NO.5 算法测试(词条统计)
一、安装Eclipse
下载Eclipse,解压安装,例如安装到/usr/local,即/usr/local/eclipse
4.3.1版本下载地址:http://pan.baidu.com/s/1eQkpRgu
如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。

4、配置Map/Reduce Locations
打开Windows—Open Perspective—Other

在右下方看到如下图所示
点击Map/Reduce Location选项卡,点击右边小象图标,打开Hadoop Location配置窗口:
输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。

点击"Finish"按钮,关闭窗口。
点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功

如果如下图所示表示安装失败,请检查Hadoop是否启动,以及eclipse配置是否正确。使用eclipse版本与jdk的版本对应,可以多安装几个jdk,灵活切换调用。

三、新建WordCount项目
File—>Project,选择Map/Reduce Project,输入项目名称WordCount等。
在WordCount项目里新建class,名称为WordCount,代码如下:

2、拷贝本地Test1.txt 到HDFS的input里
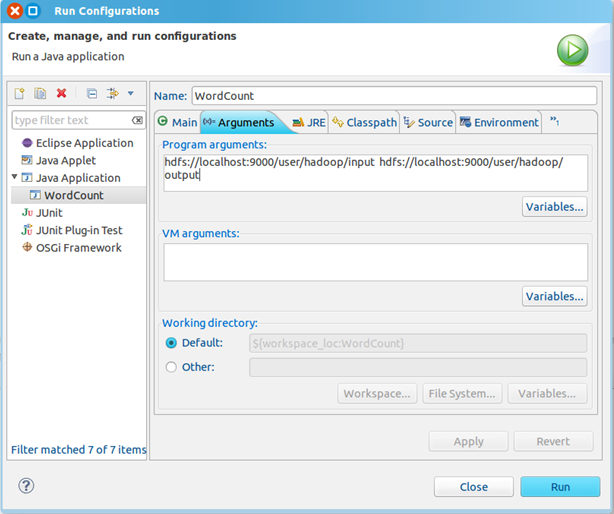
3、点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹
点击Run按钮,运行程序。
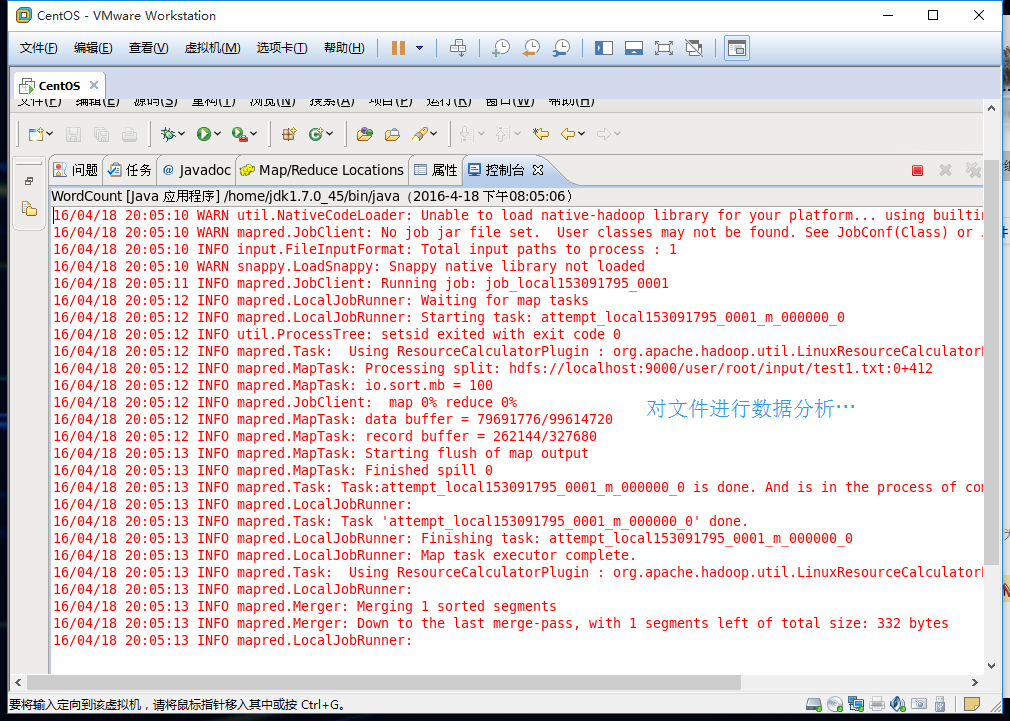

4、运行完成后,查看运行结果
方法2:
展开DFS Locations,如下图所示,双击打开part-r00000查看结果

////////////////////////////////////////////////////////////////////////////
(1)将文件拆分为splits,并由MapReduce框架自动完成分割,将每一个split分割为<key,value>对
(2)每一对<key,value>调用一次map函数,处理后生产新的<key,value>对,由Context传递给reduce处理
(3)Mapper对<key,value>对进行按key值进行排序,并执行Combine过程,将key值相同的value进行合并。最后得到Mapper的最终输出结果
NO.5 算法测试(词条统计)的更多相关文章
- AI算法测评(二)--算法测试流程
根据算法测试过程中遇到的一些问题和管理规范, 梳理出算法测试工作需要关注的一些点: 编号 名称 描述信息 备注 1 明确算法测试需求 明确测试目的 明确测试需求, 确认测试需要的数据及场景 明确算法服 ...
- 交易准实时预警 kafka topic 主题 异常交易主题 低延迟 event topic alert topic 内存 算法测试
https://www.ibm.com/developerworks/cn/opensource/os-cn-kafka/index.html 周 明耀2015 年 6 月 10 日发布 示例:网络游 ...
- Java实现 蓝桥杯VIP 算法提高 分数统计
算法提高 分数统计 时间限制:1.0s 内存限制:512.0MB 问题描述 2016.4.5已更新此题,此前的程序需要重新提交. 问题描述 给定一个百分制成绩T,将其划分为如下五个等级之一: 9010 ...
- AI大厂算法测试心得:人脸识别关键指标有哪些?
仅仅在几年前,程序员要开发一款人脸识别应用,就必须精通算法的编写.但现在,随着成熟算法的对外开放,越来越多开发者只需专注于开发垂直行业的产品即可. 由调查机构发布的<中国AI产业地图研究> ...
- 算法导论-顺序统计-快速求第i小的元素
目录 1.问题的引出-求第i个顺序统计量 2.方法一:以期望线性时间做选择 3.方法二(改进):最坏情况线性时间的选择 4.完整测试代码(c++) 5.参考资料 内容 1.问题的引出-求第i个顺序统计 ...
- 基于JaCoCo的Android测试覆盖率统计(二)
> 本文章是我上一篇文章的升级版本,详见地址:https://www.cnblogs.com/xiaoluosun/p/7234606.html ## 为什么要做这个?1. 辛辛苦苦写了几百条测 ...
- 08.手写KNN算法测试
导入库 import numpy as np from sklearn import datasets import matplotlib.pyplot as plt 导入数据 iris = data ...
- 计算机算法-C语言-统计字母数字个数解
Question:输入一串以“?”结尾的字符,分别统计其中字母数字的个数,输出字母及数字的个数. Solve: #include<stdio.h> #include<stdlib.h ...
- 算法打基础——顺序统计(找第k小数)
这次主要是讲如何在线性时间下找n个元素的未排序序列中第k小的数.当然如果\(k=1 or k=n\),即找最大最小 数,线性时间内遍历即可完成,当拓展到一般,如中位数时,相关算法就值得研究了.这里还要 ...
随机推荐
- [C程序设计基础]一些常用的系统函数
- 虚幻开放日2017ppt
虚幻开放日2017ppthttp://pan.baidu.com/s/1c1SbcKK 如果挂了QQ+378100977 call我
- tomcat修改端口号
以前只知道当tomcat端口号冲突了如何修改tomcat默认的8080端口号 今天遇到个情况,装了个BO,自带个tomcat,这时就需要修改三个地方 修改Tomcat的端口号: 在默认情况下,tomc ...
- 潭州课堂25班:Ph201805201 django 项目 第十五课 用户注册功能后台实现 (课堂笔记)
前台:判断用户输入 ,确认密码,手机号, 一切通过后向后台发送请求, 请求方式:post 在 suers 应用下的视图中: 1,创建个类, 2,创建 GET 方法,宣言页面 3,创建 POST 方法 ...
- 安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情7. 安装 PHP PHP 是用于 web 基础服务的服务器端脚本语言。它也经常被用作通用编程语言。在最小化安装的 CentOS 中安
CentOS 是一个工业标准的 Linux 发行版,是红帽企业版 Linux 的衍生版本.你安装完后马上就可以使用,但是为了更好地使用你的系统,你需要进行一些升级.安装新的软件包.配置特定服务和应用程 ...
- python 函数递归与匿名函数
1.什么是函数递归? 函数递归调用(是一种特殊的嵌套调用):在调用的函数过程中,又直接或者间接的调用了该函数本身 递归必须要有两个明确的阶段: 递推:一层一层递归调用下去,强调每进入下一层递归问题的规 ...
- bzoj 4459: [Jsoi2013]丢番图 -- 数学
4459: [Jsoi2013]丢番图 Time Limit: 10 Sec Memory Limit: 64 MB Description 丢番图是亚历山大时期埃及著名的数学家.他是最早研究整数系 ...
- hdu1171 Big Event in HDU(多重背包)
http://acm.hdu.edu.cn/showproblem.php?pid=1171 多重背包题目不难,但是有些点不能漏或错. #include<iostream> #includ ...
- windows NT的意义和各个版本
javascript中navigator.userAgent里的window NT今天为了尝试查看网址的来源document.referrer,但是不知道每个浏览器的版本号,然后我就用navigato ...
- JS数字指定长度不足前补零的实现
问题描述: 要求输出的数字长度是固定的,如长度为2,数字为1,则输出01,即不够位数就在之前补足0. 解决方法: 方法1 function fn1(num, length) { ret ...