Python 学习记录 (4)
Plotly常见可视化方案:以鸢尾花数据为例
简单介绍:
- Ploty库也有大量统计可视化方案,并且这些可视化方案具有交互化属性。
- 主要对鸢尾花数据进行处理与可视化。
- 所展示的结果为交互界面的截图情况,这里不能进行交互。
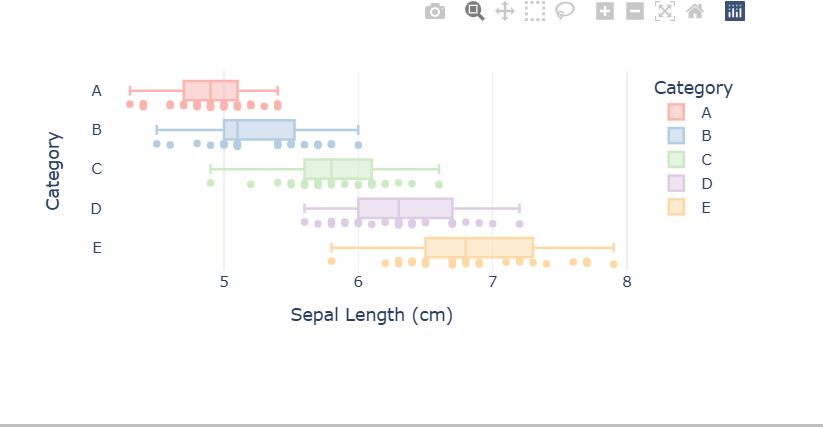
使用Plotly绘制散点图与箱型图,分类展示“花萼宽度”
说明:
- 类似'species'这个分类标签,使用'Category'分析原始特征数据,如花萼宽带
import seaborn as sns
import pandas as pd
import plotly.express as px
df=sns.load_dataset("iris")
df['area']=df['sepal_length']*df['petal_width']
#计算”面积”,其中‘area'为新产生的一列
df['Category']=pd.qcut(df['area'],5,labels=['A','B','C','D','E'])
#pandas.qcut()方法根据’area'大小将数据大致分成5分=份且编号。
list_stats=['min','max','mean','median','std']
stats_by_area=df.groupby('Category')['area'].agg(list_stats)
#这里以Category为参照进行分组,之后对area进行计算统计量
stats_by_area['Range']=stats_by_area['max']-stats_by_area['min']
stats_by_area['Nunber']=df['Category'].value_counts()
#通过个方法相应的数值
#---画出箱型图----
fig = px.box(df,x = 'sepal_length',y = 'Category',
color = 'Category',points='all',
#color指定以什么来区分颜色,points来指明是否画点
template="plotly_white",width=600,height=300,
category_orders={"Category":["A","B","C","D","E"]},
color_discrete_sequence=px.colors.qualitative.Pastel1,
#指定颜色映射的调色板
labels={"sepal_length":"Sepal Length (cm)"})
fig.show()
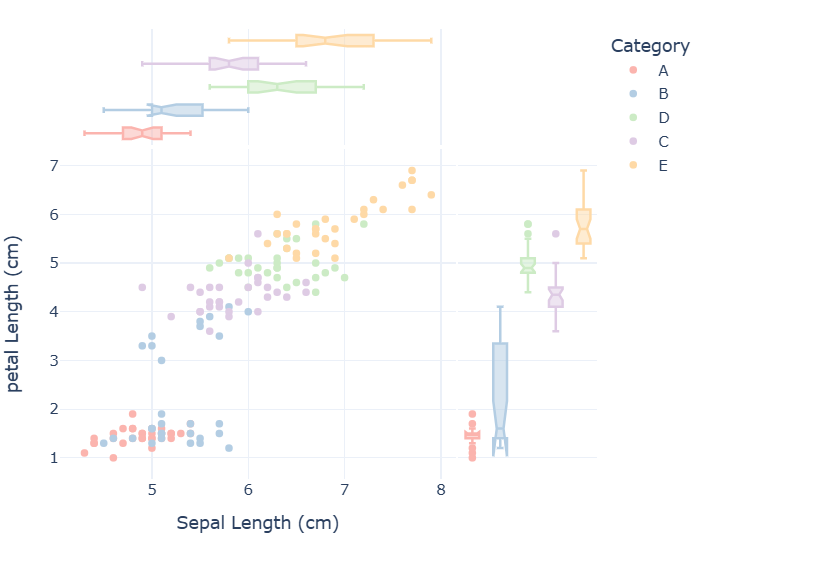
#---画出散点图-----
fig=px.scatter(df,x='sepal_length',y='petal_length',color='Category',
marginal_x='box', marginal_y='box',
#分别在x,y轴的边缘加上箱型图
template="plotly_white",width=600,height=500,
color_discrete_sequence=px.colors.qualitative.Pastel1,
labels={"sepal_length":"Sepal Length (cm)",
"petal_length":"petal Length (cm)"})
fig.show()
结果:
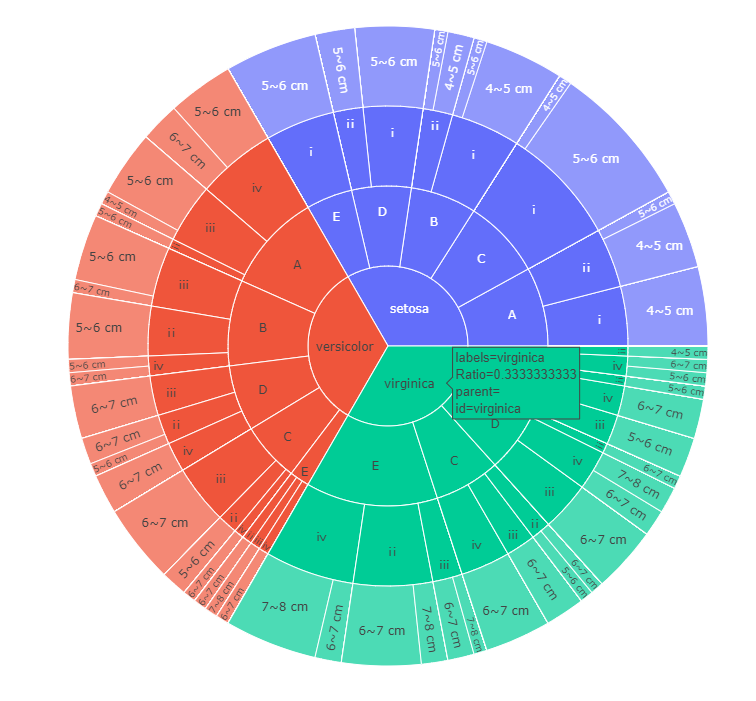
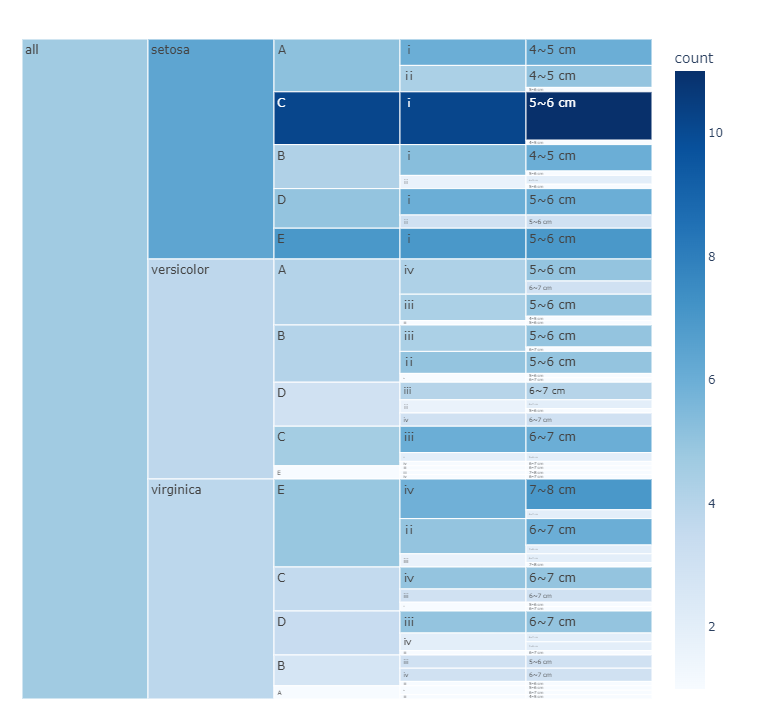
以鸢尾花种类,面积,长度范围,长宽比值为四个维度,并用太阳爆炸,冰柱图,矩形树状图可视化钻取
说明:
- 因原始数据没有相关的维度,故需要添加相关的维度
- 确定一下钻取顺序情况
- 对其进行可视化
import pandas as pd
import seaborn as sns
import plotly.express as px
#---传入数据并对数据进行加工----
df=sns.load_dataset("iris")
df['area']=df['sepal_length']*df['sepal_width']
df['Category']=pd.qcut(df['area'],5,labels=['A','B','C','D','E'])
#上面得到面积,这里根据面积来将数据划分成五等分
labels=["{0}~{1} cm".format(i,i+1) for i in range(4,8)]
#这里将长度也分成四分,为4~5,5~6,下面的right表明右开。
df["sepal_length_bins"]=pd.cut(df.sepal_length,range(4,9),right=False,labels=labels)
df['bi']=df['sepal_length']/df['sepal_width']
#以长宽作为依据划分label为每一区域的标签
df['Category1']=pd.qcut(df['bi'],4,labels=['ⅰ','ⅱ','ⅲ','ⅳ'])
dims=['species','Category','Category1','sepal_length_bins']#钻取顺序,为日冕图做准备
#下面以sepal_length为数值来源得到概率
prob_matrix_by_4=df.groupby(dims)['sepal_length'].apply(lambda x:x.count()/len(df))
prob_matrix_by_4=prob_matrix_by_4.reset_index()
prob_matrix_by_4.rename(columns={'sepal_length':'Ratio'},inplace=True)
#画出日冕图像
fig=px.sunburst(prob_matrix_by_4,path=dims,
values='Ratio',width=800,height=800)
fig.show()
#通过pd.crosstab方法进行交叉计数,这里列最好为一层,方便后面转化长格式后对count的计数
count_matrix=pd.crosstab(index=[df.species,df.Category,df.Category1],
columns=df.sepal_length_bins,values=df.petal_length,aggfunc='count')
count_matrix=count_matrix.stack().reset_index()
count_matrix.rename(columns={0:'count'},inplace=True)
count_matrix=count_matrix[count_matrix['count']!=0]
#只保留不为0的,冰柱图面对0会报错。
fig=px.icicle(count_matrix,
path=[px.Constant("all"),#在最左侧加入all.
'species','Category','Category1','sepal_length_bins'],
values='count',color_continuous_scale='Blues',
color='count',width=800,height=800)
fig.show()
#---画出矩形树状图----
fig=px.treemap(count_matrix,
path=[px.Constant("all"),
'species','Category','Category1','sepal_length_bins'],
values='count',color_continuous_scale='Blues',
color='count',width=800,height=800)
fig.show()
结果:
日冕图:
冰柱图:
矩形树状图:

Python 学习记录 (4)的更多相关文章
- Python学习记录day6
title: Python学习记录day6 tags: python author: Chinge Yang date: 2016-12-03 --- Python学习记录day6 @(学习)[pyt ...
- Python学习记录day5
title: Python学习记录day5 tags: python author: Chinge Yang date: 2016-11-26 --- 1.多层装饰器 多层装饰器的原理是,装饰器装饰函 ...
- Python学习记录day8
目录 Python学习记录day8 1. 静态方法 2. 类方法 3. 属性方法 4. 类的特殊成员方法 4.1 __doc__表示类的描述信息 4.2 __module__ 和 __class__ ...
- Python学习记录day7
目录 Python学习记录day7 1. 面向过程 VS 面向对象 编程范式 2. 面向对象特性 3. 类的定义.构造函数和公有属性 4. 类的析构函数 5. 类的继承 6. 经典类vs新式类 7. ...
- Python学习记录:括号配对检测问题
Python学习记录:括号配对检测问题 一.问题描述 在练习Python程序题的时候,我遇到了括号配对检测问题. 问题描述:提示用户输入一行字符串,其中可能包括小括号 (),请检查小括号是否配对正确, ...
- 实验楼Python学习记录_挑战字符串操作
自我学习记录 Python3 挑战实验 -- 字符串操作 目标 在/home/shiyanlou/Code创建一个 名为 FindDigits.py 的Python 脚本,请读取一串字符串并且把其中所 ...
- 我的Python学习记录
Python日期时间处理:time模块.datetime模块 Python提供了两个标准日期时间处理模块:--time.datetime模块. 那么,这两个模块的功能有什么相同和共同之处呢? 一般来说 ...
- Python 学习记录
记录一些 学习python 的过程 -------------------------------------- 1. 初始学习 @2013年10月6日 今天开始学习python 了 遇到好多困难但是 ...
- python学习记录_IPython基础,Tab自动完成,内省,%run命令_
这是我第一次写博客,之前也有很多想法,想把自己所接触的,以文本的形式储存,总是没有及时行动.此次下定决心,想把自己所学,所遇到的问题做个记录共享给诸位,与此同时自己作为备忘,感谢各位访问我的博 ...
- Python学习记录----数据定义
摘要: 描述Python中数据定义格式,需要注意的东东. 一 数据声明 Python木有一般语言的具体数据类型,像char,int,string这些通通木有.这有点像javascript,但又不同,j ...
随机推荐
- python脚本之requests库上传文件
一.前言 在学习的时候,发现有一个AWD的文件上传执行漏洞,突然想着批量对不同靶机进行操作并get_flag.思路简单,但是没构造 过文件上传的requests 的post请求的payload.便记录 ...
- EF Core – Many to Many
前言 Many to many 是 EF Core 5.0 才开始有的, 以前都用 2 个 1-n 来实现的. 由于它比 1-n 复杂, 所以有必要写一遍来记入一下. 参考: Relationship ...
- 学好QT框架之后可以做什么工作?QT技术框架现代化行业大型复杂应用的经典成功案例
简介 本文粗略的介绍了QT框架的软件开发技术生态体系的全球影响力:QT框架在文字办公领域.CAD三维图形领域.Linux操作系统领域.物联网领域.汽车电子领域以及数字医疗领域等现代化行业的大型复杂应用 ...
- AtCoder Regular Contest 182(A B C)
原来第二题比第一题简单吗 A.Chmax Rush! \(\texttt{Diff 1110}\) 给定三个序列 \(S,P,V\),其中 \(S\) 的长度为 \(N\),\(P,V\) 的长度为 ...
- 【赵渝强老师】Redis的消息发布与订阅
Redis 作为一个publish/subscribe server,起到了消息路由的功能.订阅者可以通过subscribe和psubscribe命令向Redis server订阅自己感兴趣的消息类型 ...
- 五,MyBatis-Plus 当中的 “ActiveRecord模式”和“SimpleQuery工具类”(详细实操)
五,MyBatis-Plus 当中的 "ActiveRecord模式"和"SimpleQuery工具类"(详细实操) @ 目录 五,MyBatis-Plus 当 ...
- ByConity与主流开源OLAP引擎(Clickhouse、Doris、Presto)性能对比分析
引言: 随着数据量和数据复杂性的不断增加,越来越多的企业开始使用OLAP(联机分析处理)引擎来处理大规模数据并提供即时分析结果.在选择OLAP引擎时,性能是一个非常重要的因素. 因此,本文将使用TPC ...
- DOM 操作的常用 API 有哪些 ?
DOM 操作的常用 API 就是DOM 通过API (接口)获取页面(html)元素: 1. 节点查询 API 1.1 document.querySelector() 选择第一个匹配的元素 1.2 ...
- markdown.css 设置文章的样式
返回的详情文章内容是标签加内容文字,使用 markdown,css 渲染样式 : .markdown-body .octicon { display: inline-block; fill: curr ...
- day15-三大基本结构
顺序结构 Java的基本结构就是顺序结构,除非特别指明,否则就按照顺序一句一句执行. 顺序结构是最简单的算法结构. 语句和语句之间,框与框之间是按从上到下的顺序进行的,它是由若干个依次执行的处理步骤组 ...