱操作,也省去了强制类型转换。这也是我们在使用Java泛型时希望看到的版本。
以目前Java的实现来看,是对泛型进行擦除处理的,对Wrapper类型进行擦除后的代码如下所示。
class Wrapper{
public Object data;
public void setData(Object data) {
this.data = data;
}
public Object getData(){
return data;
}
}
public class TestGeneric {
public static void main(String[] args) {
Wrapper p = new Wrapper();
p.setData(2);
// 必须进行强制类型转换为Integer
Integer data = (Integer)p.getData();
System.out.println(data);
}
}
由于在整个应用中,无论是Wrapper还是Wrapper这些类型来说,其Wrapper在虚拟机中只有一个版本,因为需要对任何的Java对象进行封装,所以声明为Object,当然如果你知道只会放某个更具体的类或这个类的子类时,也可以将Wrapper类型声明的更精确一些,如Wrapper。
假设像C++的模板类一样,Java的“真泛型”也为每一个具体的泛型生成一个独有的类(类型膨胀式泛型),那么就如下图所示。
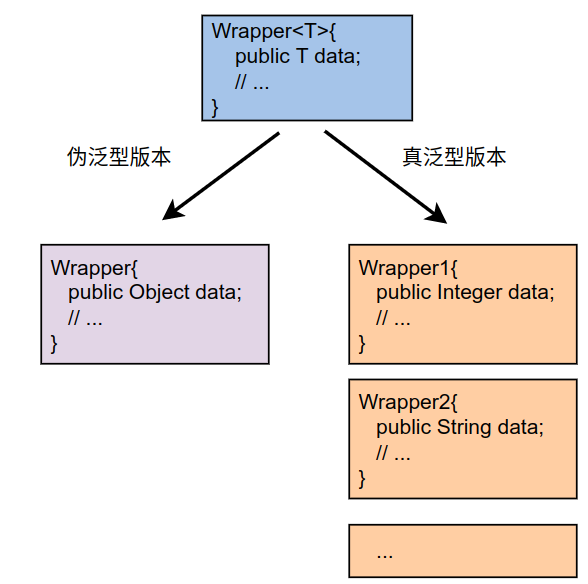
可以看到,真泛型会针对具体的类型生成独有的类型。针对Wrapper就应该有是这样:
class Wrapper{
public Integer data;
public void setData(Integer data) {
this.data = data;
}
public Integer getData(){
return data;
}
}
public class TestGeneric {
public static void main(String[] args) {
Wrapper p = new Wrapper();
p.setData(2);
Integer data = p.getData();
System.out.println(data);
}
}
这次类型非常精确,也没有了强制类型转换。不过与我们理想中的还有差距,主要是没有将Wrapper中的类型声明为基本类型int,这会导致装箱和拆箱操作。在Java中,装箱和拆箱操作很频繁,为此JDK开发人员也在努力优化,如延迟装箱等,现在,Project Valhalla要让泛型能支持原始类型。好在除非是专门做优化的人,否则一般开发者也不会注意到这种装箱和拆箱的开销。
这里还要说的是,由于对象和基本类型找不到一个共同的父类,所以在泛型擦除时只能是对象类型,也就是说,我们不能在Java中写一个类似Wrapper这样的声明。这篇文章我们暂时不讨论这个问题,我们讨论另外一个重要的问题,也就是为任何一个泛型生成一个真正的类与这种伪泛型的擦除之间会造成哪些性能影响?
2、性能影响
我们举几个小例子来看一下:
实例1
class SpecWrapper extends Wrapper<Integer> {
public void setData(Integer data) { }
}
我们自定义了一个对Integer类封装的SpecWrapper类,这个类在泛型擦除后如下所示。
class SpecWrapper extends Wrapper {
public void setData(Integer data) { }
/*synthetic*/ public void setData(Object x0) { // 合成的桥方法
this.setData((Integer)x0);
}
}
在泛型擦除后,Wrapper类的setData()方法的类型变量T被替换为Object类型,这样SpecWrapper类中的setData(Integer data)并没有覆写这个方法,所以为了覆写特性,向SpecWrapper类中添加一个合成的桥方法setData(Objext x0)。
这会让我们在实际调用setData()方法时调用的是setData(Object x0)方法,这个方法又调用了setData(Integer data)方法,而在“真泛型”中,我们直接调用setData(Integer data)方法即可,虽然JIT会大概率对这种简单的方法进行内联,但是性能影响肯定是有的。
实例2
class Parent {
public static int a = 0;
public void invoke() {
a = 1;
}
}
final class Sub1 extends Parent {
public void invoke() {
a = 2;
}
}
public class TestGeneric<T extends Parent> {
T t;
public TestGeneric(T t1) {
this.t = t1;
}
public static void main(String[] args)
throws InterruptedException {
TestGeneric<Sub1> s
= new TestGeneric<>(new Sub1());
// 调用test()方法超过一定次数会分别触发C1和C2编译
for (int i = 0; i < 100000; i++) {
s.test();
}
// 等待异常的编译线程编译完并打印结果
Thread.sleep(10000);
}
public void test() {
t.invoke();
}
}
我们关注一下test()方法中的t.invoke()动态分派,通过泛型擦除之后,TestGeneric类中的T是Parent类型,那么test()方法中t声明的类型就是Parent,如下:
public class TestGeneric{
Parent t;
public TestGeneric(Parent t1) {
this.t = t1;
}
public void test() {
t.invoke();
}
}
配置如下命令查看C2编译的结果:
XX:CompileCommand=compileonly,cn/hotspotvm/TestGeneric::test -XX:CompileCommand=print,cn/hotspotvm/TestGeneric::test
C2编译的版本出来如下:
0x000070e6e00aa915: cmp $0xf800c184,%r8d ; {metadata('cn/hotspotvm/Sub1')}
0x000070e6e00aa91c: jne 0x000070e6e00aa934
0x000070e6e00aa91e: lea (%r12,%r10,8),%rsi
0x000070e6e00aa922: nop
0x000070e6e00aa923: callq 0x000070e6dfe45e60 ; OopMap{off=72}
;*invokevirtual invoke
; - cn.hotspotvm.TestGeneric::test@4 (line 39)
; {optimized virtual_call}
0x000070e6e00aa928: add $0x10,%rsp
0x000070e6e00aa92c: pop %rbp
0x000070e6e00aa92d: test %eax,0x165cb6cd(%rip) # 0x000070e6f6676000
; {poll_return}
0x000070e6e00aa933: retq
0x000070e6e00aa934: mov $0xffffffde,%esi
0x000070e6e00aa939: mov %r10d,%ebp
0x000070e6e00aa93c: data32 xchg %ax,%ax
0x000070e6e00aa93f: callq 0x000070e6dfe45460 ; OopMap{rbp=NarrowOop off=100}
;*invokevirtual invoke
; - cn.hotspotvm.TestGeneric::test@4 (line 39)
; {runtime_call}
也就等同于如下:
if(t是Sub1类型){
直接调用Sub1的invoke()方法,也就是optimized virtual_call的意思
}else{
动态分派,通过查找方法表来实现调用,也就是invokevirtual invoke的意思
}
C2实际是通过运行时采样,发现t的类型只有Sub1,所以做了这样的优化,将动态分派优化为了一次比较+一次直接调用的开销。
假设是“真泛型”上场,那TestGeneric应该是如下的样子:
public class TestGeneric{
Sub1 t;
public TestGeneric(Sub1 t1) {
this.t = t1;
}
public void test() {
t.invoke();
}
}
此时C2编译出来的版本如下:
0x000074bd840b7b5b: callq 0x000074bd83e45e60 ; OopMap{off=64}
;*invokevirtual invoke
; - cn.hotspotvm.TestGeneric::test@4 (line 39)
; {optimized virtual_call}
直接就是直调,比之前省了一次判断,代码很简洁。因为C2得到了t的更精确类型Sub1,并且这个Sub1还是final修饰的类,不会有子类,所以直接调用即可。
虽然少量调用可能并不能体现出来差异,更何况现在的C2优化实在强大,使得它们的性能差异可能只在极少数的情况下才能体现出来。
C2编译器非常喜欢精确类型,这样在类型传播的过程中能触发许多优化,编译出性能更好的版本,后续我们在介绍C2时,看一看其类型传播,就能深刻体会到它的强大。
实例3
假设有这么一个方法,实现如下:
class Parent{
// ...
}
find class Sub1 extends Parent{
// ...
}
class Sub2 extends Parent{
// ...
}
public class Wrapper<T extends Parent>{
public void test(T t){
if(t instanceof Sub1){
// 执行Sub1的逻辑
}else if( t instanceof Sub2){
// 执行Sub2的逻辑
}else{
// 执行其它类型的逻辑
}
}
}
对于伪泛型来说,擦除后,T是Parent类型。方法test(Parent t)无法做任何优化。
对于真泛型来说,至少Wrapper和Wrapper版本中的test()是可以优化的。
public void test(Sub1 t)版本中只需要直接执行Sub1的逻辑就可以,并不需要判断,因为Sub1是final类,所以t只能是Sub1类型,如下:
public void test(Sub1 t){
执行Sub1的逻辑
}
public void test(Sub2 t)版本中只需要直接执行Sub2的逻辑就可以,并不需要判断,虽然Sub2是非final类型,但是经过类层次分析后发现,Sub2没有具体的实现子类,那这时候也能认为这个版本只有Sub2类型。
public void test(Sub2 t){
执行Sub2的逻辑
}
如果你想了解下Java为啥不支持这种类型的泛型,可以参考
R大在知乎的回答
简单来说,就是为了高版本的兼容性做了一种妥协的策略而已。
更多文章可访问:JDK源码剖析网

Java的"伪泛型"变"真泛型"后,会对性能有帮助吗?的更多相关文章
- 重读《深入理解Java虚拟机》六、Java泛型 VS C#泛型 (伪泛型 VS 真泛型)
一.泛型的本质 泛型是参数化类型的应用,操作的数据类型不限定于特定类型,可以根据实际需要设置不同的数据类型,以实现代码复用. 二.Java泛型 Java 泛型是Java1.5新增的特性,JVM并不支持 ...
- C#的泛型和Java的伪泛型
C#的泛型和java的伪泛型,talk is cheap,show me the code C#泛型 下面结果,C#里面会输出false,如果这个还不能真正的说明C#的泛型是真的泛型,那就看下面这 ...
- Java 集合、Iterator迭代器、泛型等
01集合使用的回顾 A:集合使用的回顾 a.ArrayList集合存储5个int类型元素 public static void main(String[] args) { ArrayList<I ...
- Java中泛型区别以及泛型擦除详解
一.引言 复习javac的编译过程中的解语法糖的时候看见了泛型擦除中的举例,网上的资料大多比较散各针对性不一,在此做出自己的一些详细且易懂的总结. 二.泛型简介 泛型是JDK 1.5的一项新特性,一种 ...
- 《徐徐道来话Java》(2):泛型和数组,以及Java是如何实现泛型的
数组和泛型容器有什么区别 要区分数组和泛型容器的功能,这里先要理解三个概念:协变性(covariance).逆变性(contravariance)和无关性(invariant). 若类A是类B的子类, ...
- 《徐徐道来话Java》(1):泛型的基本概念
泛型是一种编程范式(Programming Paradigm),是为了效率和重用性产生的.由Alexander Stepanov(C++标准库主要设计师)和David Musser(伦斯勒理工学院CS ...
- Java泛型总结——吃透泛型开发
什么是泛型 泛型是jdk5引入的类型机制,就是将类型参数化,它是早在1999年就制定的jsr14的实现. 泛型机制将类型转换时的类型检查从运行时提前到了编译时,使用泛型编写的代码比杂乱的使用objec ...
- java反射--通过反射了解集合泛型的本质
通过Class,Method来认识泛型的本质 package com.reflect; import java.lang.reflect.Method; import java.util.ArrayL ...
- Java 泛型 五:泛型与数组
简介 上一篇文章介绍了泛型的基本用法以及类型擦除的问题,现在来看看泛型和数组的关系.数组相比于Java 类库中的容器类是比较特殊的,主要体现在三个方面: 数组创建后大小便固定,但效率更高 数组能追踪它 ...
- 夯实Java基础(十八)——泛型
1.什么是泛型 泛型是Java1.5中出现的新特性,也是最重要的一个特性.泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数.这种参数类型可以用在类.接口和方法的创建中,分别称为泛型类. ...
随机推荐
- 面试官:你是如何进行SQL调优的?
SQL调优是我们后端开发人员面试中的高频考点,也是实际工作中提升数据库性能的关键技能.面对"你是如何进行SQL调优的?"这个问题,你是否能条理清晰地分析问题并提供解决方案? 1. ...
- Typora - typora主题样式
主题名称:github_harley.css(随便命名) 效果:Mac风格的代码块.更舒适的引用块风格. css harley01 /* 代码块主题 */ /* 顶部 */ .md-fences { ...
- How to use the shell, terminal and the advanced tools
How to use the shell, terminal and the advanced tools Introduction Why use English instead of Chin ...
- 数据库自增 ID 用完了会怎么样?
前言 数据库中的自增 ID 用完了该怎么办? 这个问题可以分为有主键 & 无主键两种情况回答. 有主键 如果你的表有主键,并且把主键设置为自增. 在 MySQL 中,一般会把主键设置成 int ...
- 带有可旋转摄像头的移动小车(urdf+rviz)
博客地址:https://www.cnblogs.com/zylyehuo/ 成果图 step1:新建工作空间 mkdir -p catkin_ws/src cd catkin_ws catkin_m ...
- VMware ESXi系统
esxi全称"VMware ESXi",是可直接安装在物理服务器上的强大的裸机管理系统,是一款虚拟软件,不需安装其他操作系统,是VMware服务器虚拟化的基础.通过直接访问并控制底 ...
- 查看CentOS7的版本信息
1,查看CentOS的版本号: cat /etc/centos-release 显示结果: ...
- CSAPP学习笔记——chapter9 虚拟内存
CSAPP学习笔记--chapter9 虚拟内存 虚拟内存提供三个重要的功能.第一,它在主存中自动缓存最近使用的存放磁盘上的虚拟地址空间的内容.虚拟内存缓存中的块叫做页.对磁盘上页的引用会触发缺页,缺 ...
- Git提交历史优化指南:两步合并本地Commit,代码审查更高效!
在开发过程中,频繁的本地Commit可能导致提交历史冗杂,增加代码审查和维护的复杂度.通过合并连续的Commit,不仅能简化历史记录,还能提升代码可读性和团队协作效率,以下是合并两次本地Commit的 ...
- while循环、dowhile循环、三种循环的区别
1.while循环 案例:使用while循环,打印出水仙花数 while执行流程: 1.先执行初始化语句 2.执行判断条件 结果为true,则执行第3步 结果为false,循环结束 3.执行循环体语句 ...