MySQL 25 MySQL是怎么保证高可用的?
正常情况下,只要主库执行更新生成的所有binlog,都可以被传到备库并被正确地执行,备库就能达到跟主库一致的状态,这就是最终一致性,而MySQL要提供的高可用能力,只有最终一致性是不够的。
主备延迟
主备切换可能是一个主动运维动作,比如软件升级、主库所在机器按计划下线等,也可能是被动操作,比如主库所在机器掉电。
先看主动切换的场景。首先介绍同步延迟的概念,与数据同步有关的时间点主要包括三个:
主库A执行完成一个事务写入binlog,将这个时刻记为T1;
之后传给备库B,把备库B接收完这个binlog的时刻记为T2;
备库B执行完这个事务,将这个时刻记为T3。
主备延迟指的是,同一个事务主备库执行完成的时间差,即T3-T1。
可以在备库上执行show slave status命令,其返回结果里会显示seconds_behind_master,这个值计算的就是T3-T1。
如果主备库机器的系统时间设置不一致,会不会导致主备延迟的值不准呢?答案是不会的,备库连接到主库的时候,会通过执行SELECT UXIN_TIMESTAMP()函数来获得当前主库的系统时间,如果此时发现两库系统时间不一致,备库执行seconds_behind_master计算时会扣除该差值。
网络正常时,T2-T1是很短的,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。所以,主备延迟最直接的表现是,备库消费中转日志(relay log)的速度,比主库生产binlog的速度要慢。
主备延迟的来源
首先,有些部署条件下备库所在机器性能要比主库所在的机器性能差。
有些人部署时想着反正备库没有请求,可以用差一点的机器,但实际上更新过程也会触发大量读操作,当备库主机上的多个备库都在争抢资源时,就可能导致主备延迟。
现在这种部署比较少了,因为主备可能随时切换,所以主备库一般选用相同规格的机器,并且做对称部署。
第二,备库的压力大。
备库一般用来提供一些读能力,如果大量查询,备库上的查询可能耗费大量CPU资源,影响同步速度,造成主备延迟。
这种情况一般的处理方法:
一主多从,让多个从库分担读的压力;
通过binlog输出到外部系统,比如Hadoop,让外部系统提供统计类查询能力。
第三是大事务。
主库上必须等事务执行完才会写入binlog再传给备库。那么,如果一个主库上的语句执行10分钟,意味着这个事务可能会导致从库延迟10分钟。常见的大事务有一次性用delete删除大量数据、大表DDL等。
第四是备库的并行复制能力,这个下篇文章再介绍。
由于主备延迟的存在,所以在主备切换的时候,就相应的有不同的策略。
可靠性优先策略
上篇文章提到的双M结构:
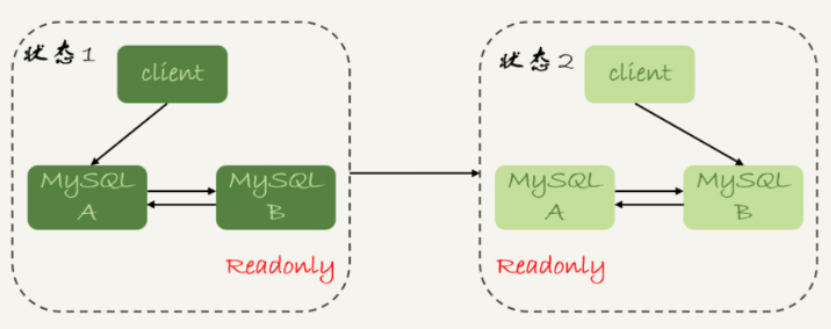
双M结构下,状态1切换到状态2的详细过程:
判断备库B现在的seconds_behind_master,如果小于某个值(如5秒)继续下一步,否则持续重试这一步;
将主库A改成只读状态;
判断备库B的seconds_behind_master,直到这个值变成0;
将备库B改成可读写状态;
把业务请求切换到备库B。
我们暂时把这个切换流程称为可靠性优先流程。
可以发现,这个切换流程中,在步骤2之后,主备库都处于readonly状态,即系统处于不可写状态,直到步骤5完成后才能恢复。在这个不可用状态中,步骤3比较耗时,这也是为什么在步骤1先确保seconds_behind_master足够小,不然不可用时间可能会很长。
系统的不可用时间,是由数据可靠性优先的策略决定的。也可以选择可用性优先的策略,把这个不可用的时间几乎降为0。
可用性优先策略
如果强行把步骤45调整到最开始执行,即不等主备数据同步,直接把连接切到备库B且让备库B可以读写,那么系统几乎就没有不可用时间了。
暂时把这个切换流程称为可用性优先流程,该切换流程的代价是可能出现数据不一致的情况。
假设有一个表t:
mysql> CREATE TABLE `t` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`c` int(11) unsigned DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(c) values(1),(2),(3);
初始化数据后,主备库上都是3行数据,继续插入:
insert into t(c) values(4);
insert into t(c) values(5);
假设现在主库上其他的数据表有大量的更新,导致主备延迟达到5秒,在插入一条c=4的语句后,发起了主备切换。
当使用可用性优先策略,且binlog_format=mixed时切换流程如下:
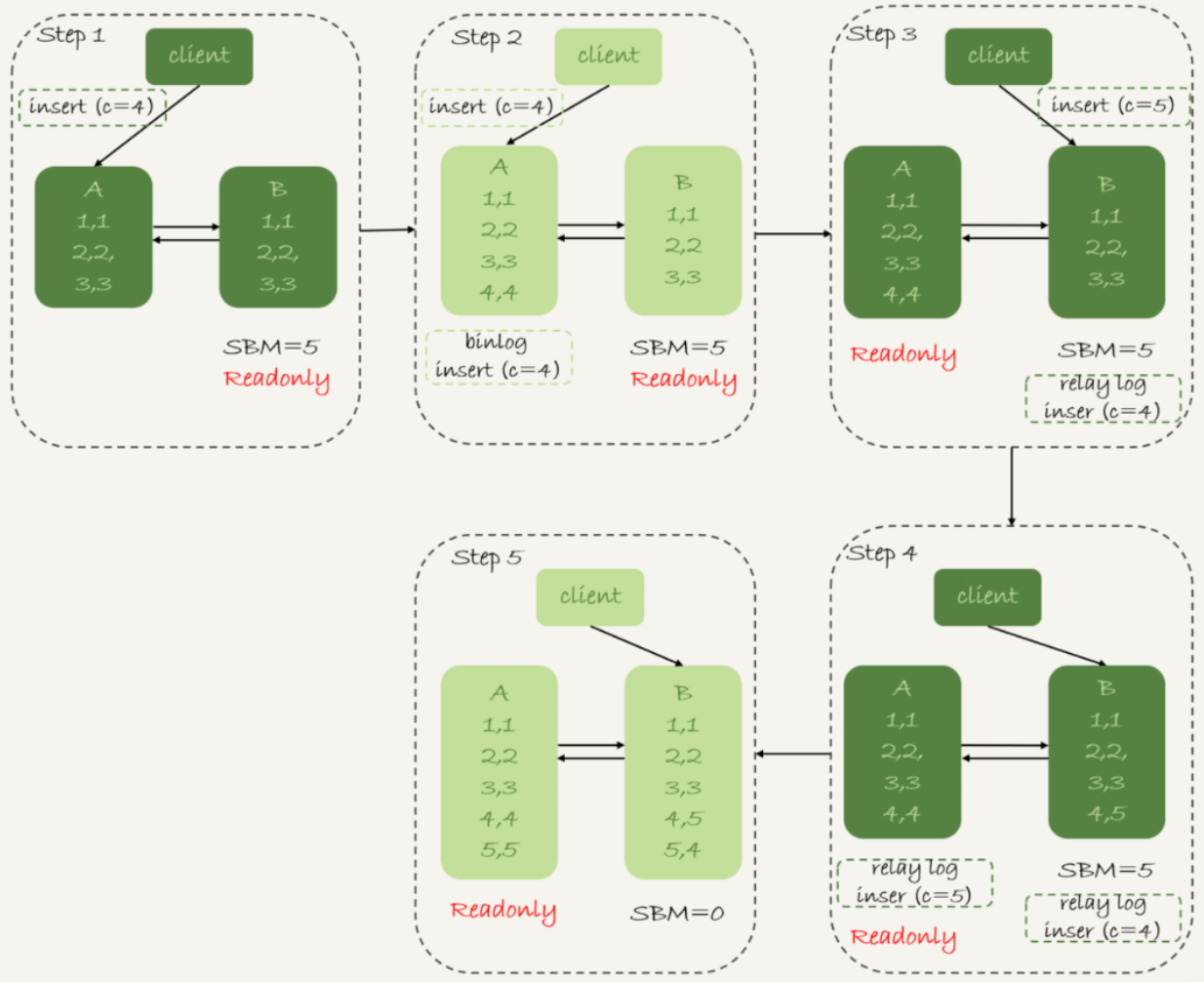
图中的SBM,是seconds_behind_master参数的简写。
step 2中,主库A执行完insert插入(4,4),之后开始进行主备切换;
step 3中,由于主备之间有5秒延迟,所以备库B还没来得及应用插入
c=4中转日志,就开始接收客户端插入c=5的命令;step 4中,备库B插入一行数据(4,5),并把这个binlog发给主库A;
step 5中,备库B执行插入
c=4的日志,插入一行数据(5,4),而前面的语句传到主库A,会在主库插入(5,5)。
因此最后出现主备不一致的情况。
当使用可用性优先策略,且binlog_format=row时切换流程如下:
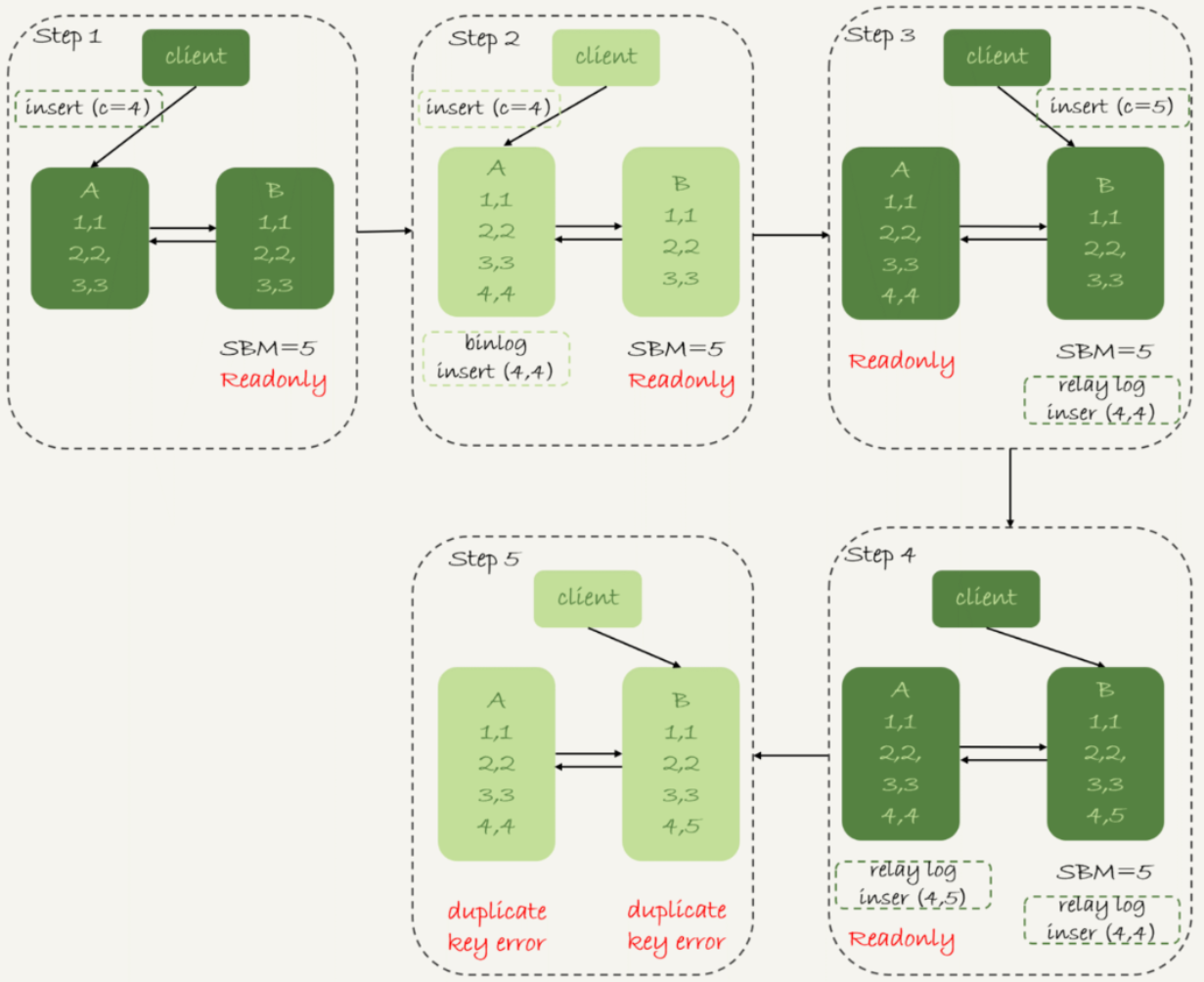
由于row格式在记录binlog时会记录新插入的行的所有字段值,所以最后只会有一行不一致,且两边的主备同步的应用线程会报错duplicate key error并停止。即备库B的(5,4)和主库A的(5,5)两行数据都不会被对方执行。
从上面的分析中,可以看到一些结论:
使用row格式的binlog时,数据不一致问题更容易被发现,而使用mixed或者statement格式的binlog,可能数据不一致而没有发现;
主备切换的可用性优先策略会导致数据不一致,因此大多数情况都建议使用可靠性优先策略。
但也有情况数据的可用性优先级更高。比如一个库的作用是记录操作日志,这时如果数据不一致可以通过binlog来修补,短暂的不一致不会引发业务问题,而业务系统又依赖这个日志,如果这个库不可写会导致线上的业务操作无法执行。这时就需要先强行切换,事后再补数据的策略。
当然也能改进,比如让业务逻辑不要依赖于这类日志的写入,那就又可以使用可靠性优先策略。
最后总结:在满足数据可靠性的前提下,MySQL高可用系统的可用性,是依赖于主备延迟的。延迟的时间越小,在主库故障的时候,服务恢复需要的时间就越短,可用性就越高。
MySQL 25 MySQL是怎么保证高可用的?的更多相关文章
- Mysql双主互备+keeplived高可用架构介绍
一.Mysql双主互备+keeplived高可用架构介绍 Mysql主从复制架构可以在很大程度保证Mysql的高可用,在一主多从的架构中还可以利用读写分离将读操作分配到从库中,减轻主库压力.但是在这种 ...
- Mysql+Keepalived双主热备高可用操作记录
我们通常说的双机热备是指两台机器都在运行,但并不是两台机器都同时在提供服务.当提供服务的一台出现故障的时候,另外一台会马上自动接管并且提供服务,而且切换的时间非常短.MySQL双主复制,即互为Mast ...
- 【转】单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美图公司数据库高级DBA,负责美图后端数据 ...
- [转载] 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
原文: http://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=209406532&idx=1&sn=2e9b0cc02bdd ...
- Mysql双主互备+keeplived高可用架构(部分)
一.Mysql双主互备+keeplived高可用架构介绍 Mysql主从复制架构可以在很大程度保证Mysql的高可用,在一主多从的架构中还可以利用读写分离将读操作分配到从库中,减轻主库压力.但是在这种 ...
- (转载)MySQL数据库的几种常见高可用方案
转自: https://yq.aliyun.com/articles/74454 随着人们对数据一致性的要求不断的提高,越来越多的方法被尝试用来解决分布式数据一致性的问题,如MySQL自身的优化. ...
- 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
015-08-09 杨尚刚 高可用架构 此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美 ...
- MySQL/MariaDB数据库的MHA实现高可用实战
MySQL/MariaDB数据库的MHA实现高可用实战 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MySQL高可用常见的解决方案 1>.Multi-Master ...
- 25 mysql怎么保证高可用
上一篇介绍了binlog的基本内容,在主备关系中,是每个备库接收主库的binlog并执行. 正常情况下,只要主库执行更新生成的所有的binlog,都可以传到备库并被正确执行,备库就能跟主库一致的状态, ...
- 25 | MySQL是怎么保证高可用的?
在上一篇文章中,我和你介绍了binlog的基本内容,在一个主备关系中,每个备库接收主库的binlog并执行. 正常情况下,只要主库执行更新生成的所有binlog,都可以传到备库并被正确地执行,备库就能 ...
随机推荐
- AI写程序: 多线程网络扫描网段ip工具
IP Scanner - 多线程网络扫描工具 项目简介 IP Scanner 是一个基于 Python 开发的网络扫描工具,它能够快速扫描指定网段内的活动 IP 地址.该工具采用多线程技术提高扫描效率 ...
- 边学边练,福利无限 —— OceanBase DBA 实战营(第一季)火热进行中!
首先为大家推荐这个 OceanBase 开源负责人老纪的公众号 "老纪的技术唠嗑局",会持续更新和 OceanBase 相关的各种技术内容.欢迎感兴趣的朋友们关注! 活动背景 20 ...
- 一文掌握 HarmonyOS5 模拟器与真机调试技巧
前言 DevEco Studio 的预览器可以提供高效的 UI 实时反馈,但要进行全面的功能测试.性能分析及硬件相关功能调试,仍需在模拟器或真机上运行应用. 模拟器的安装与启动参考往期文章:[Harm ...
- Chiplet封装技术的应用现状
这是IC男奋斗史的第39篇原创 本文1651字,预计阅读4分钟. 接上文:Chiplet解决芯片技术发展瓶颈 Chiplet封装的产品介绍 以下介绍几款国内外使用Chiplet封装技术的代表产品,包括 ...
- C# 数字(阿拉伯数字)金额转汉字金额 人民币操作类 :转换人民币大小金额。
/// <summary> /// 转换为人民币大写金额形式 /// </summary> /// <param name="Money">金额 ...
- java--Struts拦截器、国际化、标签
拦截器 Intercetor, 即为拦截器. 1) 在Struts2中,把每一个功能都用一个个的拦截器实现:用户想用struts的哪个功能的时候,可以自由组装使用. 2)Struts2中,为了方法用户 ...
- java--xml约束、tomcat服务器
xml约束 XML语法: 规范的xml文件的基本编写规则.(由w3c组织制定的) XML约束: 规范XML文件数据内容格式的编写规则.(由开发者自行定义) DTD约束 DTD约束:语法相对简单,功能也 ...
- pdfjs-dist v3.x渲染pdf
import './App.css' import * as pdfjsLib from "pdfjs-dist"; import { useEffect, useRef, use ...
- vue启动入口
两个地方可以配置 方法一:修改packge.json启动命令参数 "scripts": { "serve": "vue-cli-service ser ...
- java 中的访问限制
简介 1)仅对本类可见--private 2) 对所有类可见--public 3) 对本包和所有子类可见--protected 4) 对本包可见--默认,不需要修饰符