keras 入门 (一)
1.Keras 简介
Keras 是一个高层神经网路的API , 特点就是简单易用
keras 是目前流行的深度学习框架里面,最简单的。
keras后台调用了 Tensorflow,Microsoft-CNTK 和 Theano
2.线性回归模型
代码如下:
注意。plt.scatter 是绘制散点图,plt.plot是绘制经过点的曲线
import keras
import numpy as np
import matplotlib.pyplot as plt
#调用GPU
"""GPU设置为按需增长"""
import os
import tensorflow as tf
import keras.backend.tensorflow_backend as KTF
# 指定第一块GPU可用
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto()
config.gpu_options.allow_growth=True #不全部占满显存, 按需分配
# config.gpu_options.per_process_gpu_memory_fraction = 0.3
sess = tf.Session(config=config)
KTF.set_session(sess)
#调用GPU代码部分结束
#按顺序构成的模型,最简单的,一层层的.
from keras.models import Sequential
# 全连接层
from keras.layers import Dense
#使用 numpys随机生成点
#再随机生成一些噪音.
x_data=np.random.rand(100)
noise=np.random.normal(0,0.01,x_data.shape)
y_data=x_data*0.1+0.2+noise #一条线
#显示随机点
plt.scatter(x_data,y_data)
plt.show()
#构建一个顺序模型
model=Sequential()
#在模型中添加一个全连接层
model.add(Dense(units=1,input_dim=1))#输出是一维的,输入也是一维的
#因为会输入一个x的值,输出一个y的值.
#sgd 随机梯度下降法
#mse 均方误差
model.compile(optimizer='sgd',loss='mse')
#训练模型
for step in range(5001):
#每次都训练一个批次
cost=model.train_on_batch(x_data,y_data)#每次放入一个批次进行训练
#每500个cost打印一次cost值.
if step%500==0:
print("cost 的值 ",cost)
#打印权值和偏置值
# #只有一层,所以是0
# 因为输入是1,输出是1,所以也只有一个权值.
W,b=model.layers[0].get_weights()
print("W****",W,"b*****",b)
# 把x_data 放进网络中,预测 y_pred
y_pred=model.predict(x_data)
#打印出来,显示随机点
#上边已经打印了,这里就不写了
#显示预测结果
plt.scatter(x_data,y_data) #scatter是绘制散点图.
#预测值为红色,宽度为3
plt.plot(x_data,y_pred,"r-",lw=3)
plt.show()
输出结果可以看出,损失在不断的减小:
画出的图像:
预测的图像:
3.非线性回归
和上边比较简单的线性回归的区别:
- 使用一层网络是不够的。
- 要添加非线性的激活函数
- 原来的优化算法的学习率太低,要改进优化算法
Ctril + Q 是显示函数解释的快捷键。
具体代码如下:
import numpy as np
import matplotlib.pyplot as plt
#按顺序构成的模型,最简单的,一层层的.
from keras.models import Sequential
# 全连接层,和激活函数
from keras.layers import Dense,Activation
#从优化器里到处SGD
from keras.optimizers import SGD
#生成200个从-0.5到0.5的数字
x_date=np.linspace(-0.5,0.5,200)
#记入噪音
noise=np.random.normal(0,0.02,x_date.shape)
#y 是平方后的 + 噪音
y_data=np.square(x_date)+noise
# 把点显示出来看一下;
plt.scatter(x_date,y_data)
plt.show()
#上一节只有一层的神经网络,很难拟合出来复杂的曲线;
#下边要两层才行;
# dim 维度.
#自定义优化算法
#使用 ctrl + Q 函数说明快捷方式.
#网络结构 1-10-1
model=Sequential()
model.add(Dense(units=10,input_dim=1)) #指定中间层和输出层.
model.add(Activation('tanh'))#添加激活函数
model.add(Dense(units=1,activation="tanh")) #此处的输入不需要参加,会根据上边自动的生成
#model.add(Activation('tanh'))#添加激活函数,也可以从里面添加
#使用 tanh 比较光滑,使用 relu 比较硬
#添加损失函数和优化算法;
sgd=SGD(lr=0.3) #由原来默认的0.1改成0.3
model.compile(optimizer=sgd,loss="mse")#优化函数不需要使用引号
#算上 3000 次
for step in range(3001):
cost=model.train_on_batch(x_date,y_data)
if step%500==0:
print("cost ******* ",cost)
#打印出预测值
y_pred=model.predict(x_date)
#画出来看一下;
plt.scatter(x_date,y_data)
plt.plot(x_date,y_pred,"r-",lw=3)
plt.show()
#使用sgd 是不行的,学习率太小,需要迭代的次数过多。
打印出来的结果:

预测后的结果:

4. MNIST 数据集
MNIST 数据集,分为两部分,60000行训练集,10000行测试集
每张图片包含 28*28 个像素,那么在 MNIST 训练数据集中是一个 [60000,784] 的张量,首先,我们要数据集转成【60000,784】,然后放到网络里面训练,第一个维度是索引图片,第二个维度是索引图片的像素点。一般的我们会把图片的数据归一化到 0-1 之间(把每个矩阵的 226 值归一化到0-1之间)。

MNIST 数据集的标签: 是介于 0-9 的数字,我们把标签转化成 “ one-hot vectors ”, 例如标签 0 就是 [1,0,0,0,0,0,0,0,0,0] ,标签 3 就表示为 [0,0,1,0,0,0,0,0,0,0]。因此,MNIST数据集的标签 就是一个 [60000,10]的一个数据矩阵。
因为一次要传入一行,所以要将数据传出层为 784 ,输出层为10.
下图算是一层,注意了。

6. 使用 MNIST 数据集,要使用 softmax 函数,一般翻译为概率,用法如下:
5.MNIST 实现代码
用目前所学的方法,精确度只能提高到 91% 。。
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD #优化函数;
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (6000,28,28) -> (6000,784)
x_train=x_train.reshape(x_train.shape[0],-1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(x_test.shape[0],784)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#创建模型,输入784个神经元,输出10个神经元
model=Sequential()
# 偏置的初始值. 激活函数.
model.add(Dense(units=10,input_dim=784,bias_initializer="one",activation='softmax'))
# 优化器,训练过程种计算准确率。
# lr 表示学习率
sgd=SGD(lr=0.2)
model.compile(optimizer=sgd,loss='mse',metrics=['accuracy'])#同时计算精确度.
#训练的方式
#训练的批次是32,迭代周期是 10 把6w 张图片训练完一次是一次轮回,现在是 10 次轮回.
model.fit(x_train,y_train,batch_size=32,epochs=10)
#评估模型;
loss,accuracy=model.evaluate(x_test,y_test)
print("loss*********",loss)
print("accuracy*******",accuracy)
运行结果:

我在下边又加了一层,但是准确率反而低了
张量的概念:
几何代数中定义的张量是基于向量和矩阵的推广,通俗一点理解就是,我们可以将标量视为 0 阶张量,矢量视为一阶张量,矩阵就是二阶张量。
6.交叉熵
- 交叉熵
- 代价函数
使用交叉熵的话,迭代速度会比较快,能比较快的出结果
代码:
#把损失函数换成交叉熵
lossa="categorical_crossentropy"
model.compile(optimizer=sgd,loss=lossa,metrics=['accuracy'])#同时计算精确度.
结果:

结果可以看出,第二轮的时候,就已经收敛到了 90% 多,收敛快的多
7.拟合
回归的情况
分类的情况:
如何避免出现拟合?
1.增大数据集
数据挖掘领域流行着这样的一句话,“ 有时候,拥有更多的数据,胜过一个好的模型 ”
增大图片的数据集:
- 随机裁剪
- 水平反转
- 光照颜色抖动
2.Early Stopping
- 在训练的时候,我们往往会设置一个比较大的迭代次数,Early stopping 便是一种提前结束训练的策略,用来防止过拟合。
- 一般的做法是记录到目前为止,最好的 validation accuracy,当连续 10 个 Epoch 没有达到最佳 accuracy 时,这认为 accuracy 不再提高了,就可以停止迭代了( Early Stopping)
3.Dropout
他的意思就是说,在迭代的时候,随机的让一些神经元不参与训练
drop 下落,drop out 退学

只是在训练的时候,让一些神经元参与网路,测试的时候,是要所有的神经元都要参与网络。
4.正则化项

让权值 w 减小,甚至趋近到0,L1 到0,L2是趋近与0,有点像 dropout。
λ 对正则化项的影响
可以看出 λ 越大,对消除过拟合的处理效果越好。

5.不加Dropout的代码:
加多层网络的简单写法
将激活函数改为 tanh 正切曲线(下边有介绍)
除了将测试集测试精度以外,还将训练集做为测试放进去
import numpy as np
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
from keras.layers import Dense,Dropout #导入Dropt
from keras.optimizers import SGD #优化函数;
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (6000,28,28) -> (6000,784)
x_train=x_train.reshape(x_train.shape[0],-1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(x_test.shape[0],784)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#创建模型的简单写法
# 偏置的初始值. 激活函数改为双曲正切.
model=Sequential([
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
Dense(units=100,bias_initializer='one',activation="tanh"),
Dense(units=10, bias_initializer='one', activation="softmax")
])
# 优化器,训练过程种计算准确率。
sgd=SGD(lr=0.2)
#把损失函数换成交叉熵
lossa="categorical_crossentropy"
model.compile(optimizer=sgd,loss=lossa,metrics=['accuracy'])#同时计算精确度.
#训练的方式
#训练的批次是32,迭代周期是 10 把6w 张图片训练完一次是一次轮回,现在是 10 次轮回.
model.fit(x_train,y_train,batch_size=32,epochs=10)
#评估模型;
loss,accuracy=model.evaluate(x_test,y_test)
print("test-loss*********",loss)
print("test-accuracy*****",accuracy)
#也可以放入训练的数据做一个测试:
loss,accuracy=model.evaluate(x_train,y_train)
print("train-loss*********",loss)
print("train-accuracy*****",accuracy)
运行结果:
由这个结果可以看出来,该模型在测试集和训练集的准确率是不一样的,所以就发生了过拟合的现象(当然这个并不是很明显,但是在很多其他的数据集上,会出现这个问题)。如果防止过拟合呢?其中的一个方法就是在 加入Dropout。
加了DropOut的代码
加 Dropout 层就可以直接在层中间加
Dropout(0.4), 让40%的神经元不工作.
import numpy as np
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
from keras.layers import Dense,Dropout #导入Dropt
from keras.optimizers import SGD #优化函数;
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (6000,28,28) -> (6000,784)
x_train=x_train.reshape(x_train.shape[0],-1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(x_test.shape[0],784)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#创建模型的简单写法
model=Sequential([
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
Dropout(0.4),#让40%的神经元不工作.
Dense(units=100,bias_initializer='one',activation="tanh"),
Dropout(0.4), #让40的神经元不工作.
Dense(units=10, bias_initializer='one', activation="softmax")
])
# 优化器,训练过程种计算准确率。
sgd=SGD(lr=0.2)
#把损失函数换成交叉熵
lossa="categorical_crossentropy"
model.compile(optimizer=sgd,loss=lossa,metrics=['accuracy'])#同时计算精确度.
#训练的方式
#训练的批次是32,迭代周期是 10 把6w 张图片训练完一次是一次轮回,现在是 10 次轮回.
model.fit(x_train,y_train,batch_size=32,epochs=10)
#评估模型;
loss,accuracy=model.evaluate(x_test,y_test)
print("test-loss*********",loss)
print("test-accuracy*****",accuracy)
#也可以放入训练的数据做一个测试:
loss,accuracy=model.evaluate(x_train,y_train)
print("train-loss*********",loss)
print("train-accuracy*****",accuracy)
运行结果:
注意: 此处主要是为了演示Dropout ,他的结果可能并不如不添加 Dropout的时候理想
tanh 双曲正切
常用的激活函数的一种。
6.正则化项代码:
代码:
正则化直接在 Dense 层里面加就可以。
正则化可以在三个地方加
- kernel_regularizer :在权重上加
- bias_regularizer: 在偏置值上加
- activity_regularizer :在激活函数上加
一般用的最多的是添加在权重上。
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
from keras.layers import Dense #导入Dropt
from keras.optimizers import SGD #优化函数;
from keras.regularizers import L2 #导入L2正则化。
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (6000,28,28) -> (6000,784)
x_train=x_train.reshape(x_train.shape[0],-1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(x_test.shape[0],784)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#创建模型的简单写法
model=Sequential([
#添加正则化项的参数是0.0003
# kernel_regularizer 是权值的正则化项.
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh",kernel_regularizer=L2(0.0003)),
Dense(units=100,bias_initializer='one',activation="tanh",kernel_regularizer=L2(0.0003)),
Dense(units=10, bias_initializer='one', activation="softmax",kernel_regularizer=L2(0.0003))
])
# 优化器,训练过程种计算准确率。
sgd=SGD(lr=0.2)
#把损失函数换成交叉熵
lossa="categorical_crossentropy"
model.compile(optimizer=sgd,loss=lossa,metrics=['accuracy'])#同时计算精确度.
#训练的方式
#训练的批次是32,迭代周期是 10 把6w 张图片训练完一次是一次轮回,现在是 10 次轮回.
model.fit(x_train,y_train,batch_size=32,epochs=10)
#评估模型;
loss,accuracy=model.evaluate(x_test,y_test)
print("test-loss*********",loss)
print("test-accuracy*****",accuracy)
#也可以放入训练的数据做一个测试:
loss,accuracy=model.evaluate(x_train,y_train)
print("train-loss*********",loss)
print("train-accuracy*****",accuracy)
运行结果:
8.优化器
综述
Optimizer 常用的是 梯度下降法,除此之外,还有其他的几种:
- SGD :误差反向传播法
- Adagrad
- AAdadelta
SGD
其实梯度下降法也分三种:
- 标准梯度下降法:计算所有样本,汇总误差,然后根据误差来更新权值
- 随机梯度下降法:随机抽取一个样本,计算误差,然后更新权值
- 批量梯度下降法:这是一种折中的方案,从总样本中抽取一个批次(例如抽取100个),然后计算一个 batch 的总误差,最后根据总误差来更新权值。
一般情况下我们默认使用的是批量梯度下降法。
Momentum
当前权重的改变,会受上一次权值改变的影响,类似于小球向下滚动的时候,带上了惯性,这样可以加快小球的向下速度。
NAG
相当于一个预先知道方向的更聪明的小球。
Adagrad
优势在于不需要人为的调节学习率,他可以自动的调节,他的缺点在于,随着迭代次数的增加,学习率会越来越低,最终趋向于 0 。
Adam
是常用的优化器,Adam会存储之前衰减的平方梯度,同时会保存之前衰减的梯度,经过一些处理以后,在用来更新权值 W
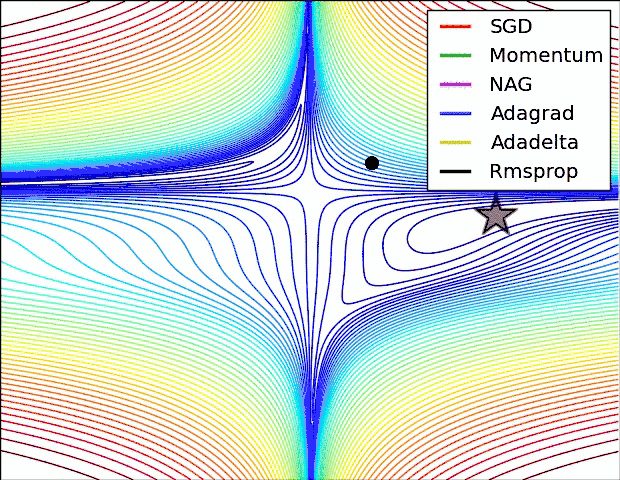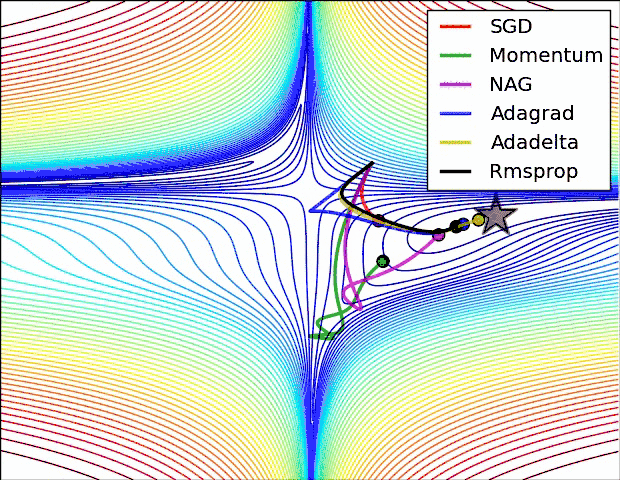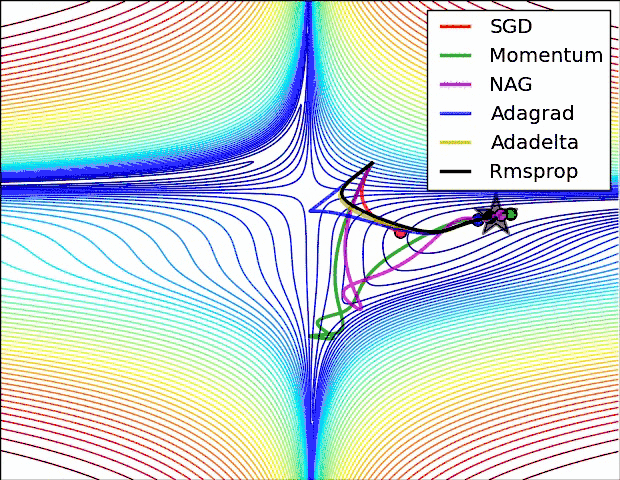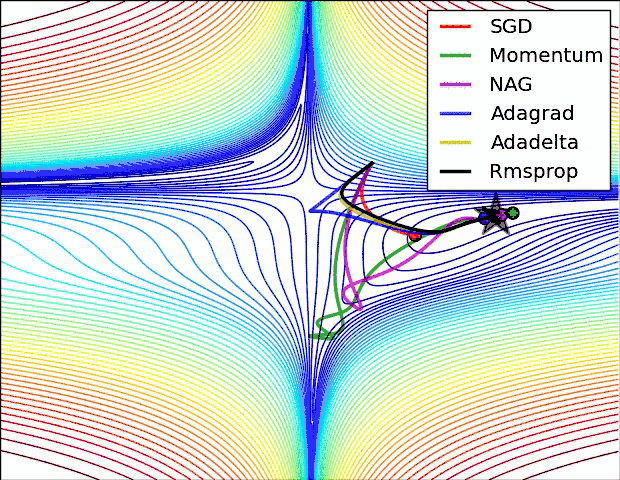
这里可以看出来:
SGD 是最慢的,但是并不代表优化的不好,Momentum虽然快,但是走了很多的弯路。
代码
将优化器改为 Adam
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
from keras.layers import Dense,Dropout #导入Dropt
from keras.optimizers import SGD,Adam #优化函数;
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (6000,28,28) -> (6000,784)
x_train=x_train.reshape(x_train.shape[0],-1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(x_test.shape[0],784)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#创建模型的简单写法
model=Sequential([
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
Dropout(0.4),#让40%的神经元不工作.
Dense(units=100,bias_initializer='one',activation="tanh"),
Dropout(0.4), #让40的神经元不工作.
Dense(units=10, bias_initializer='one', activation="softmax")
])
# 优化器,训练过程种计算准确率。
sgd=SGD(lr=0.2)
adam=Adam(lr=0.001)#默认的就是0.001
#把损失函数换成交叉熵
lossa="categorical_crossentropy"
model.compile(optimizer=adam,loss=lossa,metrics=['accuracy'])#同时计算精确度.
# 更常用的迭代方式。
model.fit(x_train,y_train,batch_size=32,epochs=10)
#评估模型;
loss,accuracy=model.evaluate(x_test,y_test)
print("test-loss*********",loss)
print("test-accuracy*****",accuracy)
#也可以放入训练的数据做一个测试:
loss,accuracy=model.evaluate(x_train,y_train)
print("train-loss*********",loss)
print("train-accuracy*****",accuracy)
9.CNN
卷积神经网络广泛应用于 图像处理 和 NLP
1.传统神经网络的缺点
传统的 BP 网络在处理图像的时候的问题:
- 权值太多,计算量太大。
- 权值太多,需要大量的样本进行训练。

比如一个100*100的图片进行处理,那么他的输入层就需要 1 万个输入神经元,隐藏层和输入层不会差太多,那么他也会有 1 万左右的神经元,那么之间的联系权重就会有一亿个。训练很麻烦,而且神经元越多,就需要越多的样本集进行求解。
2.局部感知机制
1962年哈佛医学院的神经生理学家,通过对猫视觉皮层细胞的研究,提出了感知野的概念。当猫看到兴奋的东西时,有的细胞兴奋,但是大部分的细胞是休眠状态。根据此,提出了局部感受野的状态
CNN通过局部感受野和权值共享,减少了神经网络需要训练的参数个数
权值共享:是指同一层的4个局部感受野的权值是共享的。

3.卷积核
卷积核又称滤波器

注意特征图的概念:
特征图卷积后,池化前的图形。
不同的卷积核,过滤完以后的效果是不同的:
4.池化
分为三种:
- 最大池化
- 平均池化
- 随机池化
5.具体例子
LeNET - 5 网络.
注意的是:
- 一个卷积层后边可以更多个池化层,有几个池化层就变成了有几个通道数。
- 第二个卷积层,一个会对前边的某几个池化层求卷积。
- 卷积层可以保持形状不变。当输入数据是图像时,卷积层会以3维数据的形式接收输入数据,并同样以3维数据的形式输出至下一层。因此,在CNN中,可以(有可能)正确理解图像等具有形状的数据
可视化下边的结果
1.是因为用不同的卷积核求的卷积,所以提取出来不一样的特征。
2.第二层的卷积层,一个连接不同个上一个层的池化层。

到了第二个卷积层,人眼已经看不出了是几了,它是抽取了一些更高层次的抽象。
看池化层是只与上边的连接。上边的图称为特征图。
再到下一层,就是全连接层:
下边的也都是全连接的:
10.CNN代码
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
#二维的卷积,二维的池化 Flatten是指把数据扁平化。
from keras.layers import Dense,Dropout,Convolution2D,MaxPool2D,Flatten #导入Dropt
from keras.optimizers import SGD,Adam #优化函数;
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (60000,28,28) -> (60000,28,28,1) #最后一个参数是深度,黑白的深度为1,彩色的是3
#将数据转换为四维的格式.
x_train=x_train.reshape(-1,28,28,1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(-1,28,28,1)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#定义模型的顺序
model=Sequential()
#第一个卷积层
model.add(Convolution2D(
input_shape=(28,28,1), #输入平面.后边的卷积层就不需要设置了。
filters=32, #卷积核个数.
kernel_size=5, #卷积窗口大小.
strides=1, #步长.
padding="same", #pading方式 same/valid. pad填充。使用same的话得到的特征图和上面的大小一样。
activation="relu" #激活函数.
))
#第一个池化层
#池化层有多大,可以算一下.14*14
model.add(MaxPool2D(
#输入的形状不需要特别指定了
pool_size=2,
strides=2,
padding='same',
))
#第二个卷积层
#python 的语法,如果顺序和参数默认一样,就可以直接写参数。不用写形参。
model.add(Convolution2D(64,5,strides=1,padding='same',activation='relu'))
#第二个池化层,池化完以后成7*7
model.add(MaxPool2D(2,2,"same"))
#把第二个池化层的输出扁平化为1维
#把 64*7*7 的图像扁平化
#为了和下边的全连接。
model.add(Flatten())
#第一个全连接层
model.add(Dense(1024,activation="relu"))
model.add(Dropout(0.5))
#第二个全连接层
model.add(Dense(10,activation="softmax"))
#定义优化器
#10的-4次方.
adam=Adam(lr=1e-4)
#定义优化器,在训练的过程中计算准确度。
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=["accuracy"])
#训练模型
model.fit(x_train,y_train,batch_size=64,epochs=10)
#评估模型
loss,accuracy=model.evaluate(x_test,y_test)
print("test lost *********",loss)
print("test accuracy***",accuracy)
训练的效果:
11.RNN 和 LSTM
RNN成为循环神经网络,也称递归神经网络。
循环神经网路,在输入的时候,除本次的输入,还会把上次的输入加进去。

越往后,受前边第一个的影响就越小。
2.LSTM
有些时候,比如,小时候妈妈告诉你,你还是从河边捡来的,然后长大后,你是从哪里来的,你还是告诉别人,你是从河边捡来的,这显然是不靠谱的,也就是说,一些错误的信息或者不太重要的信息,应该逐渐的被遗忘,主要是记住那些有用的信息,这个就是 LSTM。

RNN 中是使用 block 代替了原来的神经元,最中间的神经元的激活函数是使用的等价函数,防止信号在传输中逐渐的减弱,其中,输入门和输出门决定了输入输出信号,如果输入门=0,那么,输入信号就没有了,输出门同样的到道理,输入输入门的权重,是从各个地方汇总过来的。

观察下边这个图和最上边这个图的区别。上面的图,会随着网络模型的前行,不断的减弱,到第六个图几乎是没有了,而下边的图,第一个神经元的输入,依然会影响后边第四个和第六个的输出,前边的输出都是屏蔽状态,第四个的输入也是屏蔽状态。
LSTM 网络可以自由的选择输出的位置。
3.代码实现
注意,加一层,是只有输入层和输出层,两层,就会有一个中间层。线性一层的含义
import numpy as np
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
from keras.layers import Dense
from keras.layers.recurrent import SimpleRNN,LSTM,GRU #常见的就这三种
from keras.optimizers import Adam
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
x_train=x_train/255.0
x_test=x_test/255.0
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#定义模型的顺序
#写一个的话是有两层,写两个的话是有3层
model=Sequential()
model.add(SimpleRNN(
units=50, #输出是50
input_shape=(28,28) #输入的形状.
))
#输出层
model.add(Dense(10,activation='softmax'))
#定义优化器
adam=Adam(lr=1e-4)
#使用优化器和 loss函数,在训练的过程中计算精确度
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=["acc"])
model.fit(x_train,y_train,batch_size=64,epochs=10)
loss,accuracy=model.evaluate(x_test,y_test)
print("损失函数*********",loss)
print("精确度**********",accuracy)
输出结果:
12. 模型保存载入
1.模型的保存
模型的保存非常简单,只需要一行代码就可以:
model.save('../Model/model.h5')
一般默认的是保存成h5的格式,也可以只保存权重。
注意的是文件路径的写法:
- 在Python3中,一般用 / 表示相对路径,
- 用 \ 表示绝对路径/ 的前边,有没有. 和有几个. 的含义是完全不同的
- “/”:表示根目录,在windows系统下表示某个盘的根目录,如“E:\”;
- “./”:表示当前目录;(表示当前目录时,也可以去掉“./”,直接写文件名或者下级目录)
- “../”:两个点表示上级目录。
2.载入模型
模型载入,直接在 mode= 的这一步把模型加载进来。
加载的模型也可以转成 json 的格式,打印出来看看。
载入的模型也可以继续进行训练。
代码如下:
import numpy as np
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD #优化函数;
from keras.models import load_model
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
# (6000,28,28) -> (6000,784)
x_train=x_train.reshape(x_train.shape[0],-1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(x_test.shape[0],784)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#载入模型
model=load_model("model.h5")
#载入的模型是已经训练好的,直接进行评估就行。
loss,accuracy=model.evaluate(x_test,y_test)
print(loss)
print(accuracy)
#把模型转成json格式,打印出来看一下;
json_string=model.to_json()
print(json_string)
#对于载入的模型,可以继续进行训练;
model.fit(x_train,y_train,batch_size=64,epochs=2)
loss,accuracy=model.evaluate(x_test,y_test)
print(loss)
print(accuracy)
13.绘制网络结构
将网络结构绘制出来:
绘制的时候,不需要进行训练,只需要把网络结构的代码加进去就行。
我没调出来。
让网络结构可视化,有很多的方法。可以用比较好看的方法,放到论文中。
代码:
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
#二维的卷积,二维的池化 Flatten是指把数据扁平化。
from keras.layers import Dense,Dropout,Convolution2D,MaxPool2D,Flatten #导入Dropt
from keras.optimizers import SGD,Adam #优化函数;
#绘制网络结构需要安装的包。
import matplotlib.pyplot as plt #专门画图的包
import pydot
import graphviz
from keras.utils.vis_utils import plot_model#自带的绘图的包
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (60000,28,28) -> (60000,28,28,1) #最后一个参数是深度,黑白的深度为1,彩色的是3
#将数据转换为四维的格式.
x_train=x_train.reshape(-1,28,28,1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(-1,28,28,1)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#定义模型的顺序
model=Sequential()
#第一个卷积层
model.add(Convolution2D(
input_shape=(28,28,1), #输入平面.后边的卷积层就不需要设置了。
filters=32, #卷积核个数.
kernel_size=5, #卷积窗口大小.
strides=1, #步长.
padding="same", #pading方式 same/valid. pad填充。使用same的话得到的特征图和上面的大小一样。
activation="relu" #激活函数.
))
#第一个池化层
#池化层有多大,可以算一下.14*14
model.add(MaxPool2D(
#输入的形状不需要特别指定了
pool_size=2,
strides=2,
padding='same',
))
#第二个卷积层
#python 的语法,如果顺序和参数默认一样,就可以直接写参数。不用写形参。
model.add(Convolution2D(64,5,strides=1,padding='same',activation='relu'))
#第二个池化层,池化完以后成7*7
model.add(MaxPool2D(2,2,"same"))
#把第二个池化层的输出扁平化为1维
#把 64*7*7 的图像扁平化
#为了和下边的全连接。
model.add(Flatten())
#第一个全连接层
model.add(Dense(1000,activation="relu"))
model.add(Dropout(0.5))
#第二个全连接层
model.add(Dense(10,activation="softmax"))
#只需要有网络结构就可以,不需要进行训练。
#绘制网络结构
plot_model(model,to_file="model.png",show_shapes=True,show_layer_names='False',rankdir='TB')
plt.figure(figsize=(10,10))
img=plt.imread("model.png")
plt.imshow(img)
plt.axis('off')
plt.show()
gitee 源码:
https://gitee.com/rush_peng/KerasSouxie.git
参考文献:
[1] https://www.bilibili.com/video/BV1Bp4y1D7YL/?p=6
[2]https://www.cnblogs.com/wuliytTaotao/p/9338259.html
keras 入门 (一)的更多相关文章
- Keras入门(四)之利用CNN模型轻松破解网站验证码
项目简介 在之前的文章keras入门(三)搭建CNN模型破解网站验证码中,笔者介绍介绍了如何用Keras来搭建CNN模型来破解网站的验证码,其中验证码含有字母和数字. 让我们一起回顾一下那篇文 ...
- keras 入门整理 如何shuffle,如何使用fit_generator 整理合集
keras入门参考网址: 中文文档教你快速建立model keras不同的模块-基本结构的简介-类似xmind整理 Keras的基本使用(1)--创建,编译,训练模型 Keras学习笔记(完结) ke ...
- Keras入门(二)模型的保存、读取及加载
本文将会介绍如何利用Keras来实现模型的保存.读取以及加载. 本文使用的模型为解决IRIS数据集的多分类问题而设计的深度神经网络(DNN)模型,模型的结构示意图如下: 具体的模型参数可以参考文章 ...
- Keras入门(一)搭建深度神经网络(DNN)解决多分类问题
Keras介绍 Keras是一个开源的高层神经网络API,由纯Python编写而成,其后端可以基于Tensorflow.Theano.MXNet以及CNTK.Keras 为支持快速实验而生,能够把 ...
- Keras入门(六)模型训练实时可视化
在北京做某个项目的时候,客户要求能够对数据进行训练.预测,同时能导出模型,还有在页面上显示训练的进度.前面的几个要求都不难实现,但在页面上显示训练进度当时笔者并没有实现. 本文将会分享如何在K ...
- 数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST
简介 在上一篇博客:数据挖掘入门系列教程(十点五)之DNN介绍及公式推导中,详细的介绍了DNN,并对其进行了公式推导.本来这篇博客是准备直接介绍CNN的,但是想了一下,觉得还是使用keras构建一个D ...
- keras 入门之 regression
本实验分三步: 1. 建立数据集 2. 建立网络并训练 3. 可视化 import numpy as np from keras.models import Sequential from keras ...
- 深度学习:Keras入门(一)之基础篇
1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深度学习框架. Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结 ...
- 深度学习:Keras入门(二)之卷积神经网络(CNN)
说明:这篇文章需要有一些相关的基础知识,否则看起来可能比较吃力. 1.卷积与神经元 1.1 什么是卷积? 简单来说,卷积(或内积)就是一种先把对应位置相乘然后再把结果相加的运算.(具体含义或者数学公式 ...
- keras入门(三)搭建CNN模型破解网站验证码
项目介绍 在文章CNN大战验证码中,我们利用TensorFlow搭建了简单的CNN模型来破解某个网站的验证码.验证码如下: 在本文中,我们将会用Keras来搭建一个稍微复杂的CNN模型来破解以上的 ...
随机推荐
- uniapp- UTS 插件鸿蒙端开发示例 虽然我们这个示例简单 但是这个是难住很多人的一大步
UTS 插件鸿蒙端开发示例 以上示例已开源 项目地址 请参考 示例代码. 前言 虽然这个 UTS 插件鸿蒙端的示例看起来很简单,但说实话,这一步其实难住了不少开发者.很多人第一次做 UTS 插件,尤其 ...
- HarmonyOS NEXT仓颉开发语言实战案例:银行App
仓颉语言的商城项目基本开发结束啦,今天跟大家分享新的项目,一个银行app,说是新项目但是大家可能会有些眼熟,在ArkTS的教程中就写过这个项目.今天我们仓颉语言再写一遍,看看和ArkTS有什么不同. ...
- MySQL数据库连接时区问题
<!-- 组件扫描--> <context:component-scan base-package="com"></context:component ...
- cmd命令行下怎么禁用和启用网络
https://jingyan.baidu.com/article/d3b74d64b293525e76e6092a.html 执行netsh命令. interface show interface ...
- tiptap中文文档
我写的,如果有什么问题 暂时在这里评论就行 我去改 https://tiptap.site 没钱买域名了,tiptap中文网挂到我二级域名下了 https://tiptap.dingshaohua.c ...
- python print 输出重定向
简介 print 重定向的功能,很实用,记录一下 参考链接 https://www.cnblogs.com/marsggbo/p/10293484.html code import sys impor ...
- ETL快速拉取物流信息
我国作为世界第一的物流大国,但是在目前的物流信息系统还存在着几大的痛点.主要包括以下几个方面: 数据孤岛:有些物流企业各个部门之间的数据标准不一致,难以实现数据共享和协同,容易导致信息孤岛. 操作繁琐 ...
- 如何在Linux中更改默认的MySQL / MariaDB端口
在本指南中,我们将学习如何更改MySQL / MariaDB数据库在CentOS 7和基于Debian的Linux发行版中绑定的默认端口. MySQL数据库服务器在Linux和Unix下运行的默认端口 ...
- [ABC #274 F]Fishing
\(1\) 题目翻译 有 \(n\) 条鱼在数轴上移动. 第 \(i\) 条鱼在时刻 \(0\) 时在位置 \(x_i\) 处,价值为 \(w_i\),将会以每时刻 \(t_i\) 的速度向数轴正方向 ...
- mysql连接数,druid的连接数
my.ini // 注册数据库驱动 Class.forName(driver); DriverManager.getConnection(url, user, password); 按max_con ...