HashMap居然可以和它直接合体???
LinkedHashMap集合继承于HashMap,学习LinkedHashMap重点对比LinkedHashMap与HashMap的异同特别强调两者的
Entry(节点)数据结构、数据结构的不同带来的特性差异、HashMap的后置处理机制及最少访问删除策略。
LinkedHashMap = HashMap + LinkedList ?
就像这幅图一样?

1. Entry(节点)数据结构
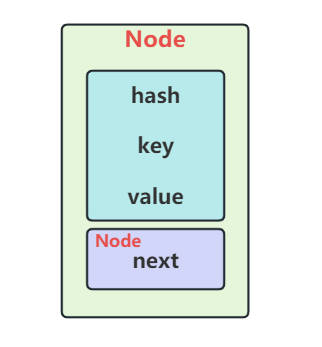
1.1. HashMap.Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// … 构造、getKey/getValue/setValue、equals/hashCode 等 …
}
字段说明:hash:key 的哈希值,key、value:存储的键值对,next:链表或树化时的链表指针。
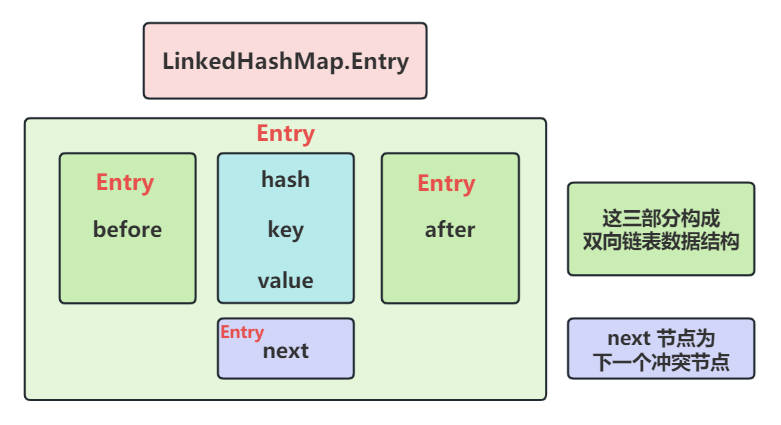
1.2. LinkedHashMap.Entry
// 头节点
transient LinkedHashMap.Entry<K,V> head;
// 尾节点
transient LinkedHashMap.Entry<K,V> tail;
// 节点类
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 双向链表指针
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
新增字段说明:before、after:维护插入/访问顺序的双向链表;
链表头尾:在 LinkedHashMap 中,维护一个 head 和 tail 指针,插入时追加到尾部。
LinkedHashMap 数据结构就像它的名称一样Linked + HashMap,它是在HashMap的基础上,维护了一个双向链表。这个双向链表就像LinkedList一样,可以维护节点插入的顺序。
LinkedHashMap 数据结构是两种形态共存的数据结构
- 你可以忽略双向链表,把它看做普通的
HashMap; - 也可以忽略
HashMap,把它看作是双向链表。
如果你不想使用
LinkedHashMap,但又想要维护HashMap的插入顺序,那你可以在HashMap.put元素后,同时将该元素保存到LinkedList.add集合,但这样就需要你确保集合一致性,比如插入和删除。这么想想,还不如直接用LinkedHashMap集合较为稳妥。
其实LinkedHashMap 一部分源码为的就是维护HashMap与双向链表的一致性,及操作过程做的一些扩展。比如:节点创建时的双向链表尾部插入和HashMap的后置处理。
1.3. 两者对比
| 特性 | HashMap | LinkedHashMap |
|---|---|---|
| 底层数据结构 | 数组 + 链表/红黑树 | 数组 + 链表/红黑树 + 双向链表 |
| 迭代顺序 | 不保证顺序 | 按插入顺序(或访问顺序,可选) |
| 内存开销 | 较小 | 较大(每个节点额外维护链表指针) |
| 适用场景 | 一般的键值存取 | 需要按插入或访问顺序遍历 (如 LRU 缓存) |
1.4. 详细的数据结构案例
通过下面的案例图,清楚地看见每个节点的指向。
假设插入顺序为:22、23、45、89、25、38、49、28
插入完成后的数据结构如图,
图中信息含义: 当前节点信息只显示key值,next为下一个映射冲突节点;before为双链结构的上一节点,after为双链结构的下一节点;绿色虚线是整个LinkedHashMap的双链结构的连接关系。
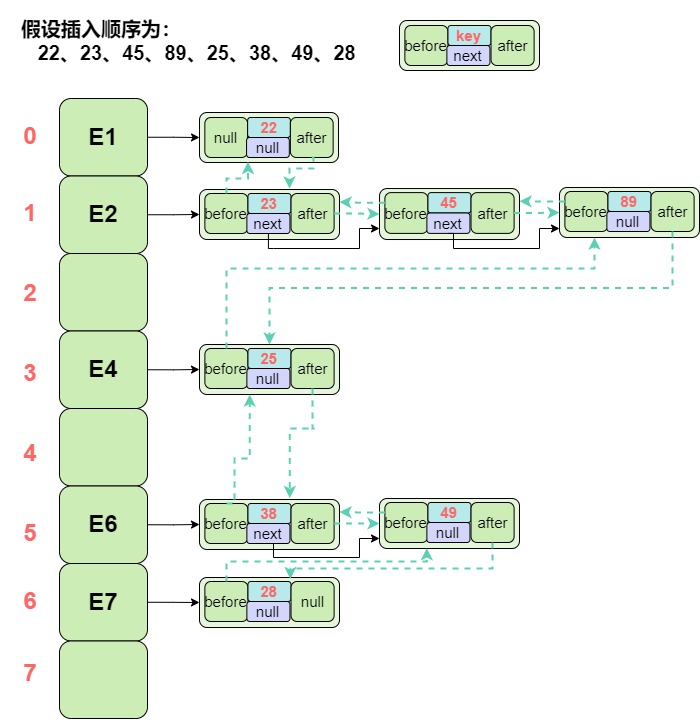
可以清楚地看到,相比HashMap每个节点都需要多维护before和after节点,LinkedHashMap也就需要更多的空间。
2. 节点创建和转化重写
2.1. 创建Entry节点
链表节点创建的同时,通过linkNodeLast(p) 方法,维护双链结构的尾部插入
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
2.2. 树节点创建
红黑树节点创建的同时,通过linkNodeLast(p) 方法,维护双链结构的尾部插入
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
2.3. 节点转化
树节点转化为Entry节点和Entry节点转化树节点都做了重写,通过transferLinks(q, t);方法完成节点转化
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
LinkedHashMap.Entry<K,V> t =
new LinkedHashMap.Entry<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
TreeNode<K,V> t = new TreeNode<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
这些都是多态的简单应用,HashMap 引用指向不同的实例化子类,实现不同的功能。
3. HashMap 的后置处理(post-processing)
HashMap 本身在节点插入、访问、删除后并不做额外操作。LinkedHashMap 则通过重写以下钩子方法,在插入、访问或删除时维护自己的双链表结构。
3.1. 插入后
仅在evict=true 并且removeEldestEntry(first)==true时,插入后才需要移除头部节点
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
3.2. 访问后
仅在 accessOrder = true 时,访问后需调整顺序;需要在LinkedHashMap 的构造方法中设定accessOrder的值。
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e;
// 将 p 移到双向链表尾部
moveNodeToLast(p);
}
3.3. 删除后
只要节点作删除,LinkedHashMap集合就必须删除双链表上的Entry 节点
void afterNodeRemoval(Node<K,V> e) {
// 将 e 从双向链表中摘除
unlinkNode((LinkedHashMap.Entry<K,V>)e);
}
这三步合称为 后置处理,保证在 put、get、remove 等操作时,链表结构的正确维护。
但是、
为什么LinkedHashMap集合在插入完成后,需要多做一步删除头节点的操作呢?
为什么访问完成后需要将访问节点移动到双链表的尾部呢?
4. 最少访问删除策略
为什么是 LinkedHashMap 而不是 HashMap:
LinkedHashMap 在 HashMap 基础上,增加了 双向链表,用来记录:插入顺序(默认)或访问顺序(accessOrder = true 时)
这就可以实现:记录最近访问的节点(最近访问的放到链表尾部);删除最久未访问的节点(链表头)
4.1. 核心方法
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false; // 默认不删除
}
这是一个 钩子,这个钩子removeEldestEntry(first) 在插入后缀处理中调用,LinkedHashMap 的源码如下:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
你可以自己重写,制定属于自己的处理策略:
LinkedHashMap<K,V> lru = new LinkedHashMap<K,V>(16, 0.75f, true) {
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > 100; // 超过 100 个就删除最老的
}
};
当每次 put 后:afterNodeInsertion 调用 removeEldestEntry,如果返回 true,就从链表头删除最老节点
总结:
LinkedHashMap用removeEldestEntry+accessOrder=true可实现简单 LRU 缓存。
HashMap不自带任何访问追踪或自动删除机制,必须由使用者自己实现。
4.2. LRU缓存例子
LRU 缓存(Least Recently Used Cache,最近最少使用缓存)是一种常用的 缓存淘汰策略,它的核心思想是:
如果数据最近被访问过,那么将来被访问的可能性也更高;反之则淘汰。
规定固定大小为4的缓存容器,源码如下
public class LRUDemo {
public static void main(String[] args) {
// 指定只能缓存四个数据
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>(16, 0.75f, true) {
protected boolean removeEldestEntry(Map.Entry<String, String> eldest) {
return size() > 4;
}
};
linkedHashMap.put("A","1");
linkedHashMap.put("B","2");
linkedHashMap.put("C","3");
linkedHashMap.put("D","4");
printOrder(linkedHashMap);
linkedHashMap.get("B"); // B 被访问,移到末尾
printOrder(linkedHashMap);
linkedHashMap.put("E","5"); // 淘汰最老的 A
printOrder(linkedHashMap);
}
public static void printOrder(LinkedHashMap<String, String> linkedHashMap ) {
System.out.print("数据结构:" + "\n[head]");
for (Map.Entry<String, String> entry : linkedHashMap.entrySet()) {
System.out.print(" ⇄ " + entry.getKey());
}
System.out.println(" ⇄ [tail]\n");
}
}
执行输出结果如下:
数据结构:
[head] ⇄ A ⇄ B ⇄ C ⇄ D ⇄ [tail]
数据结构:
[head] ⇄ A ⇄ C ⇄ D ⇄ B ⇄ [tail]
数据结构:
[head] ⇄ C ⇄ D ⇄ B ⇄ E ⇄ [tail]
5. HashMap与LinkedHashMap区别汇总
| 对比维度 | HashMap | LinkedHashMap |
|---|---|---|
| 节点类型 | HashMap.Node |
LinkedHashMap.Entry(继承自 HashMap.Node) |
| 顺序保证 | 无 | 按插入顺序或访问顺序 |
| 额外字段 | next |
next + before + after |
| 内存消耗 | 较低 | 较高(每个节点多两个引用) |
put 后置处理 |
无 | afterNodeInsertion(链表尾部插入 + 可选淘汰) |
get 后置处理 |
无 | afterNodeAccess(访问时链表重排序,仅 accessOrder = true) |
remove 后置处理 |
无 | afterNodeRemoval(从链表中摘除) |
| 用途 | 高效快速随机存取 | 需要遍历顺序、实现 LRU 缓存、保持可预测迭代顺序 |
通过上述对比,可以看出 LinkedHashMap 只是对 HashMap 的轻量增强:
- 核心额外逻辑:在每次增删改查操作后,钩入双向链表维护;
- 额外空间开销:每个节点多俩指针;
- 功能收益:可提供插入顺序或访问顺序的迭代、可实现基于访问顺序的缓存淘汰(如 LRU)。
6. 总结
LinkedHashMap集合继承于HashMap,重点对比 LinkedHashMap 与 HashMap 不同的数据结构的带来的特性差异;为什么需要LinkedHashMap这种两种形态共存的数据结构;以及通过HashMap 的后置处理机制轻松实现数据结构的功能扩展;并且对LinkedHashMap最少访问删除策略LRU做了简单案例演示。
往期推荐
| 分类 | 往期文章 |
|---|---|
| Java集合原理 | HashMap集合--基本操作流程的源码可视化 Java集合--HashMap底层原理可视化,秒懂扩容、链化、树化 Java集合--从本质出发理解HashMap Java集合--LinkedList源码可视化 Java集合源码--ArrayList的可视化操作过程 |
| 设计模式秘籍 (已全部开源) |
掌握设计模式的两个秘籍 往期设计模式文章的:设计模式 |
| 软件设计师 | 软考中级--软件设计师毫无保留的备考分享通过软考后却领取不到实体证书? 2023年下半年软考考试重磅消息 |
| Java学习路线 和相应资源 |
Java全栈学习路线、学习资源和面试题一条龙 |
原创不易,觉得还不错的,三连支持:点赞、分享、推荐↓
HashMap居然可以和它直接合体???的更多相关文章
- 实在没想到系列——HashMap实现底层细节之keySet,values,entrySet的一个底层实现细节
我在看HashMap源码的时候发现了一个没思考过的问题,在这之前可以说是完全没有思考过这个问题,在一开始对这个点有疑问的时候也没有想到居然有这么个语法细节存在,弄得我百思不得其解,直到自己动手做实验改 ...
- 【原创】关于hashcode和equals的不同实现对HashMap和HashSet集合类的影响的探究
这篇文章做了一个很好的测试:http://blog.csdn.net/afgasdg/article/details/6889383,判断往HashSet(不允许元素重复)里塞对象时,是如何判定set ...
- java HashMap中出现反复的key, 求解释
上代码: Person p1 = new Person("xiaoer",1); Person p2 = new Person("san",4); Map< ...
- 关于java集合类HashMap的理解
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- HashMap浅入理解
HashMap不能保证元素的顺序,HashMap能够将键设为null,也可以将值设为null,与之对应的是Hashtable,(注意大小写:不是HashTable),Hashtable不能将键和值设为 ...
- HashMap?面试?我是谁?我在哪
现在是晚上11点了,学校屠猪馆的自习室因为太晚要关闭了,勤奋且疲惫的小鲁班也从屠猪馆出来了,正准备回宿舍洗洗睡,由于自习室位置比较偏僻所以是接收不到手机网络信号的,因此小鲁班从兜里掏出手机的时候,信息 ...
- Java开发笔记(六十六)映射:HashMap和TreeMap
前面介绍了两种集合的用法,它们的共性为每个元素都是唯一的,区别在于一个无序一个有序.虽说往集合里面保存数据还算容易,但要从集合中取出数据就没那么方便了,因为集合居然不提供get方法,没有get方法怎么 ...
- Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析 今天发一篇”水文”,可能很多读者都会表示不理解,不过我想把它作为并发序列文章中不可缺少的一块来介绍.本来以为花不了 ...
- HashMap、Hashtable、ConcurrentHashMap面试总结
原文链接:https://www.cnblogs.com/hexinwei1/p/10000779.html 小总结 HashMap.Hashtable.ConcurrentHashMap HashM ...
- Java9之HashMap与ConcurrentHashMap
HashMap在Java8之后就不再用link data bins了,而是转为用Treeify的bins,和之前相比,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成.: * This ...
随机推荐
- eolinker解决两个变量合并成一个变量提供其他接口使用的方法
特别注意:需要使用全局变量或者预处理前务必阅读本链接https://www.cnblogs.com/becks/p/13713278.html 场景描述:提交订单的接口请求中,有一参数是由商品价格+运 ...
- 解决 Dify 部署中 Podman WSL 容器文件权限问题
解决 Dify 部署中 Podman WSL 容器文件权限问题 在使用 Podman 进行 Dify 部署时,遇到了一个关键问题:启动服务时出现 initdb: error: could not ch ...
- Lucas 定理简单证明
前言 Oi wiki 和网上博客的证明都没完全看懂,最后还是自己推出来的..这里记录一下思路. Lucas 定理 对于质数 \(p\),$${n\choose m}\bmod p={\lfloor n ...
- K8s新手系列之Pod中容器的镜像拉取策略
概述 在 Kubernetes(K8s)里,容器镜像拉取策略(ImagePullPolicy)决定了 K8s 在创建或重启 Pod 时,如何处理容器镜像的拉取操作.这一策略能够确保使用的镜像始终是最新 ...
- 信息资源管理综合题之“某国企投资IT应用人员减少但生成率没有实质性变化的IT黑洞问题”
一.某大型国企在IT应用上投资了2000万美元,虽然蓝领工人数量大幅减少,但实际生产率并未有实质性变化 1.企业在IT应用上的巨额投资并未达到预期目标的这种现象被称为什么? 2.产生这现象的原因有哪些 ...
- vue3 基础-动态组件 & 异步组件
之前学习的都是父子组件传值的话题, 一句话总结就是, 常规数据通过属性传, dom 结构通过插槽 slot 来传. 而本篇则关注如何通过数据去控制组件的显示问题, 如咱经常用到的页面切换呀, Tab ...
- 王炸!SpringBoot+MCP 让你的系统秒变AI小助手
王炸!SpringBoot+MCP 让你的系统秒变AI小助手 感觉本篇对你有帮助可以关注一下我的微信公众号(深入浅出谈java),会不定期更新知识和面试资料.技巧!!! 一.MCP 是什么? MCP( ...
- C#之依赖注入DI(DependencyInjection)
依赖注入实际上是一种设计模式,它可以有效降低模块之间的耦合度. 基本思路: 创建ServiceCollection对象 用ServiceCollection对象进行注册服务 用ServiceColle ...
- Merge Two Binary Trees——LeetCode进阶路
原题链接https://leetcode.com/problems/merge-two-binary-trees/ 题目描述 Given two binary trees and imagine th ...
- github常见开源协议概括
None / No License 默认协议,不允许他人复杂.分发.修改.使用,只能fork下来看 Apache License 2.0 允许个人使用.商业使用.复制.修改.分发,但是出了事作者免责, ...