SkipList理解
记下自己对跳表SkipList的理解。
SkipList采用空间换时间的思想,通过增加数据间的链接,达到加快查找速度的目的。
数据库LevelDB和RocksDB中用到了SkipList,Redis中的有序set即zset也用到了SkipList。Java中也提供了ConcurrentSkipListMap,在并发量大的情况下,ConcurrentSkipListMap性能好。
先看SkipList的查找过程,引用网上的经典图片,查找19。注意的是数据是有序的。
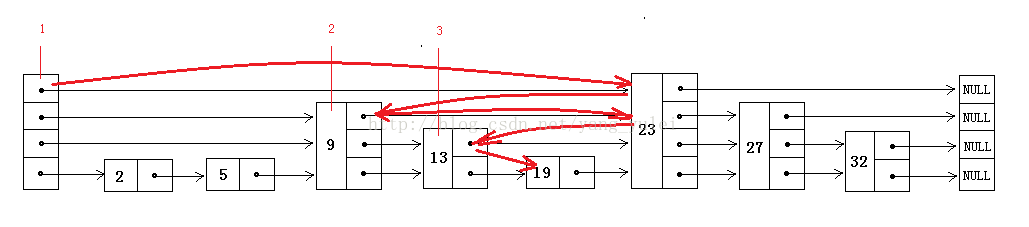
查找的过程从上至下,查找指针所经历的位置顺序如图中的1,2,3,直到找到目标数据19。
再加一张图,是怎么二分法查找的。

SkipList中创建新结点时,产生一个在1~MAX_LEVEL之间的随机level值作为该结点的level。每个节点的高度是随机的。
MAX_LEVEL可以静态指定,也可以动态增长。
关于MAX_LEVEL,觉得这篇文章的解释是比较清楚的:https://blog.csdn.net/kisimple/article/details/38706729。下面是复制了部分的内容
每个节点所能reach到的最远的节点是随机的,正如作者所说,SkipList使用的是概率平衡而不是强制平衡。
O(logN)?
既然是随机算法,那怎么能保证O(logN)的复杂度?SkipList作者在论文中有给出了说明,这里从另一个角度说下我的理解。先定义一下,A node that has k forward pointers is called a level k node。假设k层节点的数量是k+1层节点的P倍,那么其实这个SkipList可以看成是一棵平衡的P叉树,从最顶层开始查找某个节点需要的时间是O(logpN),which is O(logN) when p is a constant。
下面看下Redis与LevelDB中实现SkipList所使用的随机算法。
Redis
在t_zset.c中找到了redis使用的随机算法。
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = ;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += ;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
执行level += 1;的概率为ZSKIPLIST_P,也就是说k层节点的数量是k+1层节点的1/ZSKIPLIST_P倍。ZSKIPLIST_P(这个P是作者论文中的p)与ZSKIPLIST_MAXLEVEL在redis.h中定义,
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
所以redis中的SkipList相当于是一棵四叉树。
LevelDB
在skiplist.h中找到了LevelDB使用的随机算法。
template<typename Key, class Comparator>
int SkipList<Key,Comparator>::RandomHeight() {
// Increase height with probability 1 in kBranching
static const unsigned int kBranching = ;
int height = ;
while (height < kMaxHeight && ((rnd_.Next() % kBranching) == )) {
height++;
}
assert(height > );
assert(height <= kMaxHeight);
return height;
}
(rnd_.Next() % kBranching) == 0)的概率为1/kBranching,所以LevelDB中的SkipList也是一棵四叉树(kBranching = 4;不就是这个意思吗^_^)。
SkipList理解的更多相关文章
- 深入理解Redis:底层数据结构
简介 redis[1]是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorte ...
- 浅析SkipList跳跃表原理及代码实现
本文将总结一种数据结构:跳跃表.前半部分跳跃表性质和操作的介绍直接摘自<让算法的效率跳起来--浅谈“跳跃表”的相关操作及其应用>上海市华东师范大学第二附属中学 魏冉.之后将附上跳跃表的源代 ...
- skiplist 跳表(2)-----细心学习
快速了解skiplist请看:skiplist 跳表(1) http://blog.sina.com.cn/s/blog_693f08470101n2lv.html 本周我要介绍的数据结构,是我非常非 ...
- redis skiplist (跳跃表)
redis skiplist (跳跃表) 概述 redis skiplist 是有序的, 按照分值大小排序 节点中存储多个指向其他节点的指针 结构 zskiplist 结构 // 跳跃表 typede ...
- 深夜学算法之SkipList:让链表飞
1. 前言 上次写Python操作LevelDB时提到过,有机会要实现下SkipList.摘录下wiki介绍: 跳跃列表是一种随机化数据结构,基于并联的链表,其效率可比拟二叉查找树. 我们知道对于有序 ...
- Redis数据结构之skiplist(续)
本文摘抄于<Redis内部数据结构详解-skiplist> 一.skiplist的由来 skiplist,顾名思义,首先它是一个list.实际上,它是在有序链表的基础上发展起来的. 我们先 ...
- leveldb学习:skiplist
leveldb中的memtable仅仅是一个封装类,它的底层实现是一个跳表. 跳表是一种基于随机数的平衡数据结构.其它的平衡数据结构还有红黑树.AVL树.但跳表的原理比它们简单非常多.跳表有点像链表, ...
- 深入理解跳表在Redis中的应用
本文首发于:深入理解跳表在Redis中的应用微信公众号:后端技术指南针持续输出干货 欢迎关注 前面写了一篇关于跳表基本原理和特性的文章,本次继续介绍跳表的概率平衡和工程实现, 跳表在Redis.Lev ...
- 深入理解跳跃链表在Redis中的应用
0.前言 前面写了一篇关于跳表基本原理和特性的文章,本次继续介绍跳表的概率平衡和工程实现,跳表在Redis.LevelDB.ES中都有应用,本文以Redis为工程蓝本,分析跳表在Redis中的工程实现 ...
随机推荐
- 实验吧—隐写术——WP之 Fair-Play
首先,我们读题发现题目是Playfair,其实我也不知道这是什么,那么就百度一下啊 Playfair解密算法: 首先将密钥填写在一个5*5的矩阵中(去Q留Z),矩阵中其它未用到的字母按顺序填在矩阵剩 ...
- js---通配符选择器
原味转自:http://blog.sina.com.cn/s/blog_6e001be701017kaz.html 1.选择器 (1)通配符: $("input[id^='code']&qu ...
- 你不知道的JavaScript(下卷) (Kyle Simpson 著)
第一部分 起步上路 第1章 深入编程 1.1 代码 1.2 表达式 1.3 实践 1.3.1 输出 1.3.2 输入 1.4 运算符 1.5 值与类型 1.6 代码注释 1.7 变量 1.8 块 1. ...
- Fedora Redhat Centos 有什么区别和关系?
Fedora Redhat Centos 有什么区别和关系? 经常看到有人讨论服务器的操作系统,比如 Readhat 和 Centos,还有 Ubuntu Server. 可能 Ubuntu Serv ...
- 20165308 预备作业3 Linux安装及学习
Linux安装及学习 Linux的安装 因为做的比较晚, 安装过程按照老师给出的步骤和同学指导并未出现很多问题,只是安装VirtualBox虚拟机增强功能时,代码没输正确,结果一直无法正确安装,后来也 ...
- Databinding in WPF
https://www.codeproject.com/Articles/680271/Simplest-MVVM-Ever
- Chrome 66 禁止声音自动播放
声音无法自动播放一直在IOS/Android上面都是一个惯例, 桌面端的 Safari在2017年的11版本中也宣布禁止带有声音的多媒体自动播放, 紧接着2018年4月份Chrome发布的66版本也正 ...
- centos7数据库连接使用127.0.0.1报permission denied,使用localhost报No such file or directory
安装lamp环境后,测试数据库连接. 当host使用127.0.0.1时,报错:(HY000/2002): Permission denied. 把host换成localhost后,又报错:SQLST ...
- Zookeeper Ha集群简介+jdbcClient访问Ha集群环境
Hadoop-HA机制HA概述high available(高可用) 所谓HA(high available),即高可用(7*24小时不中断服务). 实现高可用最关键的策略是消除单点故障.HA严格来说 ...
- RedHat6.5安装kafka集群
版本号: Redhat6.5 JDK1.8 zookeeper-3.4.6 kafka_2.11-0.8.2.1 1.软件环境 1.3台RedHat机器,master.slave1. ...