Spring AI与DeepSeek实战三:打造企业知识库

一、概述
企业应用集成大语言模型(LLM)落地的两大痛点:
- 知识局限性:LLM依赖静态训练数据,无法覆盖实时更新或垂直领域的知识;
- 幻觉:当LLM遇到训练数据外的提问时,可能生成看似合理但错误的内容。
用最低的成本解决以上问题,需要使用 RAG 技术,它是一种结合信息检索技术与 LLM 的框架,通过从外部 知识库 动态检索相关上下文信息,并将其作为 Prompt 融入生成过程,从而提升模型回答的准确性;
本文将以AI智能搜索为场景,基于 Spring AI 与 RAG 技术结合,通过构建实时知识库增强大语言模型能力,实现企业级智能搜索场景与个性化推荐,攻克 LLM 知识滞后与生成幻觉两大核心痛点。
关于 Spring AI 与 DeepSeek 的集成,以及 API-KEY 的申请等内容,可参考文章《Spring AI与DeepSeek实战一:快速打造智能对话应用》
二、RAG数据库选择
构建知识库的数据库一般有以下有两种选择:
| 维度 | 向量数据库 | 知识图谱 |
|---|---|---|
| 数据结构 | 非结构化数据(文本/图像向量) | 结构化关系网络(实体-关系-实体) |
| 查询类型 | 语义相似度检索 | 多跳关系推理 |
| 典型场景 | 文档模糊匹配、图像检索 | 供应链追溯、金融风控 |
| 性能指标 | QPS>5000 | 复杂查询响应时间>2s |
| 开发成本 | 低(API即用) | 高(需构建本体模型) |
搜索推荐场景更适合选择 向量数据库
三、向量模型
向量模型是实现 RAG 的核心组件之一,用于将非结构化数据(如文本、图像、音频)转换为 高维向量(Embedding)的机器学习模型。这些向量能够捕捉数据的语义或结构信息,使计算机能通过数学运算处理复杂关系。
向量数据库是专门存储、索引和检索高维向量的数据库系统

spring-ai-alibaba-starter 默认的向量模型为 text-embedding-v1
可以通过 spring.ai.dashscope.embedding.options.model 进行修改。
四、核心代码
4.1. 构建向量数据
创建 resources/rag/data-resources.txt 文件,内容如下:
1. {"type":"api","name":"测试api服务01","topic":"综合政务","industry":"采矿业","remark":"获取采矿明细的API服务"}
2. {"type":"api","name":"新能源车类型","topic":"能源","industry":"制造业","remark":"获取新能源车类型的服务"}
3. {"type":"api","name":"罚款报告","topic":"交通","industry":"制造业","remark":"获取罚款报告的接口"}
4. {"type":"api","name":"光伏发电","topic":"能源","industry":"电力、热力、燃气及水生产和供应业","remark":"获取光伏发电的年度报告"}
5. {"type":"api","name":"收益明细2025","topic":"综合政务","industry":"信息传输、软件和信息技术服务业","remark":"2025年的收益明细信息表"}
创建向量数据库的 Bean
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel
, @Value("classpath:rag/data-resources.txt") Resource docs) {
VectorStore vectorStore = SimpleVectorStore.builder(embeddingModel).build();
vectorStore.write(new TokenTextSplitter().transform(new TextReader(docs).read()));
return vectorStore;
}
SimpleVectorStore是Spring AI提供的一个基于内存的向量数据库;- 使用
TokenTextSplitter来切分文档。
4.2. 创建ChatClient
private final ChatClient chatClient;
public RagController(ChatClient.Builder builder, VectorStore vectorStore) {
String sysPrompt = """
您是一个数据产品的智能搜索引擎,负责根据用户输入的内容进行精准匹配、模糊匹配和近义词匹配,以搜索相关的数据记录。
您只能搜索指定的内容,不能回复其他内容或添加解释。
您可以通过[search_content]标识符来表示需要搜索的具体内容。要求您返回匹配内容的完整记录,以JSON数组格式呈现。
如果搜索不到内容,请返回[no_data]。
""";
this.chatClient = builder
.defaultSystem(sysPrompt)
.defaultAdvisors(
new QuestionAnswerAdvisor(vectorStore, new SearchRequest())
)
.defaultOptions(
DashScopeChatOptions.builder()
.withModel("deepseek-r1")
.build()
)
.build();
}
- 通过系统
Prompt来指定智能体的能力; - 通过
QuestionAnswerAdvisor绑定向量数据库。
4.3. 搜索接口
@GetMapping(value = "/search")
public List<SearchVo> search(@RequestParam String search, HttpServletResponse response) {
response.setCharacterEncoding("UTF-8");
PromptTemplate promptTemplate = new PromptTemplate("[search_content]: {search}");
Prompt prompt = promptTemplate.create(Map.of("search", search));
return chatClient.prompt(prompt)
.call()
.entity(new ParameterizedTypeReference<List<SearchVo>>() {});
}
这里通过 entity 方法来实现搜索结果以结构化的方式返回。
4.4. 测试接口
4.4.1. 搜索新能源
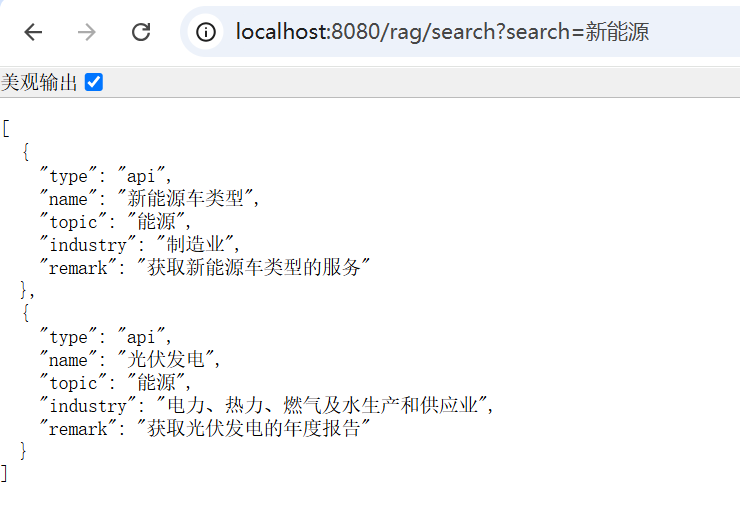
除了模糊匹配了新能源车之外,还匹配了和新能源相关的光伏数据。
4.4.21. 搜索收入
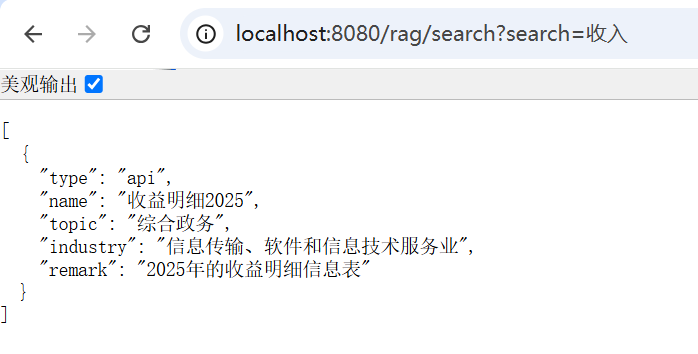
匹配同义词的收益数据。
五、总结
本文以智能搜索引擎场景,通过 RAG 技术,实现了全文搜索、模糊搜索、同义词推荐等功能,并以结构化的方式返回搜索结果。需要注意的是,在企业应用中,要把 SimpleVectorStore 改为成熟的第三方向量数据库,例如 milvus、elasticsearch、redis 等。
六、完整代码
- Gitee地址:
https://gitee.com/zlt2000/zlt-spring-ai-app
- Github地址:
https://github.com/zlt2000/zlt-spring-ai-app
Spring AI与DeepSeek实战三:打造企业知识库的更多相关文章
- Spring Boot 揭秘与实战(三) 日志框架篇 - 如何快速集成日志系统
文章目录 1. 默认的日志框架 logback2. 常用的日志框架 log4j 1.1. 日志级别 1.2. 日志文件 3. 源代码 Java 有很多日志系统,例如,Java Util Logging ...
- Spring Boot 揭秘与实战(六) 消息队列篇 - RabbitMQ
文章目录 1. 什么是 RabitMQ 2. Spring Boot 整合 RabbitMQ 3. 实战演练4. 源代码 3.1. 一个简单的实战开始 3.1.1. Configuration 3.1 ...
- 生成式AI对业务流程有哪些影响?企业如何应用生成式AI?一文看懂
集成与融合类ChatGPT工具与技术,以生成式AI变革业务流程 ChatGPT背后的生成式AI,聊聊生成式AI如何改变业务流程 ChatGPT月活用户过亿,生成式AI对组织的业务流程有哪些影响? 生成 ...
- Spring线程池开发实战
Spring线程池开发实战 作者:chszs,转载需注明. 作者博客主页:http://blog.csdn.net/chszs 本文提供了三个Spring多线程开发的例子,由浅入深,由于例子一目了然, ...
- 【SSH项目实战三】脚本密钥的批量分发与执行
[SSH项目实战]脚本密钥的批量分发与执行 标签(空格分隔): Linux服务搭建-陈思齐 ---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品,允许转载, ...
- AI应用开发实战 - 定制化视觉服务的使用
AI应用开发实战 - 定制化视觉服务的使用 本篇教程的目标是学会使用定制化视觉服务,并能在UWP应用中集成定制化视觉服务模型. 前一篇:AI应用开发实战 - 手写识别应用入门 建议和反馈,请发送到 h ...
- AI应用开发实战 - 手写识别应用入门
AI应用开发实战 - 手写识别应用入门 手写体识别的应用已经非常流行了,如输入法,图片中的文字识别等.但对于大多数开发人员来说,如何实现这样的一个应用,还是会感觉无从下手.本文从简单的MNIST训练出 ...
- AI应用开发实战 - 从零开始搭建macOS开发环境
AI应用开发实战 - 从零开始搭建macOS开发环境 本视频配套的视频教程请访问:https://www.bilibili.com/video/av24368929/ 建议和反馈,请发送到 https ...
- spring事务详解(三)源码详解
系列目录 spring事务详解(一)初探事务 spring事务详解(二)简单样例 spring事务详解(三)源码详解 spring事务详解(四)测试验证 spring事务详解(五)总结提高 一.引子 ...
- Spring Boot 揭秘与实战 源码分析 - 工作原理剖析
文章目录 1. EnableAutoConfiguration 帮助我们做了什么 2. 配置参数类 – FreeMarkerProperties 3. 自动配置类 – FreeMarkerAutoCo ...
随机推荐
- Solution Set -“似一捧细泉的奔逃”
目录 0.「OurOJ #47912」优美的分配方案 1.「OurOJ #47927」海之女仆 2.「OurOJ #47950」中档题 3.「OurOJ #47933」坐标 4.「OurOJ #479 ...
- 使用 pdf.js 通过文件流方式加载pdf文件
关于Pdf.js的基础知识,请参考我的博客 使用 pdf.js 在网页中加载 pdf 文件 使用 pdf.js 跨域问题的处理方法 上面两篇博客中介绍的内容都是基于直接加载远程服务器中静态PDF文件 ...
- TCP/IP协议笔记
TCP/IP 一.TCP/IP简介 TCP/IP 指传输控制协议/网际协议(Transmission Control Protocol / Internet Protocol),是用于因特网 (Int ...
- DPDK简介和原理
本文分享自天翼云开发者社区<DPDK简介和原理>,作者:s****n DPDK是一种绕过内核直接在用户态收发包来解决内核性能的瓶颈技术. 什么是中断 了解DPDK之前,首先需要先了解什么是 ...
- 全网最简单DeepSeek-R1本地部署教程
1.安装ollama 打开ollama网址:https://ollama.com/ 选择你电脑的系统进行下载 我的电脑是windows的就点击windows然后点击下载即可 下载完毕后双击打开下载的. ...
- [源码分析] Facebook如何训练超大模型--- (5)
[源码分析] Facebook如何训练超大模型--- (5) 目录 [源码分析] Facebook如何训练超大模型--- (5) 0x00 摘要 0x01 背景 0x02 思路 2.1 学习建议 2. ...
- 从0搭建Vue3组件库(一): 开篇
前言 这是从0搭建Vue3组件库系列文章第一篇文章,这个系列我曾经写过多篇文章,但是写完之后回过头来再看里面有很多遗漏以及不足之处,所以决定重新梳理这个系列,并从头开始搭建一个完整的Vue3组件库工程 ...
- 嵌入式linux下的FTP服务器配置记录
嵌入式linux FTP服务器 一般嵌入式Linux下的FTP服务器会有什么要求呢?一般来说差不多如下所示 账号认证,需要特定用户才能访问(不一定要和登录用户挂钩) 根目录固定在一个固定的位置,且不能 ...
- 大模型本地部署搭建【ollama + deepseek + dify】
大模型本地部署搭建[在线] 一.ollama的下载.安装.配置 ollama是管理和运行所有开源大模型的平台 下载地址:https://ollama.com/download 或github下载:ht ...
- xpath 定位单选框
分析页面结构: 整个页面只有一组radiogroup 一个group地下存在两个radio 思路定位到页面唯一元素->下面具体radio 代码: //div[@class='el-radio-g ...