Spark 基础之SQL 快速上手
- SQL 基本概念
- SQL Context 的生成和使用
- 1.6 版本新API:Datasets
- 常用 Spark SQL 数学和统计函数
- SQL 语句
- Spark DataFrame 文件保存
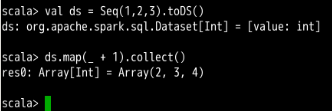
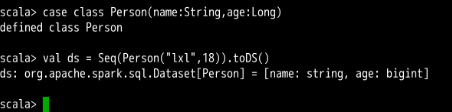
Spark SQL API 中涉及到检索的函数主要有:
select(col: String, cols: String*):该函数基于已有的列名进行查询,返回一个 DataFrame 对象。使用方法如df.select($"colA", $"colB")。select(cols: Column*):该函数可以基于表达式来进行查询,返回一个 DataFrame 对象。使用方法如df.select($"colA", $"colB" + 1)。selectExpr(exprs: String*):该函数的参数可以是一句完整的SQL语句,仍然返回一个 DataFrame 对象。具体的 SQL 语法规则可以参考通用的 SQL 规则。该函数使用方法如df.selectExpr("colA", "colB as newName", "abs(colC)"),当然你也可以进行表达式的组合,如df.select(expr("colA"), expr("colB as newName"), expr("abs(colC)"))。

.png)

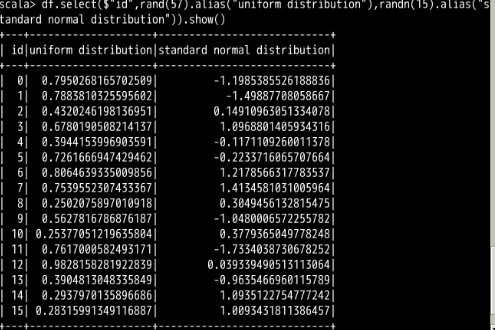

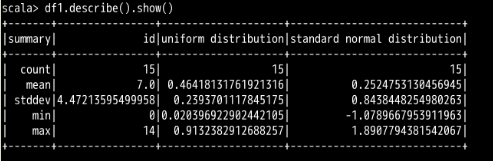
describe() 函数中填入指定的列名即可。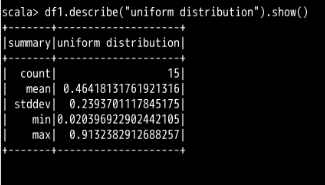
uniform distribution 一列进行了描述性信息的计算。describe() 函数去进行数据分析,我们也可以把这些描述性信息的计算手段用到一个普通的 select 检索过程中。在需要什么信息的时候,就填入相应的计算函数即可,如下面的代码:


data1 列与 data2 列的数据之间的差异较小。id 列尝试一下: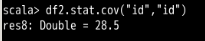


此时两个相同列的相关性肯定就为 1 了。
SparkSQL案例
一、启动spark-shell
二、引包并建立JDBC连接 val url = "jdbc:mysql://vin01:3306/test?user=root&password=123456"
import java.util.Properties
val props = new Properties()

三、创建DataFrame
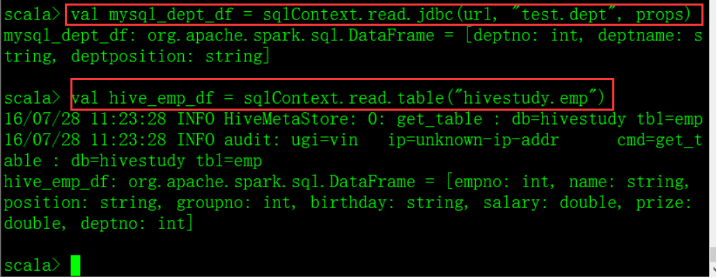
四、jion val join_df = hive_emp_df.join(mysql_dept_df, "deptno")

五、 将jion出来的值注册为临时表,方便查询 join_df.registerTempTable("join_emp_dept")
查询: sqlContext.sql("select empno, ename, deptno, deptname, sal from join_emp_dept order by empno").show 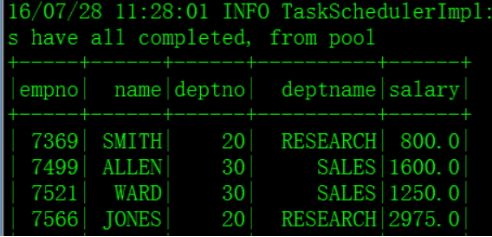
Spark 基础之SQL 快速上手的更多相关文章
- Spark 安装部署与快速上手
Spark 介绍 核心概念 Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别. 最大的优化是让计算任务的中间结果可以存储在内存中, ...
- LINQ to SQL快速上手 step by step
Step1:建立数据库 在使用Linq to Sql前,我们要将相应的数据库建好.在这个Demo中,使用的数据库是SQL Server Express 2005. 我们首先建立一个 ...
- Gradle快速上手——从Maven到Gradle
[本文写作于2018年7月5日] 本文适合于有一定Maven应用基础,想快速上手Gradle的读者. 背景 Maven.Gradle都是著名的依赖管理及自动构建工具.提到依赖管理与自动构建,其重要性在 ...
- spark快速上手
spark快速上手 前言 基于Spark 2.1版本 仅仅是快速上手,没有深究细节 主要参考是官方文档 代码均为官方文档中代码,语言为Scala 进入spark-shell 终端输入spark-she ...
- Spark2.x学习笔记:Spark SQL快速入门
Spark SQL快速入门 本地表 (1)准备数据 [root@node1 ~]# mkdir /tmp/data [root@node1 ~]# cat data/ml-1m/users.dat | ...
- React:快速上手(1)——基础知识
React:快速上手(1)——基础知识 React(有时叫React.js或ReactJS)是一个为数据提供渲染为HTML视图的开源JavaScript库,用于构建用户界面. JSX.元素及渲染 1. ...
- 三分钟快速上手TensorFlow 2.0 (上)——前置基础、模型建立与可视化
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 学习笔记类似提纲,具体细节参照上文链接 一些前置的基础 随机数 tf.random uniform(sha ...
- 《Python游戏编程快速上手》|百度网盘免费下载|Python基础编程
<Python游戏编程快速上手>|百度网盘免费下载| 提取码:luy6 Python是一种高级程序设计语言,因其简洁.易读及可扩展性日渐成为程序设计领域备受推崇的语言. 本书通过编写一个个 ...
- CSS快速入门基础篇,让你快速上手(附带代码案例)
1.什么是CSS 学习思路 CSS是什么 怎么去用CSS(快速上手) CSS选择器(难点也是重点) 网页美化(文字,阴影,超链接,列表,渐变等) 盒子模型 浮动 定位 网页动画(特效效果) 项目格式: ...
随机推荐
- 【leetcode】437. Path Sum III
problem 437. Path Sum III 参考 1. Leetcode_437. Path Sum III; 完
- MVC+三层+ASP.NET简单登录验证
通过制作一个登录小案例来搭建MVC简单三层 在View --Shared下创建一个母版页: <!DOCTYPE html> <html> <head> <me ...
- Github Page 搜索工具
轮子 今天造了一个轮子 -- Github Page搜索工具 https://man-ing.com/github. 什么是Github Page 直接从GitHub存储库托管.只需编辑,推送,更改即 ...
- while RE Validation
一.简介 为什么需要正则表达式? 文本的复杂处理 正则表达式的优势和用途? 一种强大而灵活的文本处理工具: 大部分编程语言.数据库.文本编辑器.开发环境都支持正则表达式. 正则表达式定义: 正如它的名 ...
- webpack学习笔记(三)
访问网址: https://github.com/webpack/analyse "scripts": { "dev-build": "webpack ...
- python 【winerror2】系统找不到指定的路径
# _*_ coding:utf-8_*_from selenium import webdriver driver = webdriver.Firefox()driver.get("htt ...
- windows 2008R2系统程序运行提示无法定位程序输入点ucrtbase.terminate
1.用python写了个脚本,打成exe程序,在一些机器上正常运行,再另外一些机器上运行提示 无法定位程序输入点ucrtbase.terminate 应该是缺少库文件支持 2.网上搜了下.https: ...
- 解决Android Studio在Ubuntu上出现“sdk/platform-tools/adb: error=2, No such file or directory”的方法
转载至http://blog.163.com/china_uv/blog/static/11713726720136931132385/ 刚安装Ubuntu14.5时运行Android Studio可 ...
- Java高级特性 第5节 序列化和、反射机制
一.序列化 1.序列化概述 在实际开发中,经常需要将对象的信息保存到磁盘中便于检索,但通过前面输入输出流的方法逐一对对象的属性信息进行操作,很繁琐并容易出错,而序列化提供了轻松解决这个问题的快捷方法. ...
- cmake编译obs
https://blog.csdn.net/su_vast/article/details/74984213 https://blog.csdn.net/u011258240/article/deta ...