深度剖析 StarRocks 读取 ORC 加密文件背后的技术
作者:vivo 互联网大数据团队 - Zheng Xiaofeng
本文介绍了StarRocks数据库如何读取ORC加密文件,包括基础概念以及具体实现方案。深入探讨了利用ORC文件的四层结构和三层索引机制,实现高效查询加密数据。希望通过本文对ORC加密文件读取功能的实现细节的剖析,让读者更加深刻理解ORC文件,同时了解StarRocks支持加解密数据分析的方案。
一、背景
为了提升对敏感数据的保护,需要对Hive表一些敏感数据进行加密存储。
Spark组件已经通过引入了Apache ORC项目(Java版本)对ORC格式的Hive表的数据进行加解密。
StarRocks也使用了Apache ORC项目的C++版本读写ORC文件,但是C++版本没有实现加解密功能,在使用StarRocks对Hive表进行即席分析时,无法对具有加密列的Hive表进行查询,因此,需要对StarRocks 的Apache ORC模块进行改造,使其支持对ORC格式的Hive加密表数据读取功能,数据架构图如下图所示:
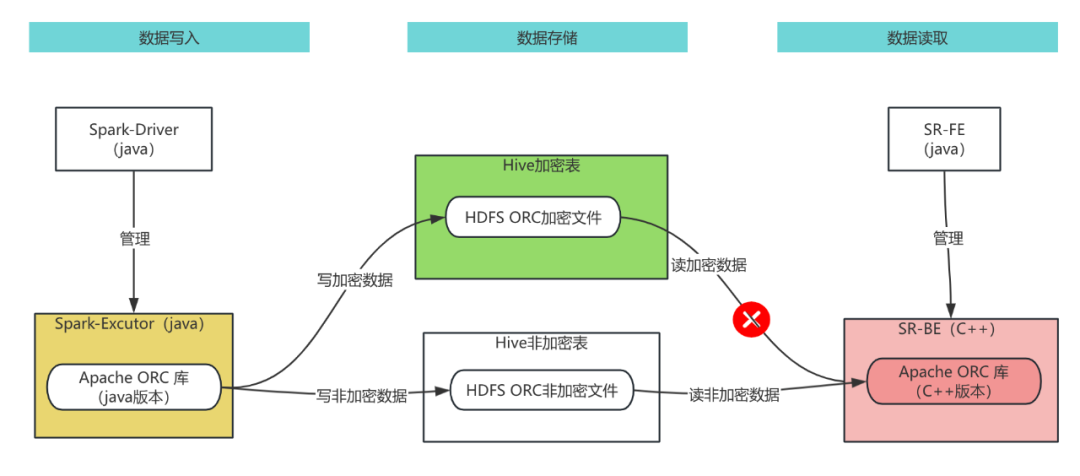
希望通过本文对ORC加密文件读取功能的实现细节的剖析,让读者更加深刻理解ORC文件,同时了解StarRocks支持加解密数据分析的方案。
二、问题引入
在正式开启全文的阅读之前,我们首先引入几个问题,然后带着这些问题去阅读后面的内容,将会更有针对性与启发性,通过深入解答这些问题,我们不仅能够更好地理解相关的概念和技术,还能提升分析和解决问题的能力。问题如下:
程序解压某个文件时,是否需要一次性读取整个文件后再进行解压操作?
ORC 文件究竟是如何做到在不扫描全文件的情况下就能精准查询到想要的数据?
当 SQL 查询条件不符合最左前缀原则时,ORC文件中的索引是否就会失效?
数据加密、解密、解压以及压缩之间的关联关系到底是怎样的?
在写ORC文件时为什么是先压缩后加密,而不是先加密后解压?
三、ORC文件介绍
ORC(Optimized Row Columnar)文件格式是一种高度优化的列式存储格式,它主要用于Hadoop生态系统中的大数据处理和分析。ORC文件结构的设计旨在提高I/O效率、减少数据读取时间,并支持复杂的数据类型和压缩算法。
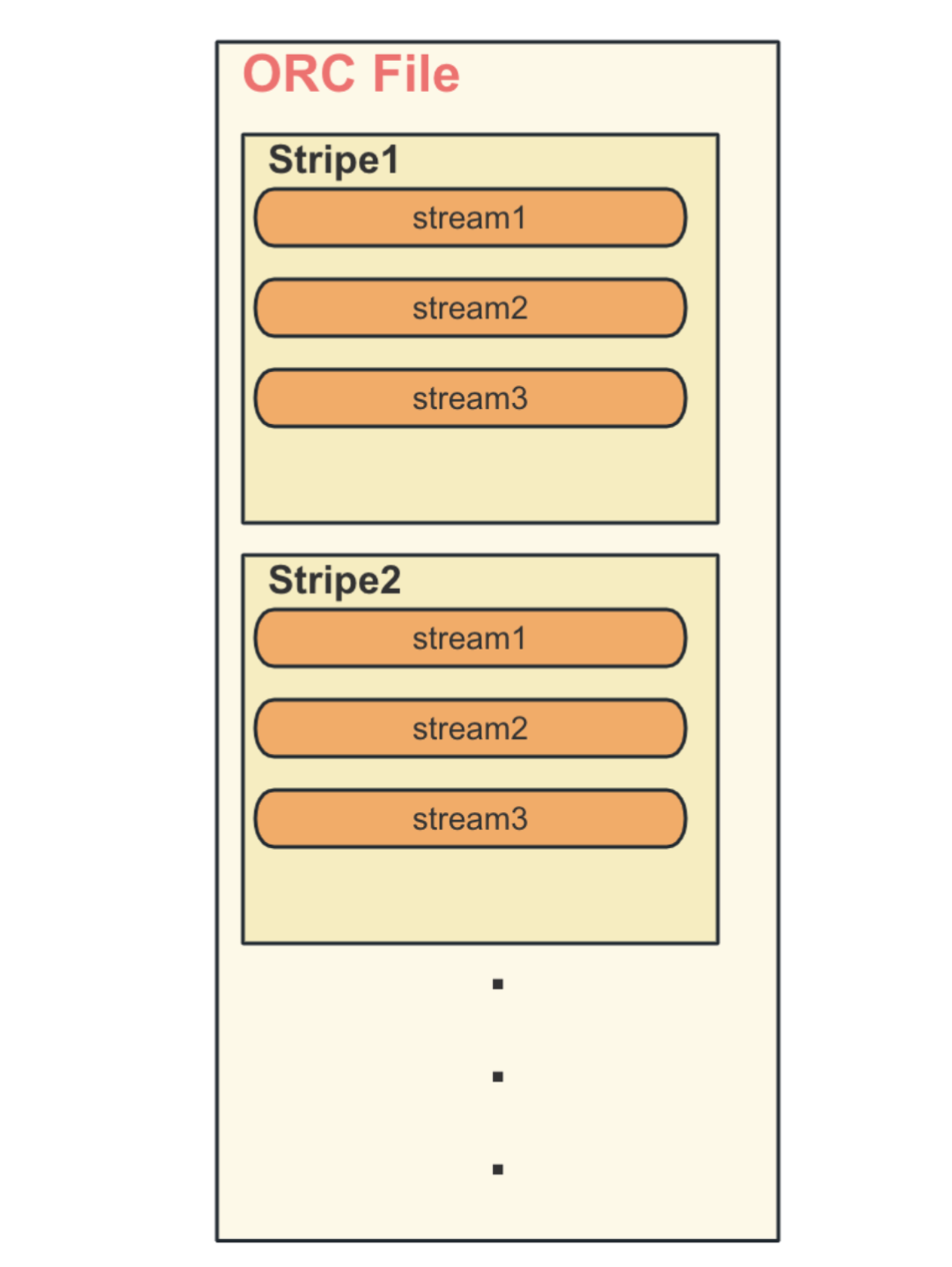
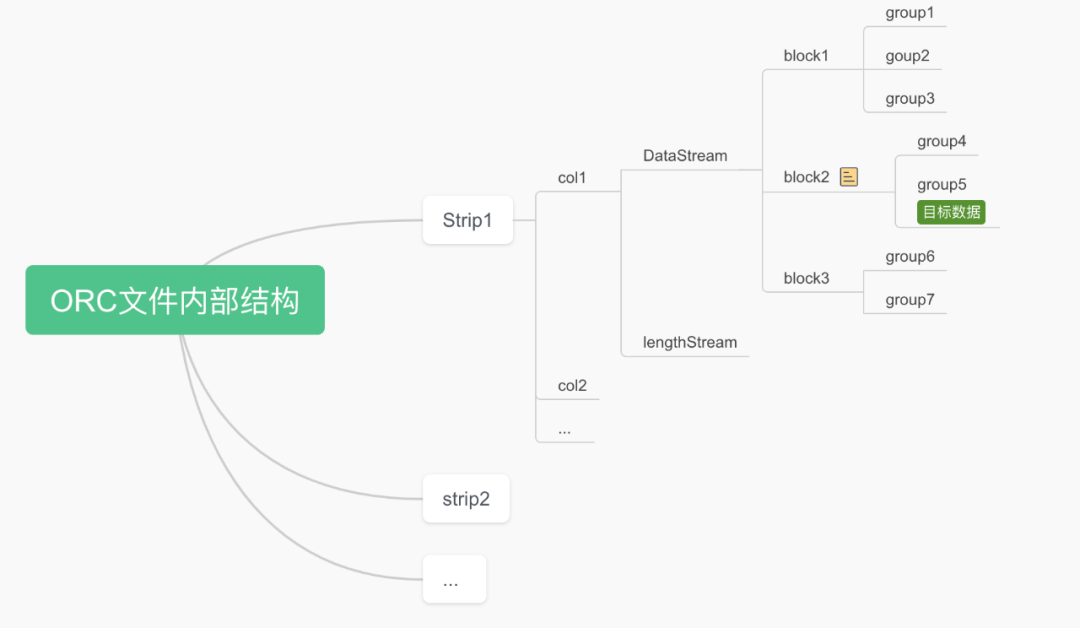
3.1 四层结构 File ,Stripe,Stream,Group
一个File中包含多个Stripe,一个Stripe包含多个Steam,一个Stream包含多个Group,每个Group默认存储1万行数据,如下图所示:
3.2 三层索引
FileStat :文件级别各列的统计信息,用于判断SQL条件是否下推。
StripeStat:Stripe级别各列的统计信息,用于判断SQL条件是否下推。
IndexData:每个Stripe 内部各列的索引信息,用于判断SQL条件是否下推。
在读取文件中数据之前,会先读取以上3类索引数据,根据SQL条件逐层进行比对,来决定是否跳过某些数据的读取,减少数据扫描量,从而提升SQL查询效率。
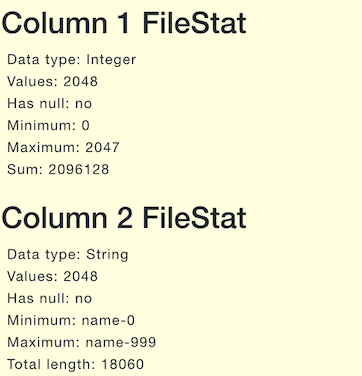
下表是只包含id和name两列的ORC文件的各层统计信息的案例:
FileStat
StripeStat

IndexData

3.3 ORC文件内部详细结构
前面已经大体介绍了ORC文件的结构,下面详细介绍其内部结构,ORC文件由多个逻辑层次组成,每个层次都有特定的作用和结构,下图具体描述了包含2列(id,name)的ORC文件结构图:
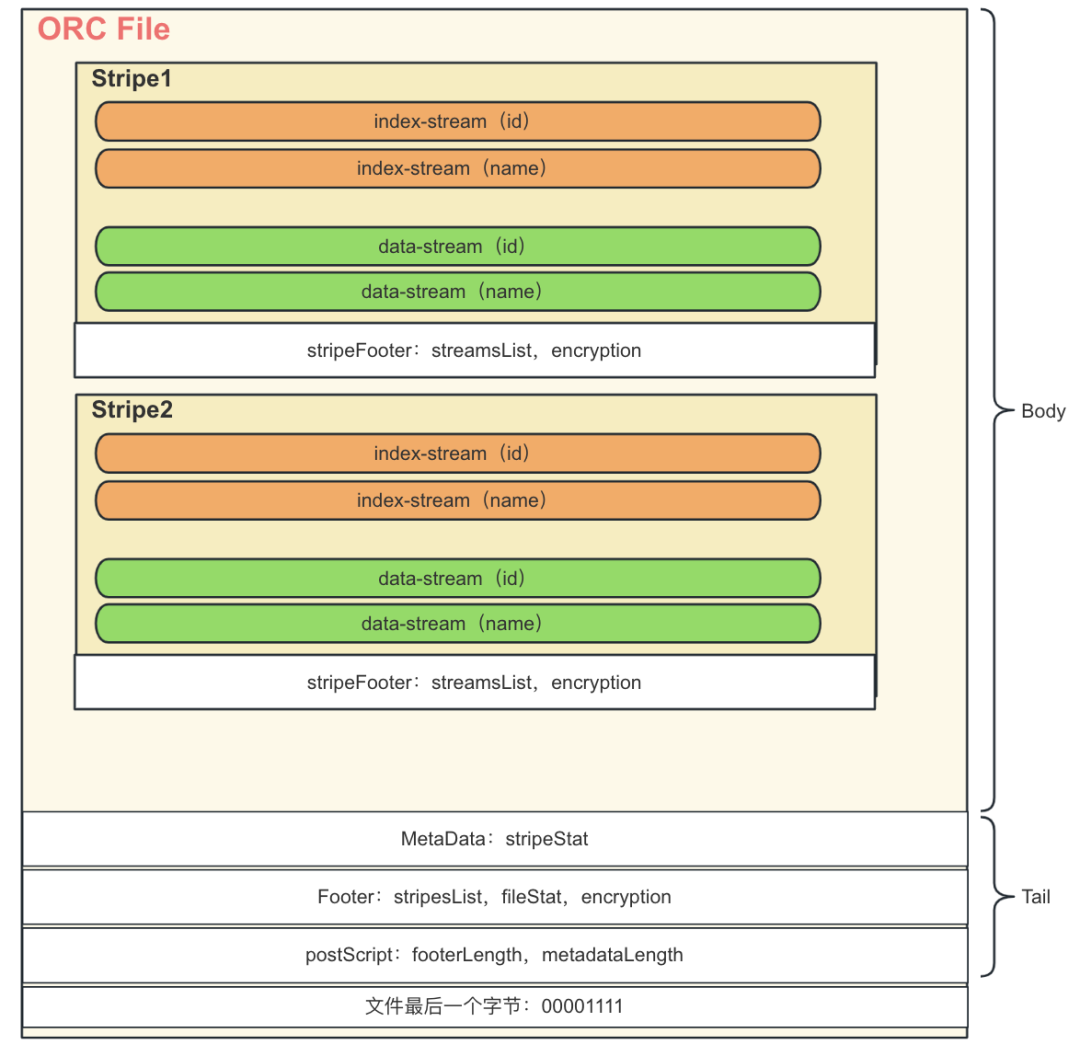
Tail:存储文件的元数据,如列的压缩信息、统计信息、版本等,包含了三个部分:PostScript、Footer、MetaData。
Body:实际存储数据的部分,由多个Stripe组成。
下面分别介绍Tail和Body内部包含哪些结构:
Tail文件尾部是读取ORC文件的起点,它包含了文件关键信息:
PostScript:存储文件的压缩类型、压缩块大小、版本信息,Footer和MetaData的长度等,这部分数据不会被压缩。
Footer:记录了整个文件所有列的统计信息(FileStat),所有Stripe的元数据信息(stripesList),加密信息(encryption)以及文件body长度。
MetaData:存储该文件所有Stripe的统计信息(StripeStat)。
Body实际存储数据的部分,由多个Stripe组成,每个Stripe包含多个Stream,先存储索引相关的Stream(index-Stream),后面存储实际数据相关的Stream(data-Stream),每一列包含多个index-Stream和data-Stream,Stripe是ORC文件中数据存储的基本单元,每个Stripe数据大小一般不超过200M,主要包含下面几块内容:
Stripe Footer:包含所有Stream的元数据(streamsList)和加密信息(encryption)等。
Index-Stream:存储索引相关数据的Stream,按列存储。
Data-Stream:储实际数据相关的Stream,按列存储。
ORC文件的读取是从尾部最后一个字节开始的,得到PostScript的长度,读取PostScript,然后根据PostScript中的FooteLength,MetaDataLength信息读取MetaData和Footer,最后根据Footer中的Stripe信息读取具体的数据Stripe,上面的文字介绍可能不是很直观,如果想更细节了解ORC文件结构内容可以参考(ORC文件结构思维导图,ORC文件官网介绍)。
四、相关概念的理解
4.1 对称加解密
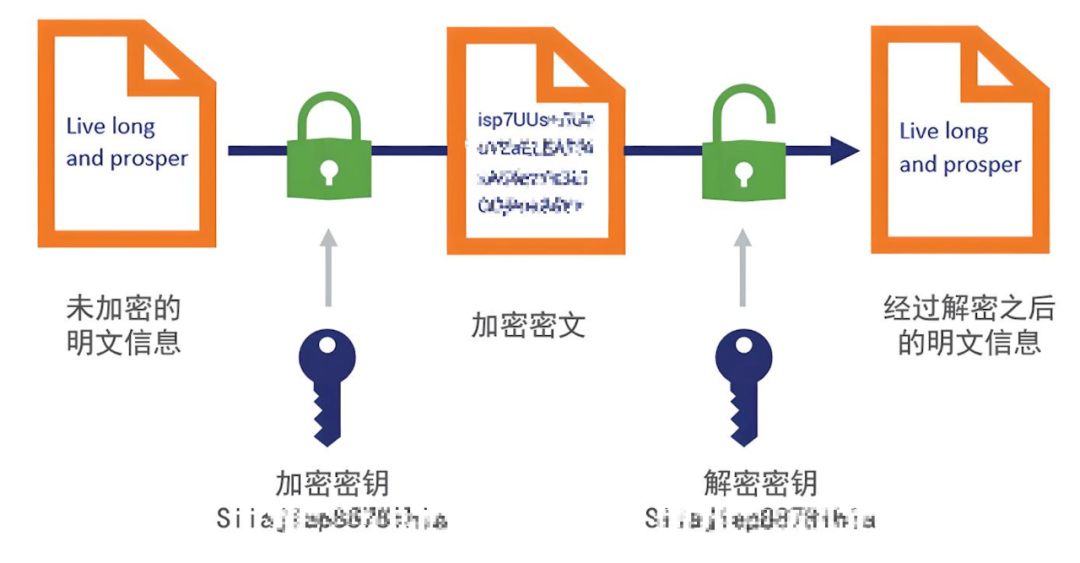
对称加解密的要素包括密钥、明文、密文和加密算法。以下是对这些要素关系的描述:
密钥:密钥是加密和解密过程中的关键元素,它是由随机数生成的,通常是固定长度的一串二进制数。
明文:明文是指原始的信息,可以是文本、图片、音频等各种形式的数据。
密文:密文是经过加密算法处理后的数据,只有知道密钥的人才能解密还原成明文。
加密算法:加密算法是将明文转换成密文的过程,这个过程通常涉及到一系列的数学运算,比如AEC,RSA等。
注意:对称加密的加密密钥 和 解密密钥是一样的。
4.2 文件的压缩和解压缩
4.2.1 压缩算法
压缩算法是用于减小文件大小的数学方法。它通过各种技术,如替换、重新编码、差分编码、运行长度编码、字典编码、变换编码等,来减少数据的冗余和实现数据的体积缩小。压缩算法可以是无损的或有损的:
无损压缩:意味着原始数据可以完全从压缩文件中恢复,常用于文本和某些类型的数据文件。
有损压缩:为了获得更高的压缩率,允许丢失一些数据,常用于图像、音频和视频文件。
4.2.2 解压算法
解压算法是压缩算法的逆过程,它用于将压缩文件恢复到其原始状态。无损压缩的解压算法能够完全恢复原始数据,而有损压缩的解压算法则可能无法完全恢复所有原始数据。
文件压缩和解压缩简单流程图如下:
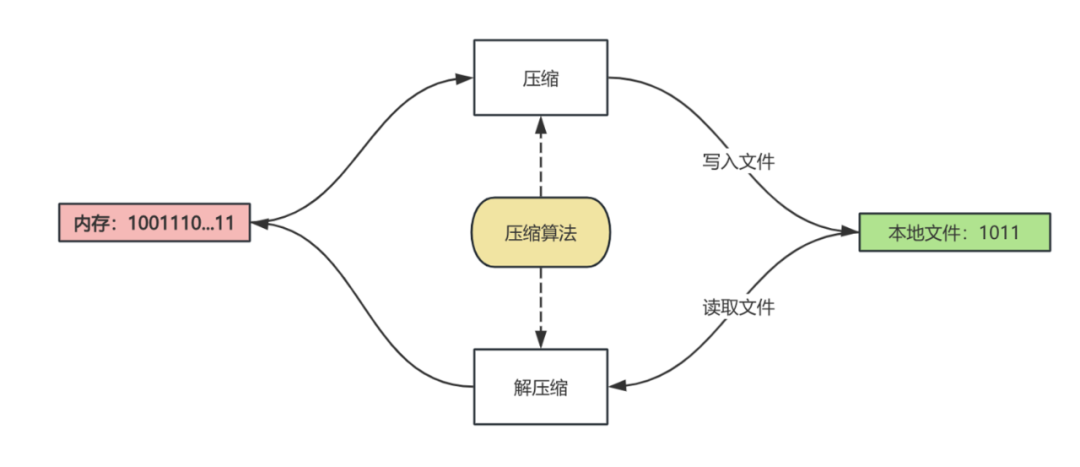
注意:数据的压缩算法和解压算法要一样
4.2.3 压缩块
文件压缩块是指对文件进行压缩处理后生成的一组连续的数据块。在文件压缩过程中,文件被分割成多个块,每个块都经过压缩算法处理。一般来说,文件压缩块的大小可配置。例如,ZIP压缩的每个压缩块的大小可以达到64KB或更大,而在其他压缩格式如7z中,压缩块的大小可以更大,通常为数MB。这些大小可以根据文件的特性和压缩算法的性能进行调整,以达到更好的压缩比和解压性能。
注意:在解压文件的过程中会从文件中读取整个压缩块数据到内存之后再使用解压算法进行解压处理,所以压缩块越大每次解压读取到内存里的数据会越大。
4.3 加密压缩文件读写大致流程
在掌握了数据加密和压缩的基础知识之后,让我们从宏观的角度了解一下ORC加密文件读写流程,如下图所示:在写入时,内存中的数据首先被序列化,然后压缩以减少体积,最后对数据加密。在读取时,数据首先被解密以恢复原始格式,然后解压数据得到原始数据,最后通过反序列化原始数据转换为内存对象。
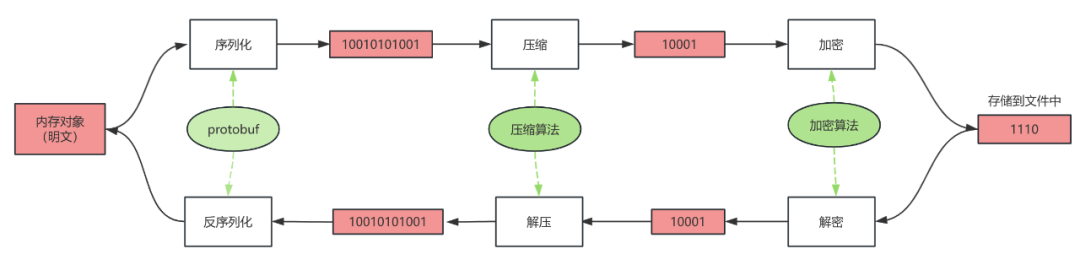
详细说明写入和读取过程中的各个步骤:
(1)写入过程(序列化、压缩、加密)
序列化:在数据写入存储系统之前,首先需要将内存中的对象转换成可以存储或传输的格式,这个过程称为序列化。序列化后的数据通常是一个二进制格式,便于后续的处理。
压缩:序列化后的数据可能会占用较大的空间。为了减少存储需求和提升后续数据加密处理效率,接下来对数据进行压缩。压缩算法会尝试去除数据中的冗余,从而减少数据的体积。
加密:压缩后的数据需要进行加密,以确保数据的安全性。加密算法会使用密钥对数据进行加密,生成密文。
存入文件中:加密后的密文被存储在文件中,等待后续的读取或传输。
(2)读取过程(解密、解压、反序列化)
解密:当需要读取文件中的数据时,首先需要使用正确的密钥和加密算法对密文进行解密,恢复为压缩前的数据。
解压:解密后,应用解压算法对数据进行解压,恢复到序列化前的状态。
反序列化:解压后的数据是一个二进制格式,需要进行反序列化,将其转换为内存中的对象。反序列化是序列化的逆过程,它将二进制数据转换为可读可操作的数据结构。
内存对象:经过解密、解压和反序列化之后,数据最终以内存对象的形式被程序处理。
五、StarRocks 读取 ORC 加密文件实现方案
5.1 ORC文件内部数据加密关系
首先,介绍几个密钥的含义:
statKey:用于解密加密列的FileStat,StripeStat的密钥,每个列一个,加密存储在文件Footer里。
dataKey:用于解密加密列的IndexData 和 RowData,每个Stripe的每一列都有一个,加密存储在Stripe的Footer里。
masterKey:文件的根密钥,用于解密ORC文件中被加密的statKey 和 dataKey,该密钥没有存储在文件中,一般存储在Hive表属性上。要解密ORC文件中的数据,首先需要获取这个masterKey。然而,masterKey本身也是加密的,因此在读取Hive表之前,必须先从表属性中提取出加密的masterKey,访问密钥管理服务(Key Management Service, KMS),对加密的masterKey进行解密,从而获得可用于实际解密操作的明文masterKey密钥,一旦获得了masterKey的明文形式,就可以用它来解密ORC文件中的dataKey和statKey。
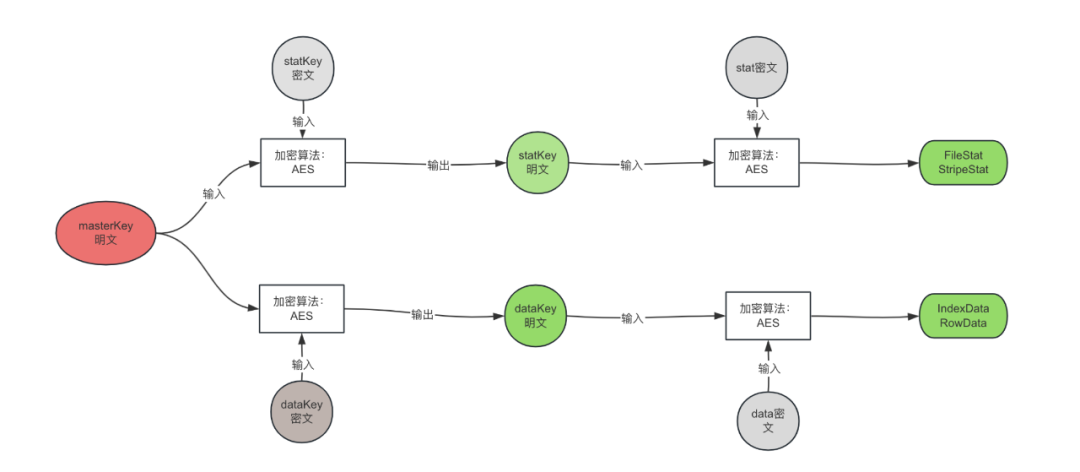
下图是描述了masterKey、statKey,dataKey之间的关系,灰色部分代表是存储在文件中被加密的数据,绿色部分则是解密之后的数据,包括我们解密后的statKey,dataKey。获得这两个密钥之后分别用于解密统计信息和文件中的真实数据。
5.2 StarRocks读取ORC加密文件流程
在深入掌握了ORC文件中密钥的相互关系和功能后,我们现在转向探讨StarRocks是如何读取ORC加密表的数据。这个过程如下图所示:
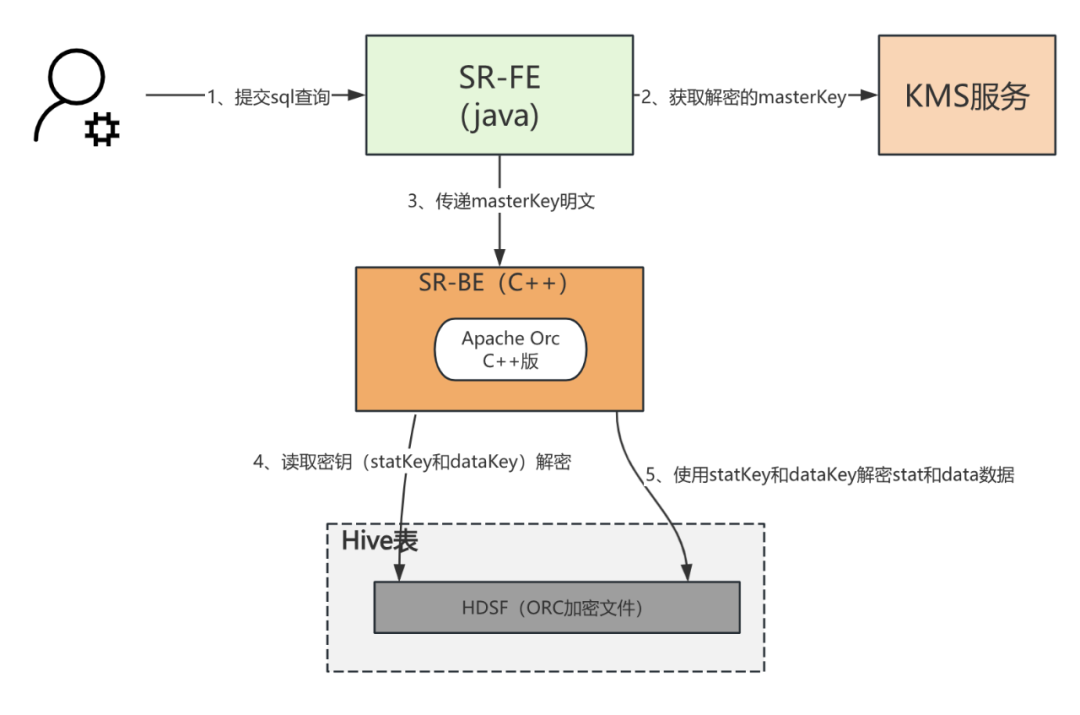
1)提交SQL查询:用户首先通过SQL客户端向StarRocks FE节点提交查询请求。这通常涉及到对Hive表下存储的ORC加密文件进行读取操作。
2)获取解密的masterKey:查询提交后,系统首要根据SQL获取Hive表中的ORC文件所需的masterKey。这个masterKey一般存储在表属性里,并且是加密存储的,必须调用KMS服务来解密,得到密钥明文。
3)传递masterKey明文:解密后的masterKey,以明文形式传递给StarRocks BE节点。
4)读取并解密密钥:BE 拿到已解密的masterKey 之后 读取并解密ORC文件中的statKey和dataKey,这两个密钥分别用于解密统计信息(FileStat,StripeStat)和实际数据内容,为接下来的统计信息和数据解密做准备。
5)使用statKey和dataKey解密数据:BE使用statKey来解密文件的统计信息(fileStat和StripeStat)同时使用dataKey来解密实际的数据内容。
5.3 读取ORC加密文件的关键实现细节
通过了解前文StarRocks读取ORC加密文件流程,我们将深入探讨读取ORC加密文件的数据关键实现细节。首先,我们提出一个问题:在物理存储中,文件存储的是什么内容?答案是二进制数据。这些二进制数据通常会经过压缩处理。
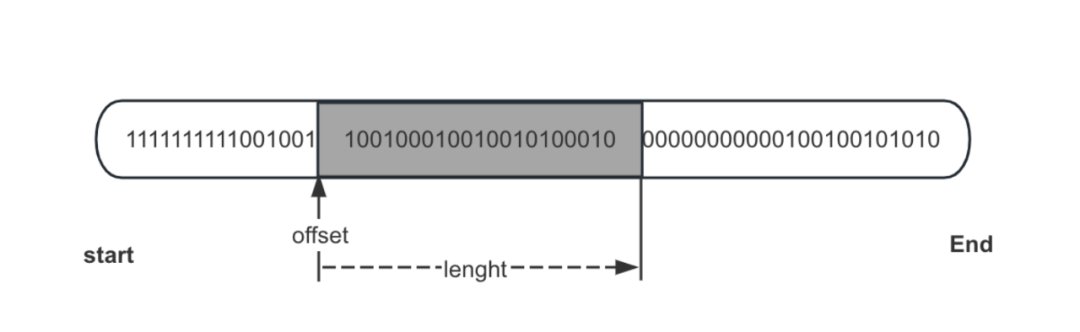
ORC文件的读取流程是自外向内的,类似于剥洋葱的过程,逐步深入到我们需要读取的目标数据。读取流程可以概括为:首先读取文件元数据,通过元数据获取目标数据的偏移量(offset)和数据长度如下图所示,然后通过流的方式读取目标数据。
具体到ORC加密文件的读取实现代码,主要采用了设计模式中的装饰模式方式来组织代码的。在这个模式中,原始的文件流(SeekableFileInputStream)首先被解密流(DecryptionInputStream)所包装,如果是非加密文件就没有这一层,然后解密流又被解压缩流(DecompressionStream)所包装。每一层流都只负责向其包装的流请求数据,并在接收到一定量数据后开始处理自己的逻辑。如下图所示:
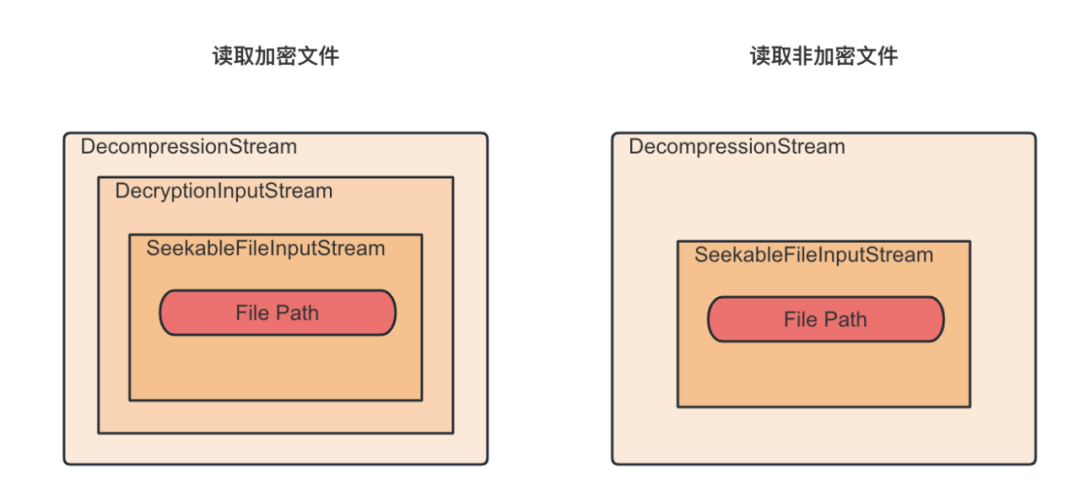
这种分层的方法保证每一层都专注于自己的职责,共同协作完成ORC文件的读取任务。通过这种方式,我们不仅能够高效地读取ORC文件,还能确保数据的安全性和完整性。综上所述,ORC文件的读取流程是一个从文件元数据到具体数据内容的逐步深入过程。
5.4 加密字段跳读机制
为了提升数据的查询效率,查询数据时会根据索引数据跳过不必要的数据读取,下面我们介绍加密列跳读机制,理解了这部分的内容,就能非常清晰的知道,读取加密字段时,对数据解密与解压是怎样协作的。
5.4.1 加密块与压缩块的关系
加密列的数据划分了多个加密块与压缩块,一个压缩块 包含多个加密块,读取数据时,先对每个加密块进行解密,解密多个加密块之后,把这些解密后的数据块合并成一个完整的压缩块,然后对这个压缩块进行解压得到原始数据下图是加密块与压缩块的关系图:
5.4.2 ORC文件使用的加解密算法和模式
下图描述了具体的数据加解密过程中以及设计到整个过程中各种元素输入输出的关系:
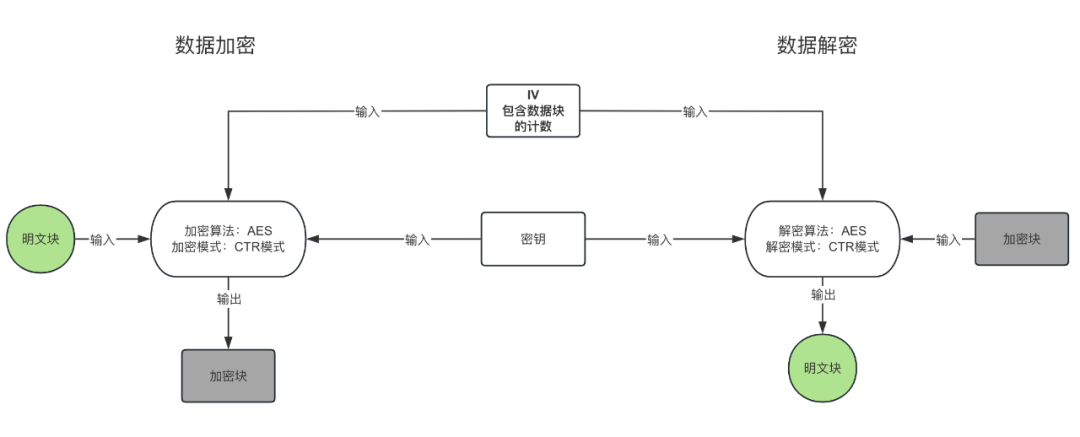
注意:同一个数据块(16字节)加密过程和解密过程中的 密钥、IV值、加密算法和加密模式必须相同。
明文块:我们对ORC文件加密使用的加密算法是AES-128-CTR/NoPadding,该算法加密数据时 ,会把明文按照16个字节划分多个块,每个块加密之后得到的数据就是加密块。
加密块:每个明文数据块加密之后得到的数据就是加密块。
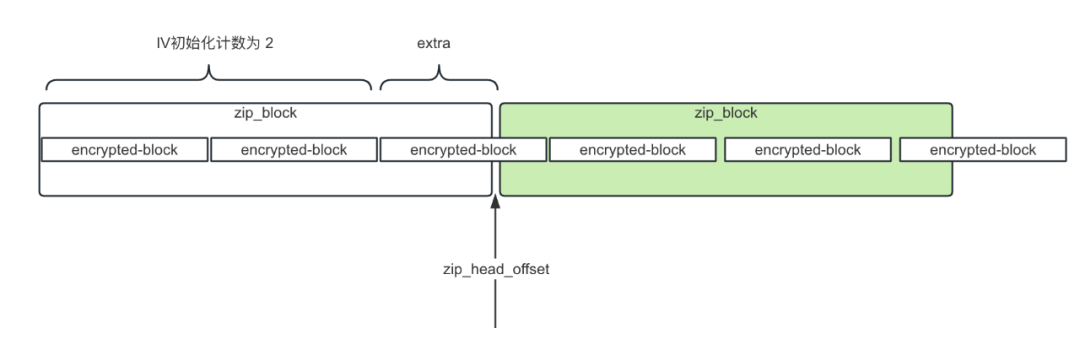
初始向量IV:初始向量IV的作用是使加密更加安全可靠(加盐),我们使用AES加密时需要主动提供这个初始向量IV,而且只需要提供一个初始向量就够了,后面每个数据块的加密向量由加密模式决定,所以每个数据块的加密向量都不一样。初始向量IV的长度规定为128位16个字节,ORC文件解密参数 IV的描述如下:总共16个字节,前面8个字节分别存储:列ID,Stream类型,Stripe的ID ,后面8个字节用于填充min_count,由于我们使用的是CTR加密模式,所以这个min_count就是加密块在整个加密数据中的计数,iv各个内容长度定义如下图:

密钥:AES要求密钥的长度可以是128位16个字节、192位或者256位,位数越高,加密强度自然越大,但是加密的效率自然会低一些,因此要做好权衡。我们开发通常采用128位16个字节的密钥,我们使用AES加密时需要主动提供密钥,而且只需要提供一个密钥就够了,每个数据块加解密使用的都是同一个密钥。
加密模式:有5种加密模式,这些加密模式的主要目的是为了不让重复的明文加密之后得到的密文一样,提升数据安全性,我们使用的是CTR模式(计数器模式)对数据加密,那解密的时候也需要CTR模式对数据解密,计数器模式介绍请参考链接,CTR模式 的iv参数 包含了 加密块计数(min_count),所以 每次对一个加密块解密时 需要知道 当前加密块的初始计数值。
5.4.3 举例说明跳读流程
学习了前面读取加密数据的关键细节之后,举个例子说明跳读ORC文件流程,假设根据索引数据和查询条件确定需要读取某个文件中第1个Strip中第1列的第5个group的数据,那么我们知道group5数据的偏移量offset,文件结构如下图所示:
具体逻辑大体流程如下:
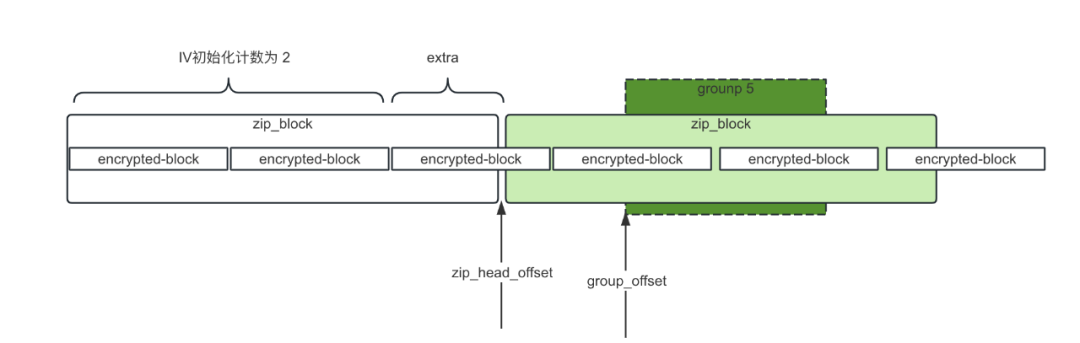
注意:解压数据块时,必须把当前解压块的所有数据读出来才能使用对应的解压算法解压数据。
1)group5数据的偏移量group_offset计算出 group5数据在哪个压缩块里,计算公式为:block_index = group_offset/zipBlockSize(压缩块大小),并得到该压缩块的起始位置zip_head_offset 公式为:zip_head_offset = block_index*zipBlockSize。
2)获取zip_head_offset位置对应的加密块计数,加密块计数值计算公式为:min_count = zip_head_offset/encrypted-size(加密块大小) 更新iv向量的min_count值。
3)文件读指针定位到zip_head_offset,开始读取压缩块的数据,这个压缩块的数据全部读出之后,使用解压算法进行解压。
4)通过group5在解压的数据上偏移量和长度,读取group5 数据,然后再对数据进行解码。
六、问题解答
通过前面对相关内容的讲解,下面我们来解答前文提出的问题:
1)文件解压是否意味着一定是对整个文件进行解压操作?
答:不需要,文件是按照一定大小划分出若干个压缩块,只要读出相应的压缩块进行解压就行。
2)ORC 文件究竟是如何做到在不扫描全文件的情况下就能精准查询到想要的数据?
答:ORC文件有三层索引,在读取文件数据之前先读取各层级的索引信息,根据过滤条件过滤掉不必要的数据扫描,从而提升数据查询效率。
3)当 SQL 查询条件不符合最左前缀原则时,其索引效果是否就会失效呢?
答:不会失效,ORC文件是列式存储的,各列信息都是相互独立的,有自己的索引信息,与行式数据库的索引最左前缀规则不同。
4)数据加密、解密、解压以及压缩之间的关联关系到底是怎样的?
答:请参考本文:5.1 ORC文件内部数据加密关系 内容。
5)在写加密列数据时,为什么不是先加密数据再压缩,而是先压缩后加密?
答:主要是为了提升加密效率,数据被压缩处理之后,数据量变少了,加密效率就提升了。
七、总结
本文介绍了StarRocks数据库如何读取ORC文件的加密数据,包括相关概念理解、ORC文件介绍、以及StarRocks读取加密ORC文件的具体实现方案。阐述了出于数据安全的需要,对Hive表中的敏感数据进行加密存储的必要性,介绍了对称加密、文件压缩与解压、加密压缩文件读写流程等概念,深入探讨了ORC文件的三层结构和索引机制,以及如何利用这些特性实现高效查询加密数据。还详细描述了StarRocks读取加密ORC文件的流程,包括获取解密的masterKey、使用masterKey解密ORC文件中的密钥、以及使用这些密钥解密数据。
希望通过本文对ORC加密文件读取功能的实现细节,让读者对ORC文件的理解更深刻。最后如果想从代码层面了解ORC文件解密过程可以参考开源PR。
深度剖析 StarRocks 读取 ORC 加密文件背后的技术的更多相关文章
- spark SQL读取ORC文件从Driver启动到开始执行Task(或stage)间隔时间太长(计算Partition时间太长)且产出orc单个文件中stripe个数太多问题解决方案
1.背景: 控制上游文件个数每天7000个,每个文件大小小于256M,50亿条+,orc格式.查看每个文件的stripe个数,500个左右,查询命令:hdfs fsck viewfs://hadoop ...
- .NET5.0 单文件发布打包操作深度剖析
.NET5.0 单文件发布打包操作深度剖析 前言 随着 .NET5.0 Preview 8 的发布,许多新功能正在被社区成员一一探索:这其中就包含了"单文件发布"这个炫酷的功能,实 ...
- 读取本地json文件,转出为指定格式json 使用Base64进行string的加密和解密
读取本地json文件,转出为指定格式json 引用添加Json.Net 引用命名空间 using Newtonsoft.Json //读取自定目录下的json文件StreamReader sr = ...
- 腾讯刘金明:腾讯云 EB 级对象存储架构深度剖析及实践
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 演讲者:刘金明 腾讯云存储业务中心副总监 背景:5月23-24日,以"焕启"为主题的腾讯"云+未来" ...
- 大众点评开源分布式监控平台 CAT 深度剖析
一.CAT介绍 CAT系统原型和理念来源于eBay的CAL的系统,CAT系统第一代设计者吴其敏在eBay工作长达十几年,对CAL系统有深刻的理解.CAT不仅增强了CAL系统核心模型,还添加了更丰富的报 ...
- QQ现状深度剖析:你还认为QQ已经被微信打败了吗?
本文来自“人人都是产品经理”公众号作者栗栗粥的原创分享. 1.前言 移动端的时代里,微信占据了社交领域的半壁江山,不得不让人想起曾经PC时代里的王者“QQ”,微信的爆发和QQ的停滞让很多人认为微信 ...
- 读书笔记之:C语言深度剖析
读书笔记之:C语言深度剖析 <C 语言深度解剖>这本书是一本“解开程序员面试笔试的秘密”的好书.作者陈正冲老师提出“以含金量勇敢挑战国内外同类书籍”,确实,这本书中的知识点都是一些在面试中 ...
- Spark- Spark内核架构原理和Spark架构深度剖析
Spark内核架构原理 1.Driver 选spark节点之一,提交我们编写的spark程序,开启一个Driver进程,执行我们的Application应用程序,也就是我们自己编写的代码.Driver ...
- [转帖]深度剖析一站式分布式事务方案 Seata-Server
深度剖析一站式分布式事务方案 Seata-Server https://www.jianshu.com/p/940e2cfab67e 金融级分布式架构关注 22019.04.10 16:59:14字数 ...
- Mysql binlog应用场景与原理深度剖析
1 基于binlog的主从复制 Mysql 5.0以后,支持通过binary log(二进制日志)以支持主从复制.复制允许将来自一个MySQL数据库服务器(master) 的数据复制到一个或多个其他M ...
随机推荐
- unity assetbundle 加载图集的所有sprite图片
在 Unity 中,使用 AssetBundle 加载图集(Atlas)并获取其中的所有 Sprite 图片,通常需要以下步骤: 1. 打包图集到 AssetBundle 首先,确保你的图集(At ...
- w3cschool-spring详解
参考地址 https://www.w3cschool.cn/wkspring/dcu91icn.html Spring 体系结构 2021-11-03 18:18 更新 体系结构 Spring 有可能 ...
- 解决安装python各种包速度慢问题
# 改用清华镜像库 pip install ******* -i https://pypi.tuna.tsinghua.edu.cn/simple
- c++:-8
上一节学习了C++的STL库和范型:c++:-7,本节学习c++的输入输出和流类库. I/O流 (1)程序与外界环境的信息交换 当程序与外界环境进行信息交换时,存在着两个对象:程序中的对象.文件对象. ...
- Node.js 中 mysql 事务的写法
最近做一个公司内部的信息化平台,本着短平快,选择了 Nodejs + Express + Vue + mysql/mongodb 的技术路线. 该写法主要利用了递归,下面把事务的写法记录一下,做了简单 ...
- ADC温敏电阻测温
一.ADC采样电路 使用热敏电阻与连续逼近型寄存器 (SAR) 模数转换器 (ADC) 直接监测温度的电路.温度检测电路使用负温度系数 (NTC) 热敏电阻与电阻串联构成分压器. 参考电压:VCC 分 ...
- oracle下批量增加序列值
感谢renjixinchina分享 原文链接http://blog.itpub.net/15747463/viewspace-751593/ oracle下批量增加序列值.批量滚动序列 declare ...
- InfluxDB UI 设置保留策略
InfluxDB UI 设置保留策略 创建Bucket时设置保留策略 在InfluxDB 2.x的UI中创建Bucket时,你可以直接设置其保留策略.以下是一个基本的步骤指南: 登录到InfluxDB ...
- 本地部署DeepSeek-R1并使用自定义的知识库AnythingLLM
一.基础信息 1.概述 以下是私有化部署方案的优势: 性能卓越:提供媲美商业模型的对话交互体验 环境隔离:完全离线运行,杜绝数据外泄风险 数据可控:完全掌控数据资产,符合合规要求 2.硬件环境 CPU ...
- Luogu P11233 CSP-S2024 染色 题解 [ 蓝 ] [ 线性 dp ] [ 前缀和优化 ]
染色:傻逼题. 赛时没切染色的都是唐氏!都是唐氏!都是唐氏!都是唐氏!都是唐氏!都是唐氏!都是唐氏! 包括我. 真的太傻逼了这题. 我今晚心血来潮一打这题,随便优化一下,就 AC 了. 怎么做到这么蠢 ...